This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Distributed model training requires a cluster of worker nodes that can scale. Amazon Elastic Kubernetes Service (Amazon EKS) is a popular Kubernetes-conformant service that greatly simplifies the process of running AI/ML workloads, making it more manageable and less time-consuming.
In our test environment, we observed 20% throughput improvement and 30% latency reduction across multiple naturallanguageprocessing models. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Download the free, unabridged version here.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. This method is generally much faster, with the model typically downloading in just a couple of minutes from Amazon S3. In his free time, he enjoys playing chess and traveling.
Using Colab this can take 2-5 minutes to download and initialize the model. Load HuggingFace open source embeddings models Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically.
For instance, today’s machine learning tools are pushing the boundaries of naturallanguageprocessing, allowing AI to comprehend complex patterns and languages. These tools are becoming increasingly sophisticated, enabling the development of advanced applications.
In high performance computing (HPC) clusters, such as those used for deep learning model training, hardware resiliency issues can be a potential obstacle. Although hardware failures while training on a single instance may be rare, issues resulting in stalled training become more prevalent as a cluster grows to tens or hundreds of instances.
Historically, naturallanguageprocessing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
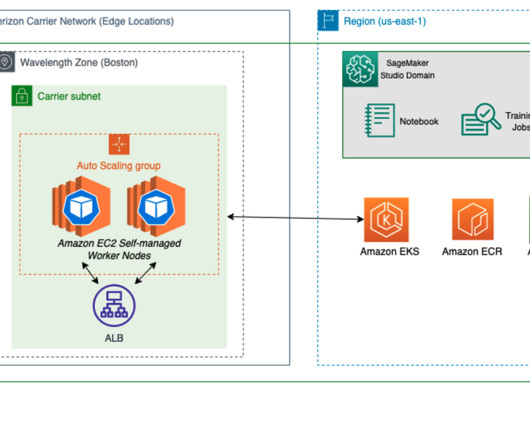
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. sourcedir.tar.gz
Those researches are often conducted on easily available benchmark datasets which you can easily download, often with corresponding ground truth data (label data) necessary for training. This characteristic is clearly observed in models in naturallanguageprocessing (NLP) and computer vision (CV) like in the graphs below.
Using Colab this can take 2-5 minutes to download and initialize the model. LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. His research interests are in the area of naturallanguageprocessing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. SageMaker features and capabilities help developers and data scientists get started with naturallanguageprocessing (NLP) on AWS with ease.
For Secret type , choose Credentials for Amazon Redshift cluster. Choose the Redshift cluster associated with the secrets. However, it is essential to acknowledge the inherent differences between human language and SQL. Complete the following steps: On the Secrets Manager console, choose Store a new secret.
Text representation with Embed – Developers can access endpoints that capture the semantic meaning of text, enabling applications such as vector search engines, text classification and clustering, and more. Cohere Embed comes in two forms, an English language model and a multilingual model, both of which are now available on Amazon Bedrock.
Genomic language models Genomic language models represent a new approach in the field of genomics, offering a way to understand the language of DNA. We use a SageMaker notebook to process the genomic files and to import these into a HealthOmics sequence store. These weights are pretrained on the human reference genome.
For CSV, we still recommend splitting up large files into smaller ones to reduce data download time and enable quicker reads. The single-GPU training path still has some advantage in downloading and reading only part of the data in each instance, and therefore low data download time. However, it’s not a requirement.
Download the Amazon SageMaker FAQs When performing the search, look for Answers only, so you can drop the Question column. His research interests are in the area of naturallanguageprocessing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
The size of large NLP models is increasing | Source Such large naturallanguageprocessing models require significant computational power and memory, which is often the leading cause of high infrastructure costs. Users cannot download such large scaled models on their systems just to translate or summarise a given text.
Some of the other useful properties of the architecture compared to previous generations of naturallanguageprocessing (NLP) models include the ability distribute, scale, and pre-train. It uses attention as the learning mechanism to achieve close to human-level performance.
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 Instead of manually running multiple queries, downloading numerous papers, and sifting through extensive metadata, we aimed to streamline NASA's research processes.
It is critical in powering modern AI systems, from image recognition to naturallanguageprocessing. It supports Machine Learning tasks, from image and speech recognition to naturallanguageprocessing and recommendation systems. What is TensorFlow, and why is it important? What is TensorFlow?
