This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. Thus, we use an Extract-Transform-Load (ETL) process to ingest the data.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. A three-step ETL framework job should do the trick. Step 3: Create an ETL job and save that data to a data lake. Conclusion.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. It supports various data types and offers advanced features like data sharing and multi-cluster warehouses.
Two popular players in this area are Alteryx Designer and Matillion ETL , both offering strong solutions for handling data workflows with Snowflake Data Cloud integration. Matillion ETL is purpose-built for the cloud, operating smoothly on top of your chosen data warehouse. Today we will focus on Snowflake as our cloud product.
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
It provides a large cluster of clusters on a single machine. AWS SageMaker is useful for creating basic models, including regression, classification, and clustering. It focuses on two aspects of data management: ETL (extract-transform-load) and data lifecycle management. It has built-in support for machine learning.
Under Settings , enter a name for your database cluster identifier. Delete the Aurora MySQL instance and Aurora cluster. She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management. He has experience across analytics, big data, and ETL. Choose Create database.
Summary: Choosing the right ETL tool is crucial for seamless data integration. At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. What is ETL?
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker.
Responsibility for maintenance and troubleshooting: Rockets DevOps/Technology team was responsible for all upgrades, scaling, and troubleshooting of the Hadoop cluster, which was installed on bare EC2 instances. Data Storage and Processing: All compute is done as Spark jobs inside of a Hadoop cluster using Apache Livy and Spark.
The ETL (extract, transform, and load) technology market also boomed as the means of accessing and moving that data, with the necessary translations and mappings required to get the data out of source schemas and into the new DW target schema. The big data boom was born, and Hadoop was its poster child.
In this blog, we explore best practices and techniques to optimize Snowflake’s performance for data vault modeling , enabling your organizations to achieve efficient data processing, accelerated query performance, and streamlined ETL workflows. This reduces the complexity of the ETL process and improves development efficiency.
Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes. An EMR cluster with EMR runtime roles enabled. Associating runtime roles with EMR clusters is supported in Amazon EMR 6.9. The EMR cluster should be created with encryption in transit.
Evaluate integration capabilities with existing data sources and Extract Transform and Load (ETL) tools. Architecture At its core, Redshift consists of clusters made up of compute nodes, coordinated by a leader node that manages communications, parses queries, and executes plans by distributing tasks to the compute nodes.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. ETL Design Pattern Here is an example of how the ETL design pattern can be used in a real-world scenario: A healthcare organization wants to analyze patient data to improve patient outcomes and operational efficiency.
While both handle vast datasets across clusters, they differ in approach. It distributes large datasets across multiple nodes in a cluster , ensuring data availability and fault tolerance. Data is processed in parallel across the cluster in the map phase, while in the Reduce phase, the results are aggregated.
Horizontal scaling increases the quantity of computational resources dedicated to a workload; the equivalent of adding more servers or clusters. Complex data transformations and ETL/ELT pipelines with significant data movement can see increases in latency. Data integrations and pipelines can also impact latency.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Data Engineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing.
Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. And what about the Thor and Roxie clusters? As the database server in an HPCC Systems solution, a Thor cluster’s job is to import and process data at scale. Can you get more granular?
Daily Net Asset Value (NAV) computation, portfolio performance analysis, and reporting can become efficient and reduces time to market, with Snowflake’s multi-cluster concurrency architecture that separates data from computing. Data movements lead to high costs of ETL and rising data management TCO.
To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL. Customers will be responsible for deleting the input data sources created by them, such as Amazon Simple Storage Service (Amazon S3) buckets, Amazon Redshift clusters, and so on. Choose Delete.
Once this is confirmed, run the following command to install the Kafka connector inside the container and then restart the connected cluster. Once the cluster is up and running, Confluent UI can be accessed using this [link] from your local machine. Kafka Connect uses key-pair authentication instead of a regular user ID password.
Scalability : NiFi can be deployed in a clustered environment, enabling organizations to scale their data processing capabilities as their data needs grow. Its visual interface allows users to design complex ETL workflows with ease. Apache NiFi is used for automating the flow of data between systems.
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a data warehouse or data lake. What Are Some Common Tools Used in Business Intelligence Architecture?
