This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. For this post we’ll use a provisioned Amazon Redshift cluster.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
To upload the dataset Download the dataset : Go to the Shoe Dataset page on Kaggle.com and download the dataset file (350.79MB) that contains the images. With Amazon OpenSearch Serverless, you don’t need to provision, configure, and tune the instance clusters that store and index your data. b64encode(image_file.read()).decode('utf-8')
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets.
Machine learning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale. The following figure shows how FSDP works for two data parallel processes.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
With cloud computing, as compute power and data became more available, machine learning (ML) is now making an impact across every industry and is a core part of every business and industry. Amazon SageMaker Studio is the first fully integrated ML development environment (IDE) with a web-based visual interface.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Give this technique a try to take your team’s ML modelling to the next level.
Let’s get started with the best machine learning (ML) developer tools: TensorFlow TensorFlow, developed by the Google Brain team, is one of the most utilized machine learning tools in the industry. This open-source library is renowned for its capabilities in numerical computation, particularly in large-scale machine learning projects.
Using the Neuron Distributed library with SageMaker SageMaker is a fully managed service that provides developers, data scientists, and practitioners the ability to build, train, and deploy machine learning (ML) models at scale. Cluster update is currently enabled for the TRN1 instance family as well as P and G GPU-based instance types.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. As part of a single cluster run, you can spin up a cluster of Trn1 instances with Trainium accelerators. Trn1 UltraClusters can host up to 30,000 Trainium devices and deliver up to 6 exaflops of compute in a single cluster.
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machine learning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. Second, open source Metaflow provides the necessary software infrastructure to build production-grade ML/AI systems in a developer-friendly manner.
Since its introduction, we’ve helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machine learning (ML) workloads’ cost and usage. When an On-Demand job is launched, it goes through five phases: Starting, Downloading, Training, Uploading, and Completed.
Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Design patterns for building ML applications.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. Solution overview You can use DeepSeeks distilled models within the AWS managed machine learning (ML) infrastructure. Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS.
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. About the Authors Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster.
In these cases, the model sizes are smaller, which means the communication overhead with GPUs or ML accelerator instances outweighs their compute performance benefits. As early adopters of Graviton for ML workloads, it was initially challenging to identify the right software versions and the runtime tunings.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. We recently developed four more new models.
Solution overview To demonstrate container-based GPU metrics, we create an EKS cluster with g5.2xlarge instances; however, this will work with any supported NVIDIA accelerated instance family. Create an EKS cluster with a node group This group includes a GPU instance family of your choice; in this example, we use the g5.2xlarge instance type.
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium —a purpose-built machine learning (ML) accelerator optimized to provide a high-performance, cost-effective, and massively scalable platform for training deep learning models in the cloud.
Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. We developed an AWS Batch workshop that illustrates the steps to set up the distributed training cluster with AWS Batch. The distributed training workshop illustrates the steps to set up the distributed training cluster.
As one of the most prominent use cases to date, machine learning (ML) at the edge has allowed enterprises to deploy ML models closer to their end-customers to reduce latency and increase responsiveness of their applications. Even ground and aerial robotics can use ML to unlock safer, more autonomous operations.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. SageMaker Training is a managed batch ML compute service that reduces the time and cost to train and tune models at scale without the need to manage infrastructure. SageMaker-managed clusters of ml.p4d.24xlarge
Here, we use AWS HealthOmics storage as a convenient and cost-effective omic data store and Amazon Sagemaker as a fully managed machine learning (ML) service to train and deploy the model. With SageMaker Training, a managed batch ML compute service, users can efficiently train models without having to manage the underlying infrastructure.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
Trainium is the second-generation machine learning (ML) accelerator that AWS purpose built to help developers access high-performance model training accelerators to help lower training costs by up to 50% over comparable Amazon Elastic Compute Cloud (Amazon EC2) instances. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge
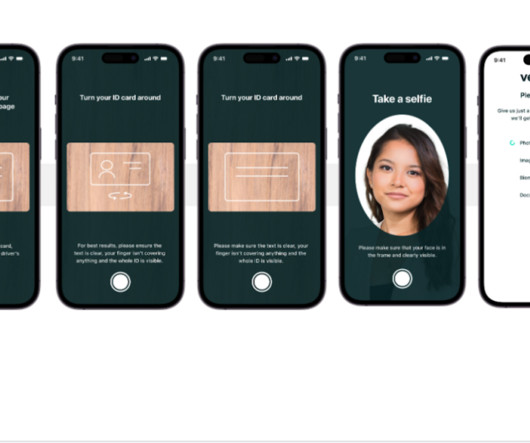
As an AI-powered solution, Veriff needs to create and run dozens of machine learning (ML) models in a cost-effective way. Infrastructure and development challenges Veriff’s backend architecture is based on a microservices pattern, with services running on different Kubernetes clusters hosted on AWS infrastructure.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. Training steps To run the training, we use SLURM managed multi-node Amazon Elastic Compute Cloud ( Amazon EC2 ) Trn1 cluster, with each node containing a trn1.32xl instance.
A basic, production-ready cluster priced out to the low-six-figures. A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Plus there was all of the infrastructure to push data into the cluster in the first place. Goodbye, Hadoop. And it was good.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
As a senior data scientist, I often encounter aspiring data scientists eager to learn about machine learning (ML). Typical unsupervised learning tasks include clustering (e.g., It’s a fascinating field that can seem daunting at first, but I assure you, with the right mindset and resources, anyone can master it.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Hugging Face is a popular open source hub for machine learning (ML) models. You use the same script for downloading the model file when creating the SageMaker endpoint.
The model weights are available to download, inspect and deploy anywhere. Starting June 7th, both Falcon LLMs will also be available in Amazon SageMaker JumpStart, SageMaker’s machine learning (ML) hub that offers pre-trained models, built-in algorithms, and pre-built solution templates to help you quickly get started with ML.
Text representation with Embed – Developers can access endpoints that capture the semantic meaning of text, enabling applications such as vector search engines, text classification and clustering, and more. Next, you set up a Weaviate cluster. Subscribe to the Weaviate Kubernetes Cluster on AWS Marketplace.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. The KG files were stored in Amazon Simple Storage Service (Amazon S3) and then loaded in Amazon Neptune.
Here is HuggingFace Link: [link] From the Mosaic ML paper. Here is the HuggingFace Link: [link] From the Mosaic ML paper. This approach offers several benefits, including the elimination of the need to download the entire dataset before commencing training. This model was trained with 9.6M This model was trained with 86M tokens.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content