

Improve Cluster Balance with CPD Scheduler?—?Part 2
IBM Data Science in Practice
JULY 5, 2023
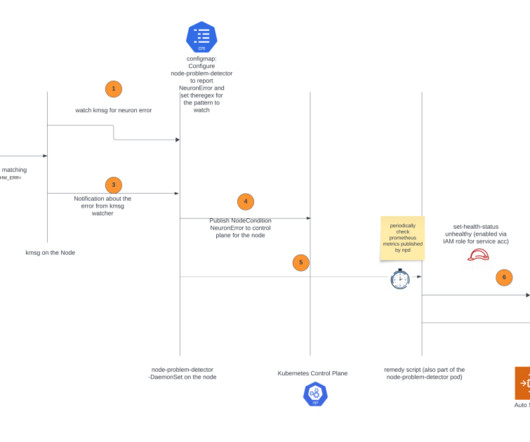
Improve Cluster Balance with CPD Scheduler — Part 2 The default Kubernetes scheduler has some limitations that cause unbalanced clusters. In an unbalanced cluster, some of the worker nodes are overloaded and others are under-utilized. we will use “cluster balance” and “resource usage balance” interchangeably.










































Let's personalize your content