This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. That is, is giving supervision to adjust via.
Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
Types of Machine Learning Algorithms Machine Learning has become an integral part of modern technology, enabling systems to learn from data and improve over time without explicit programming. The goal is to learn a mapping from inputs to outputs, allowing the model to make predictions on unseen data.
Machine learning types Machine learning algorithms fall into five broad categories: supervisedlearning, unsupervised learning, semi-supervisedlearning, self-supervised and reinforcement learning. the target or outcome variable is known). temperature, salary).
INTRODUCTION Machine Learning is a subfield of artificial intelligence that focuses on the development of algorithms and models that allow computers to learn and make predictions or decisions based on data, without being explicitly programmed. WHAT IS CLUSTERING? Those groups are referred to as clusters.
Multi-class classification in machine learning Multi-class classification in machine learning is a type of supervisedlearning problem where the goal is to predict one of multiple classes or categories based on input features.
This function can be improved by AI and ML, which allow GIS to produce insights, automate procedures, and learn from data. Types of Machine Learning for GIS 1. Supervisedlearning– In supervisedlearning, the input data and associated output labels are paired, letting the system be trained on labelled data.
A non-parametric, supervisedlearning classifier, the K-Nearest Neighbors (k-NN) algorithm uses proximity to classify or predict how a single data point will be grouped. It is among the most widely used and straightforward regression and classification classifiers in machine learning today. What is K Nearest Neighbor?
The answer lies in the various types of Machine Learning, each with its unique approach and application. In this blog, we will explore the four primary types of Machine Learning: SupervisedLearning, UnSupervised Learning, semi-SupervisedLearning, and Reinforcement Learning.
There are various types of machine learning algorithms, including supervisedlearning, unsupervised learning, and reinforcement learning. In supervisedlearning, the model learns from labeled examples, where the input data is paired with corresponding target labels.
R and Machine Learning The field of computer science known as “machine learning” focuses on creating algorithms with learning capabilities. Concept learning, function learning, sometimes known as “predictive modeling,” clustering, and the identification of predictive patterns are typical machine learning tasks.
K-Means Clustering What is K-Means Clustering in Machine Learning? K-Means Clustering is an unsupervised machine learning algorithm used for clustering data points into groups or clusters based on their similarity. How Does K-Means Clustering Work? How is K Determined in K-Means Clustering?
The former is a term used for models where the data has been labeled, whereas, unsupervised learning, on the other hand, refers to unlabeled data. Classification is a form of supervisedlearning technique where a known structure is generalized for distinguishing instances in new data. Clustering. Classification.
Leveraging foundation models for enterprise AI Despite the break-neck progress on the foundation model front with ChatGPT, BARD, GPT-4, LLaMA, and more, the enterprise adoption for predictive AI use cases, e.g. fraud detection, patient risk assessment, document processing automation, and more, remains slow.
We want to, first and foremost, label these documents. Typically, you let the experts read some articles, label them, and then use them as training data and train the supervisedlearning model. To address all these problems, we looked into weak supervisedlearning. But this is not a scalable approach.
We want to, first and foremost, label these documents. Typically, you let the experts read some articles, label them, and then use them as training data and train the supervisedlearning model. To address all these problems, we looked into weak supervisedlearning. But this is not a scalable approach.
It allows you to create and share live code, equations, visualisations, and narrative text documents. Scikit-learn Scikit-learn is the go-to library for Machine Learning in Python. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms.
Recently, I became interested in machine learning, so I was enrolled in the Yandex School of Data Analysis and Computer Science Center. Machine learning is my passion and I often participate in competitions. The semi-supervisedlearning was repeated using the gemma2-9b model as the soft labeling model.
That range originates from pretraining on millions of diverse documents. Data scientists train embedding models on unstructured text through a process called “self-supervisedlearning.” This process clusters words that often appear together closely in the model’s high-dimensional space. The relevant document chunks.
That range originates from pretraining on millions of diverse documents. Data scientists train embedding models on unstructured text through a process called “self-supervisedlearning.” This process clusters words that often appear together closely in the model’s high-dimensional space. The relevant document chunks.
Building on In-House Hardware Conformer-2 was trained on our own GPU compute cluster of 80GB-A100s. To do this, we deployed a fault-tolerant and highly scalable cluster management and job scheduling Slurm scheduler, capable of managing resources in the cluster, recovering from failures, and adding or removing specific nodes.
It includes text documents, social media posts, customer reviews, emails, and more. Here are seven benefits of text mining: Information Extraction Text mining enables the extraction of relevant information from unstructured text sources such as documents, social media posts, customer feedback, and more.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
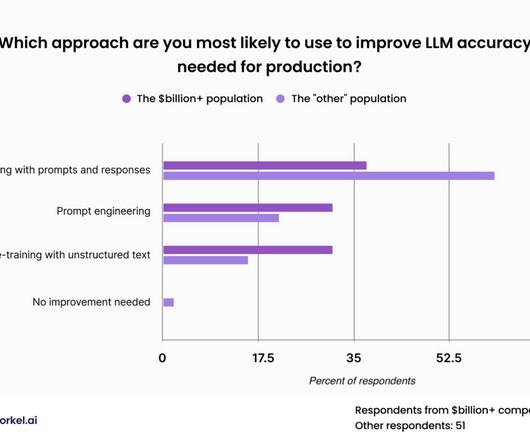
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. Prompt and response analogs could include any dialogue-like written text, such as forum posts, text messages, and FAQ documents.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. LLaMA Meet the latest large language model!