This will create all the necessary infrastructure resources needed for this solution: SageMaker endpoints for the LLMs OpenSearch Service cluster API Gateway Lambda function SageMaker Notebook IAM roles Run the data_ingestion_to_vectordb.ipynb notebook in the SageMaker notebook to ingest data from SageMaker docs into an OpenSearch Service index.
time series or naturallanguageprocessing tasks). Feature Learning Autoencoders can learn meaningful features from input data, which can be used for downstream machine learning tasks like classification, clustering, or regression. This architecture is well-suited for handling sequential data (e.g., Join the Newsletter!
Instead of downloading all the models to the endpoint instance, SageMaker dynamically loads and caches the models as they are invoked. If the model has not been loaded, it downloads the model artifact from Amazon Simple Storage Service (Amazon S3) to that instance’s Amazon Elastic Block Storage volume (Amazon EBS).
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts naturallanguage text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing. This is widely used in NaturalLanguageProcessing (NLP), where it plays a pivotal role in pre-processing unstructured textual data. What are some of the other popular Vector Databases?
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing trillions of requests per month. Prerequisites.
Alternatively, you can directly download the Dockerfile.gpu from GitHub developed by ahmetoner , which includes a pre-configured RESTful API. His research interests are in the area of naturallanguageprocessing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art naturallanguageprocessing (NLP) model to find useful signals in text. First let’s download the test, validate, and train dataset from the source S3 bucket and upload it to our S3 bucket. Data exploration.
Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. It has intuitive helpers and utilities for modalities like computer vision, naturallanguageprocessing, audio, time series, and tabular data.
Generative language models have proven remarkably skillful at solving logical and analytical naturallanguageprocessing (NLP) tasks. DynamoDB table An application running on AWS uses an Amazon Aurora Multi-AZ DB cluster deployment for its database. Lambda function B. SQS queue C. EC2 instance D.
The Lambda will download these previous predictions from Amazon S3. If the prediction status is success , an S3 pre-signed URL will be returned for the user to download the prediction content. If the status of the prediction is error , then the relevant details on the failure will be included in the response.
of the spaCy NaturalLanguageProcessing library adds models for five new languages. To achieve this, models no longer store derivable lexeme attributes such as lower and is_alpha and the remaining lexeme attributes ( norm , cluster and prob ) have been moved to spacy-lookups-data. Version 2.3
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
Download it from the official Python website. By applying naturallanguageprocessing (NLP) techniques, businesses can visualise sentiment trends over time, allowing them to address customer concerns and improve product offerings effectively.
You are responsible for reviewing and complying with any applicable license terms and making sure they are acceptable for your use case before downloading or using the content. Be sure to review the license for any foundation model that you use. In this section, we go over how to discover the models in SageMaker Studio.
We continued to grow open source datasets in 2022, for example, in naturallanguageprocessing and vision, and expanded our global index of available datasets in Google Dataset Search. Bazel GitHub Metrics A dataset with GitHub download counts of release artifacts from selected bazelbuild repositories.
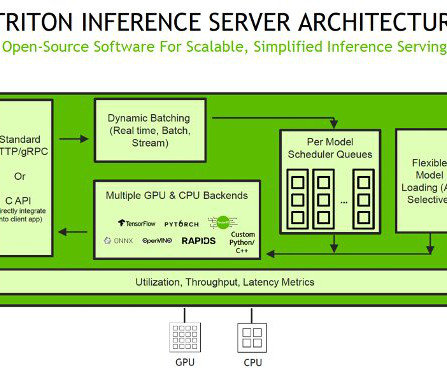
Triton supports a heterogeneous cluster with both GPUs and CPUs, which helps standardize inference across platforms and dynamically scales out to any CPU or GPU to handle peak loads. SageMaker provides Triton via SMEs and MMEs SageMaker enables you to deploy both single and multi-model endpoints with Triton Inference Server.
In general, it’s a large language model, not altogether that different from language machine learning models we’ve seen in the past that do various naturallanguageprocessing tasks. So they download all of the text on the internet, and they train language models to predict all of that text.
For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. The entire model can be downloaded to your source code’s runtime with a single line of code. Check out the Kubeflow documentation.
Apache Hadoop Apache Hadoop is an open-source framework that supports the distributed processing of large datasets across clusters of computers. It uses a map-reduce paradigm, making it suitable for batch processing unstructured data on a massive scale. The ProcessorConfig class is used to configure the ingestion process.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content