This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A SageMaker domain. A QuickSight account (optional).
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Amazon SageMaker supports geospatial machinelearning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. To upload the dataset Download the dataset : Go to the Shoe Dataset page on Kaggle.com and download the dataset file (350.79MB) that contains the images.
So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances. These models are serving intent detection, text clustering, creative insights, text classification, smart budget allocation, and image download services.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machinelearning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Last Updated on June 27, 2023 by Editorial Team Source: Unsplash This piece dives into the top machinelearning developer tools being used by developers — start building! In the rapidly expanding field of artificial intelligence (AI), machinelearning tools play an instrumental role.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machinelearning (ML) solutions without writing code. Prepare data for machinelearning.
Avrim Blum, John Hopcroft, and Ravindran Kannan wrote the book, Foundations of Data Science (PDF download). It is free and available for download. It covers topics such as: MachineLearning Massive Data Clustering and many more. It can be useful for academic work or in business. See the video for more.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Machinelearning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale. The example will also work with a pre-existing EKS cluster.
With cloud computing, as compute power and data became more available, machinelearning (ML) is now making an impact across every industry and is a core part of every business and industry. To download public libraries, you must create a VPC and a private and public subnet in the SageMaker consumer account.
Summary: The UCI MachineLearning Repository, established in 1987, is a crucial resource for MachineLearning practitioners. It supports various learning tasks, including classification and regression, and is organised by type and domain, facilitating easy access for users worldwide.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machinelearning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
Download the free, unabridged version here. Machinelearning The 6 key trends you need to know in 2021 ? They bring deep expertise in machinelearning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team.
Under Settings , enter a name for your database cluster identifier. Amazon S3 bucket Download the sample file 2020_Sales_Target.pdf in your local environment and upload it to the S3 bucket you created. Delete the Aurora MySQL instance and Aurora cluster. Choose Create database. Select Aurora , then Aurora (MySQL compatible).
Install Java and Download Kafka: Install Java on the EC2 instance and download the Kafka binary: 4. It communicates with the Cluster Manager to allocate resources and oversee task progress. SparkContext: Facilitates communication between the Driver program and the Spark Cluster.
Familiarity with basic programming concepts and mathematical principles will significantly enhance your learning experience and help you grasp the complexities of Data Analysis and MachineLearning. Basic Programming Concepts To effectively learn Python, it’s crucial to understand fundamental programming concepts.
As a senior data scientist, I often encounter aspiring data scientists eager to learn about machinelearning (ML). In this comprehensive guide, I will demystify machinelearning, breaking it down into digestible concepts for beginners. What is MachineLearning?
Since its introduction, we’ve helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machinelearning (ML) workloads’ cost and usage. In this series of posts, we share lessons learned about optimizing costs in Amazon SageMaker. In this post, we focus on SageMaker training jobs.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machinelearning (ML) accelerator optimized for deep learning training. His research interests include foundational models, reinforcement learning, and asynchronous optimization. We’ll outline how we cost-effectively (3.2
Solution overview To demonstrate container-based GPU metrics, we create an EKS cluster with g5.2xlarge instances; however, this will work with any supported NVIDIA accelerated instance family. Create an EKS cluster with a node group This group includes a GPU instance family of your choice; in this example, we use the g5.2xlarge instance type.
Using the Neuron Distributed library with SageMaker SageMaker is a fully managed service that provides developers, data scientists, and practitioners the ability to build, train, and deploy machinelearning (ML) models at scale. This results in faster restarts and workload completion.
A growing number of DevOps platforms are using new data analytics and machinelearning tools to boost performance. Teams that use Windows Enterprise also download and install Docker Desktop with a simple download. Similarly, you can download artifact management applications such as JFrog on your Windows system.
For AWS and Outerbounds customers, the goal is to build a differentiated machinelearning and artificial intelligence (ML/AI) system and reliably improve it over time. You can use artifacts to manage configuration, so everything from hyperparameters to cluster sizing can be managed in a single file, tracked alongside the results.
with sdk v2 import libraries import tqdm import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as sns sns.set_style("whitegrid") import the data set # Import required libraries from azure.identity import DefaultAzureCredential from azure.identity import AzureCliCredential from azure.ai.ml
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
You’ll sign up for a Qdrant cloud account, install the necessary libraries, set up our environment variables, and instantiate a cluster — all the necessary steps to start building something. Source: Author You’ll need to create your cluster and get your API key. Click on the “Clusters” menu item. Copy that and keep it safe.
Downloading YouTube Comments via Python API: The project starts by extracting comments from YouTube videos related to this specific movie. They are pretty straightforward, you can find the full documentation at this link: First of all we want to download the comments related to a video talking about a specific movie.
Trainium is the second-generation machinelearning (ML) accelerator that AWS purpose built to help developers access high-performance model training accelerators to help lower training costs by up to 50% over comparable Amazon Elastic Compute Cloud (Amazon EC2) instances. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge
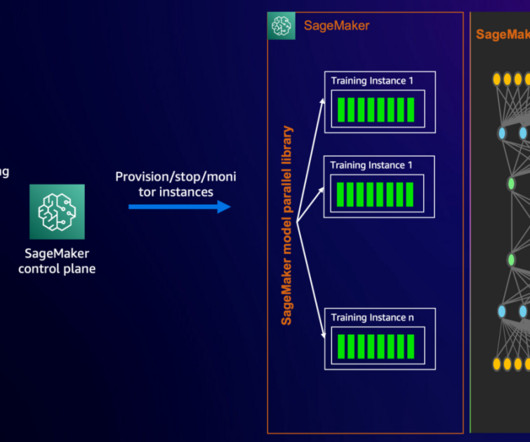
These factors require training an LLM over large clusters of accelerated machinelearning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machinelearning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
Here, we use AWS HealthOmics storage as a convenient and cost-effective omic data store and Amazon Sagemaker as a fully managed machinelearning (ML) service to train and deploy the model. Data preparation and loading into sequence store The initial step in our machinelearning workflow focuses on preparing the data.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. Solution overview You can use DeepSeeks distilled models within the AWS managed machinelearning (ML) infrastructure. You can connect with Prasanna on LinkedIn.
Many organizations are implementing machinelearning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. Because this data is across organizations, we use federated learning to collate the findings. You can also download these models from the website.
The model weights are available to download, inspect and deploy anywhere. Starting June 7th, both Falcon LLMs will also be available in Amazon SageMaker JumpStart, SageMaker’s machinelearning (ML) hub that offers pre-trained models, built-in algorithms, and pre-built solution templates to help you quickly get started with ML.
Many practitioners are extending these Redshift datasets at scale for machinelearning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium —a purpose-built machinelearning (ML) accelerator optimized to provide a high-performance, cost-effective, and massively scalable platform for training deep learning models in the cloud.
In today’s blog, we will see some very interesting Python MachineLearning projects with source code. This list will consist of Machinelearning projects, Deep Learning Projects, Computer Vision Projects , and all other types of interesting projects with source codes also provided.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content