This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. These batches are then evenly distributed across the machines in a cluster. format("/".join(tile_prefix),
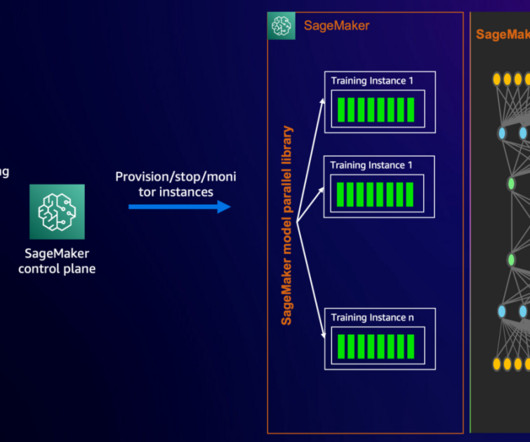
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
To upload the dataset Download the dataset : Go to the Shoe Dataset page on Kaggle.com and download the dataset file (350.79MB) that contains the images. With Amazon OpenSearch Serverless, you don’t need to provision, configure, and tune the instance clusters that store and index your data. b64encode(image_file.read()).decode('utf-8')
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Avrim Blum, John Hopcroft, and Ravindran Kannan wrote the book, Foundations of Data Science (PDF download). It is free and available for download. It covers topics such as: Machine Learning Massive Data Clustering and many more. It can be useful for academic work or in business. See the video for more.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
All of these techniques center around product clustering, where product lines or SKUs that are “closer” or more similar to each other are clustered and modeled together. Clustering by product group. The most intuitive way of clustering SKUs is by their product group. Clustering by sales profile.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. As part of a single cluster run, you can spin up a cluster of Trn1 instances with Trainium accelerators. Trn1 UltraClusters can host up to 30,000 Trainium devices and deliver up to 6 exaflops of compute in a single cluster.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
Downloading YouTube Comments via Python API: The project starts by extracting comments from YouTube videos related to this specific movie. They are pretty straightforward, you can find the full documentation at this link: First of all we want to download the comments related to a video talking about a specific movie.
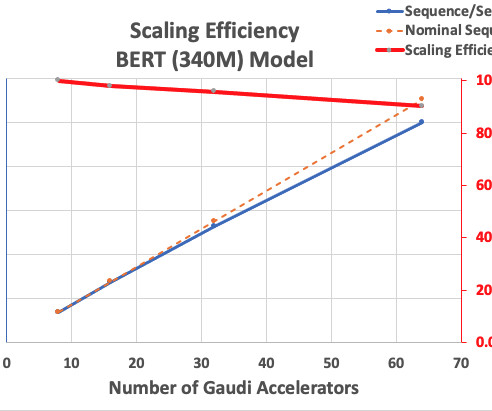
Distributed model training requires a cluster of worker nodes that can scale. The following scaling chart shows that the p5.48xlarge instances offer 87% scaling efficiency with FSDP Llama2 fine-tuning in a 16-node cluster configuration. The example will also work with a pre-existing EKS cluster. Cluster with p4de.24xlarge
Install Java and Download Kafka: Install Java on the EC2 instance and download the Kafka binary: 4. It communicates with the Cluster Manager to allocate resources and oversee task progress. SparkContext: Facilitates communication between the Driver program and the Spark Cluster.
Under Settings , enter a name for your database cluster identifier. Amazon S3 bucket Download the sample file 2020_Sales_Target.pdf in your local environment and upload it to the S3 bucket you created. Delete the Aurora MySQL instance and Aurora cluster. Choose Create database. Select Aurora , then Aurora (MySQL compatible).
You’ll sign up for a Qdrant cloud account, install the necessary libraries, set up our environment variables, and instantiate a cluster — all the necessary steps to start building something. Source: Author You’ll need to create your cluster and get your API key. Click on the “Clusters” menu item. Copy that and keep it safe.