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. LLaMA Meet the latest large language model!
These techniques span different types of learning and provide powerful tools to solve complex real-world problems. SupervisedLearningSupervisedlearning is one of the most common types of Machine Learning, where the algorithm is trained using labelled data.
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. Prompt and response analogs could include any dialogue-like written text, such as forum posts, text messages, and FAQ documents.
2020) Scaling Laws for Neural Language Models [link] First formal study documenting empirical scaling laws Published by OpenAI The Data Quality Conundrum Not all data is created equal. AI model training requires extensive computational resources, with companies investing billions in AI clusters.
You’ll collect more user actions, giving you lots of smaller pieces to learn from, and a much tighter feedback loop between the human and the model. However, the unsupervised algorithm won’t usually return clusters that map neatly to the labels you care about. s new text classification system (currently in alpha). 50% 0.82 +0.09
Boosting: An ensemble learning technique that combines multiple weak models to create a strong predictive model. C Classification: A supervised Machine Learning task that assigns data points to predefined categories or classes based on their characteristics.
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. Prompt and response analogs could include any dialogue-like written text, such as forum posts, text messages, and FAQ documents.
Optimized Expert Time Active Learning ensures expert time is spent on cases where their expertise adds the most value. Suitable for offline learning scenarios because in pool-based active a large pool of unlabeled data is provided. These applications uses large pool of unlabeled dataset.
Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs. These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines.
Accordingly, it is possible for the Python users to ask for help from Stack Overflow, mailing lists and user-contributed code and documentation. Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow.
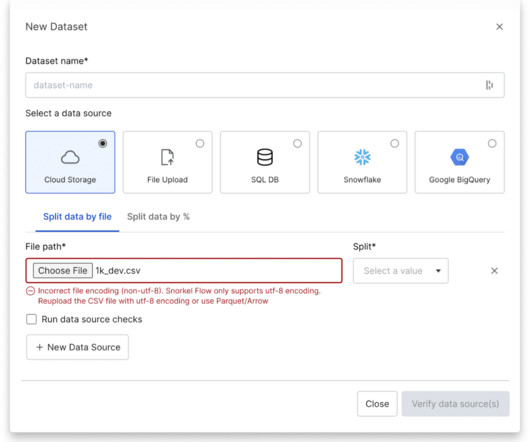
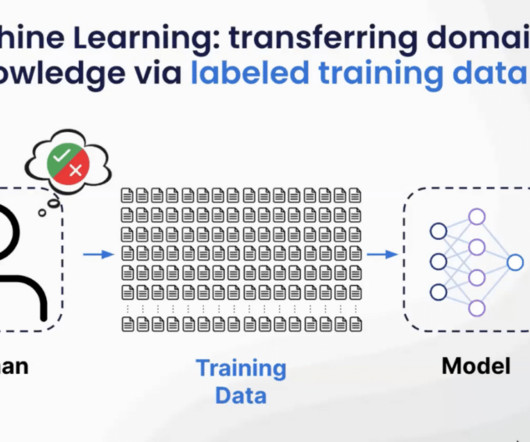
That makes data labeling a foundational requirement for any supervised machine learning application—which describes the vast majority of ML projects. This process takes raw documents, files, or tabular records and adds one or more tags or labels to each. This approach applies across all data modalities.
Deep Learning is a subset of ML. Supervised vs Unsupervised LearningSupervisedlearning involves training algorithms on labelled data where the correct output is known. Unsupervised learning focuses on uncovering hidden patterns in unlabeled data.
You should use two tags of history, and features derived from the Brown word clusters distributed here. 26s Both Pattern and NLTK are very robust and beautifully well documented, so the appeal of using them is obvious. Averaged Perceptron POS tagging is a “supervisedlearning problem”. 3m56s Pattern 93.5%
The model then uses a clustering algorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
Semi-supervisedlearning is reshaping the landscape of machine learning by bridging the gap between supervised and unsupervised methods. With vast amounts of unlabeled data available in various domains, semi-supervisedlearning proves to be an invaluable tool in tackling complex classification tasks.
Xuechen Li, Daogao Liu, Tatsunori Hashimoto, Huseyin A Inan, Janardhan Kulkarni, YinTat Lee, Abhradeep Guha Thakurta End-to-End Learning to Index and Search in Large Output Spaces Nilesh Gupta, Patrick H.
Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. You can read this article to learn how to choose a data labeling tool. Leveraging Unlabeled Image Data With Self-SupervisedLearning or Pseudo Labeling With Mateusz Opala.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content