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. ETL ARCHITECTURE DIAGRAM ETL stands for Extract, Transform, Load. ETL ensures data quality and enables analysis and reporting.
It acts as a catalogue, providing information about the structure and location of the data. · Hive Query Processor It translates the HiveQL queries into a series of MapReduce jobs. · Hive Execution Engine It executes the generated query plans on the Hadoop cluster. It manages the execution of tasks across different environments.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. These models may include regression, classification, clustering, and more. ETL Tools: Apache NiFi, Talend, etc. Read more to know. They work with databases and data warehouses to ensure data integrity and security.
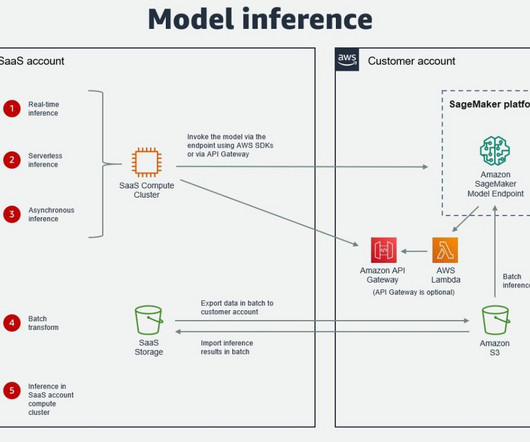
Alternatively, a service such as AWS Glue or a third-party extract, transform, and load (ETL) tool can be used for data transfer. Another option for inference is to do it directly in the SaaS account compute cluster. The agent can be installed on Amazon Elastic Compute Cloud (Amazon EC2) or AWS Lambda.
Definition of HDFS HDFS is an open-source file system that manages files across a cluster of commodity servers. NameNode The NameNode is your HDFS cluster’s central authority, maintaining the file systems directory tree and metadata. You can seamlessly add new Data Nodes to the Hadoop cluster without disrupting ongoing tasks.
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka.
Consider these common scenarios: A perfect validation script cant fix inconsistent data entry practices The most robust ETL pipeline cant resolve disagreements about business rules Real-time quality monitoring cant replace clear data ownership. Managing these costs efficiently is crucial to sustaining AI advancements.
But, it does not give you all the information about the different functionalities and services, like Data Factory/Linked Services/Analytics Synapse(how to combine and manage databases, ETL), Cognitive Services/Form Recognizer/ (how to do image, text, audio processing), IoT, Deployment, GitHub Actions (running Azure scripts from GitHub).
These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines. Multimodal embeddings help combine unstructured data from various sources in data warehouses and ETL pipelines. The features extracted in the ETL process would then be inputted into the ML models.
Talend Overview While Talend’s Open Studio for Data Integration is free-to-download software to start a basic data integration or an ETL project, it also comes powered with more advanced features which come with a price tag. Hevo Data Overview It’s an intuitive no-code ETL tool that also supports ELT and reverse ETL processes out of the box.
Extraction, transformation and loading (ETL) tools dominated the data integration scene at the time, used primarily for data warehousing and business intelligence. Critical and quick bridges The demand for lineage extends far beyond dedicated systems such as the ETL example.
Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines. Cloud-agnostic and can run on any Kubernetes cluster. Integration: It can work alongside other workflow orchestration tools (Airflow cluster or AWS SageMaker Pipelines, etc.)
Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers. Understanding ETL (Extract, Transform, Load) processes is vital for students. Students should learn how to train and evaluate models using large datasets.
Techniques like binning, regression, and clustering are employed to smooth and filter the data, reducing noise and improving the overall quality of the dataset. Noise refers to random errors or irrelevant data points that can adversely affect the modeling process.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity. Apache Hadoop Hadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers.
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. The celery flower is used for managing the celery cluster, which is not needed for a local executor. You can also change it to SequentialExecutor if you wish to use it.
Then, I would use clustering techniques such as k-means or hierarchical clustering to group customers based on similarities in their purchasing behaviour. Data Warehousing and ETL Processes What is a data warehouse, and why is it important? Explain the Extract, Transform, Load (ETL) process. What approach would you take?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content