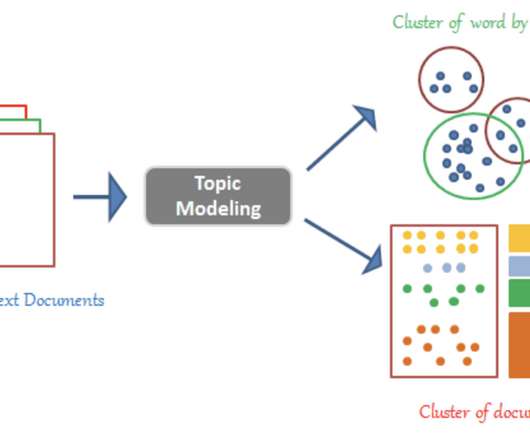
Latent Dirichlet Allocation (LDA) Topic Modeling LDA is a well-known unsupervised clustering method for text analysis. Then, the topic model applies a hierarchical clustering algorithm using conversation vectors from the output of the summary model. The LDA technique uses parametrized probability distributions for each document.
Teams that use Windows Enterprise also download and install Docker Desktop with a simple download. Similarly, you can download artifact management applications such as JFrog on your Windows system. Download and Install Docker Desktop. However, it still cannot function properly on all versions of Windows.
Solution overview To demonstrate container-based GPU metrics, we create an EKS cluster with g5.2xlarge instances; however, this will work with any supported NVIDIA accelerated instance family. Create an EKS cluster with a node group This group includes a GPU instance family of your choice; in this example, we use the g5.2xlarge instance type.
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
SageMaker supports various data sources and access patterns, distributed training including heterogenous clusters, as well as experiment management features and automatic model tuning. When an On-Demand job is launched, it goes through five phases: Starting, Downloading, Training, Uploading, and Completed.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Download the free, unabridged version here. Team How to determine the optimal team structure ?
A server cluster refers to a group of servers that share information and data. They might check in on Facebook and play a few games or download a new app to a computer that they also use for work. Good software can also identify anyone connected to your server cluster who should not be there. Cybersecurity Training.
Amazon EKS is a managed Kubernetes service that simplifies the creation, configuration, lifecycle, and monitoring of Kubernetes clusters while still offering the full flexibility of upstream Kubernetes. Creation and attachment of the FSx for Lustre file system to the EKS cluster is mediated by the Amazon FSx for Lustre CSI driver.
Building a buyer persona is more than just downloading a template online, filling in the blanks, and giving a fancy name to your customer. This type of conversational data and insight can only be extracted when clustering social media mentions and conversations amongst a target group of individuals. Data-informed buyer persona.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
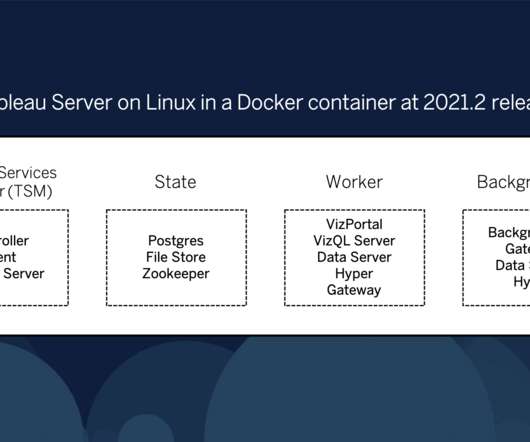
Tableau Server in a Container ships as a tarball download which includes shell scripts that give you the ability to create Tableau Server Docker container images in your local environment. To get started with Tableau Server in a Container, you’ll download the tableau-server-setup-tool tarball to begin creating your containers!
