This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
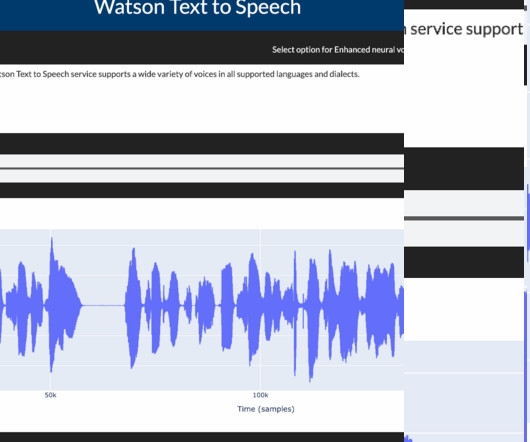
Data Processing and EDA (Exploratory Data Analysis) Speech synthesis services require that the data be in a JSON format. Text-to-speech service After the post request, you can save the audio output in your local directory or the cluster. To learn more about the TTS service, you can download the code from GitHub.
Those researches are often conducted on easily available benchmark datasets which you can easily download, often with corresponding ground truth data (label data) necessary for training. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them.
To get started, download the Anaconda installer from the official Anaconda website and follow the installation instructions for your operating system. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms. Once Anaconda is installed, launch the Anaconda Navigator.
Using Netflix user data, you need to undertake Data Analysis for running workflows like EDA, Data Visualisation and interpretation. Customer Segmentation using K-Means Clustering One of the most crucial uses of data science is customer segmentation. You will need to use the K-clustering method for this GitHub data mining project.
Reporting Data In this section, we have to download, connect and analyze the data on PowerBI. Therefore, for the sake of brevity, we have to download the file brand_cars_dashboard.pbix from the project’s GitHub repository. Download File Once we’re in the project’s GitHub repository, we need to click on “brand_cars_dashboard.pbix”.
Then they use these patterns to understand the public’s behavior and predict the election results, thus making more informed political strategies based on population clusters. Download Dataset and Create a Virtual Environment First, you need to the download Reddit Threads dataset from Kaggle.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content