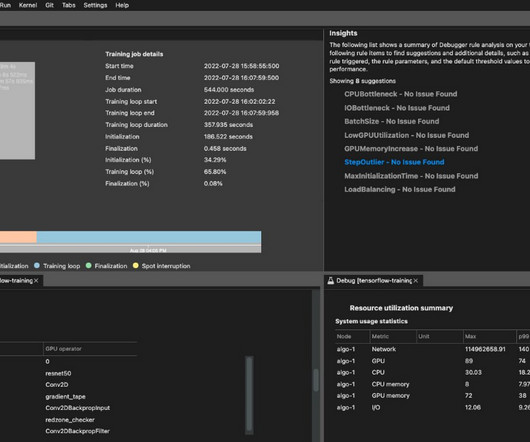
In high performance computing (HPC) clusters, such as those used for deep learning model training, hardware resiliency issues can be a potential obstacle. Although hardware failures while training on a single instance may be rare, issues resulting in stalled training become more prevalent as a cluster grows to tens or hundreds of instances.
In this blog post, we will delve into the mechanics of the Grubbs test, its application in anomaly detection, and provide a practical guide on how to implement it using real-world data. Thakur, eds., Join the Newsletter! Website The post Anomaly Detection: How to Find Outliers Using the Grubbs Test appeared first on PyImageSearch.
Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. Download the GitHub repository Complete the following steps to download the GitHub repo: In the SageMaker notebook, on the File menu, choose New and Terminal.
You can use artifacts to manage configuration, so everything from hyperparameters to cluster sizing can be managed in a single file, tracked alongside the results. Deployment To deploy a Metaflow stack using AWS CloudFormation , complete the following steps: Download the CloudFormation template. Downloading code package.
Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. We developed an AWS Batch workshop that illustrates the steps to set up the distributed training cluster with AWS Batch. The distributed training workshop illustrates the steps to set up the distributed training cluster.
Those researches are often conducted on easily available benchmark datasets which you can easily download, often with corresponding ground truth data (label data) necessary for training. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). Extract and Transform Steps The extraction is a streaming job, downloading the data from the source APIs and directly persisting it into COS.
For the first time , this enables iPhone users to download applications from sources other than the Apple App Store. This includes the ability to install an iOS alternative app store via a web browser, enabling you to download applications from sources beyond the Apple App Store. With the release of iOS 17.4
Walkthrough Download the pre-tokenized Wikipedia dataset as shown: export DATA_DIR=~/examples_datasets/gpt2 mkdir -p ${DATA_DIR} && cd ${DATA_DIR} wget [link] wget [link] aws s3 cp s3://neuron-s3/training_datasets/gpt/wikipedia/my-gpt2_text_document.bin. Each trn1.32xl has 16 accelerators with two workers per accelerator.
Downloading Requirements I recommend installing Hadoop on using the terminal it provides a easy way to check if your installation progressed successfully. To open the terminal on most Ubuntu systems the command is Ctrl+Alt+T once the terminal is opened we can start downloading the requirements using the command. tar -xvzf hadoop-3.3.6.tar.gz
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
App Store downloads ahead of ChatGPT, despite being a relatively unknown Chinese startup until recently. This assertion comes as global tech firms have committed billions to AI chip clusters and data centers, with Nvidias market value surpassing $3 trillion earlier this month. ” The comments follow U.S.
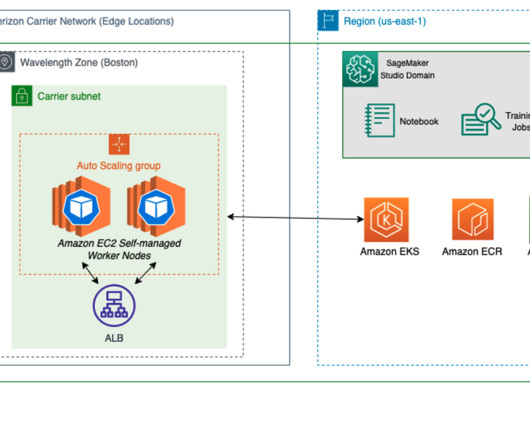
To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. Create AWS Wavelength infrastructure Before we convert the local SageMaker model inference endpoint to a Kubernetes deployment, you can create an EKS cluster in a Wavelength Zone.
So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances. These models are serving intent detection, text clustering, creative insights, text classification, smart budget allocation, and image download services.
Using Colab this can take 2-5 minutes to download and initialize the model. Load HuggingFace open source embeddings models Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content