This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the time, I knew little about AI or machine learning (ML). But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML. Panic set in as we realized we would be competing on stage in front of thousands of people while knowing little about ML.
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. RELand consistently outperforms the benchmark models on all relevant metrics.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
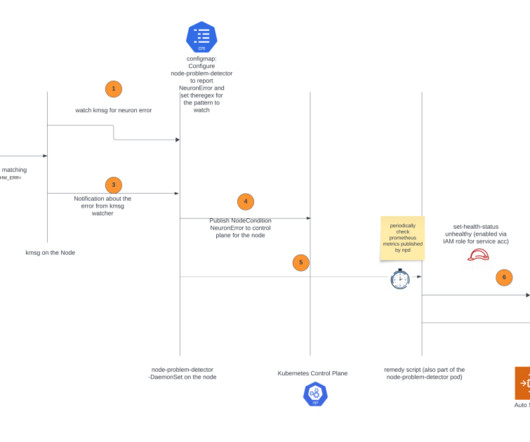
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. Additionally, the node recovery agent will publish Amazon CloudWatch metrics for users to monitor and alert on these events. install.sh and public.ecr.aws. .
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Unsupervised ML: The Basics. Unlike supervised ML, we do not manage the unsupervised model. Unsupervised ML uses algorithms that draw conclusions on unlabeled datasets. As a result, unsupervised ML algorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes.
Learn more about how you can volunteer for either the in-person or virtual team and get a free ticket to the event. Volunteer for ODSC East 2023 ODSC volunteers are an integral part of the success of each ODSC conference and a perfect extension of our core team and ambassadors to our community!
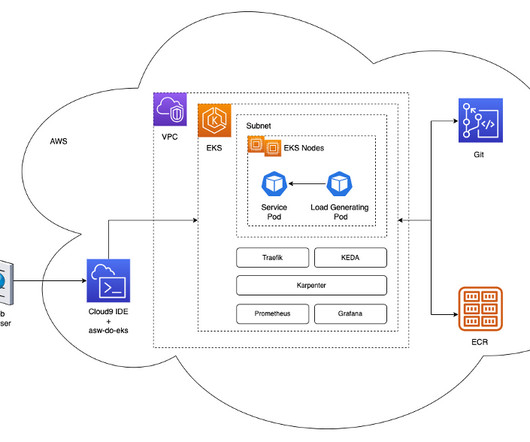
However, it lacked essential services required for machine learning (ML) applications, such as frontend and backend infrastructure, DNS, load balancers, scaling, blob storage, and managed databases. The S3 bucket is configured in such a way that it forwards (2) all events into EventBridge. We use Karpenter as the cluster auto scaler.
It usually comprises parsing log data into vectors or machine-understandable tokens, which you can then use to train custom machine learning (ML) algorithms for determining anomalies. You can adjust the inputs or hyperparameters for an ML algorithm to obtain a combination that yields the best-performing model. scikit-learn==0.21.3
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
Amazon OpenSearch Service is a fully managed solution that simplifies the deployment, operation, and scaling of OpenSearch clusters in the AWS Cloud. Log and Event Analytics: Index, store, and analyze logs from cloud applications, security monitoring tools, and observability platforms to detect trends and troubleshoot issues.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Data Storage and Processing: All compute is done as Spark jobs inside of a Hadoop cluster using Apache Livy and Spark. Apache HBase was employed to offer real-time key-based access to data.
GuardDuty combines machine learning (ML), anomaly detection, and malicious file discovery, using both AWS and industry-leading third-party sources, to help protect AWS accounts, workloads, and data. GuardDuty integrates with Amazon EventBridge by creating an event for EventBridge for new generated vulnerability findings.
With cloud computing, as compute power and data became more available, machine learning (ML) is now making an impact across every industry and is a core part of every business and industry. Amazon SageMaker Studio is the first fully integrated ML development environment (IDE) with a web-based visual interface.
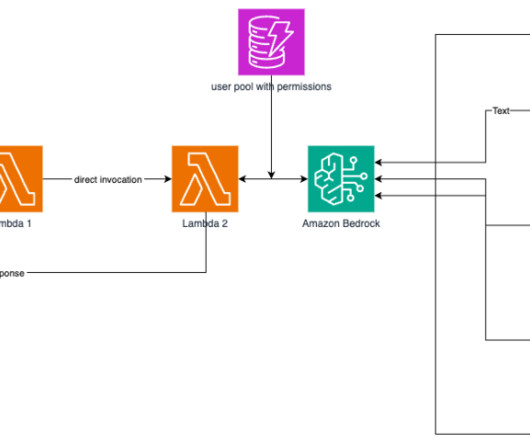
Our commitment to innovation led us to a pivotal challenge: how to harness the power of machine learning (ML) to further enhance our competitive edge while balancing this technological advancement with strict data security requirements and the need to streamline access to our existing internal resources.
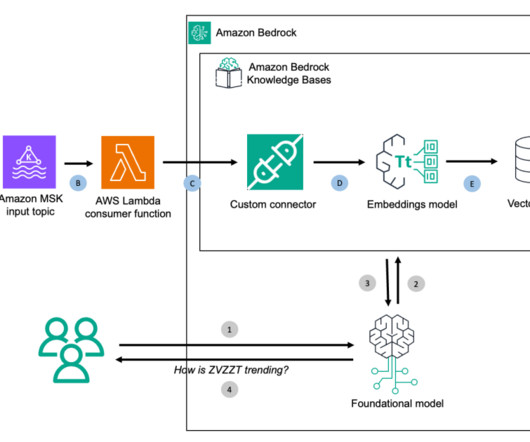
The next step is to use a SageMaker Studio terminal instance to connect to the MSK cluster and create the test stream topic. The next step is to use a SageMaker Studio terminal instance to connect to the MSK cluster and create the test stream topic. Prepare the test data. ticker price OOOO $44.50 ZVZZT $3,413.23 ZNRXX $208.76
He helps architect solutions across AI/ML applications, enterprise data platforms, data governance, and unified search in enterprises. Gi Kim is a Data & ML Engineer with the AWS Professional Services team, helping customers build data analytics solutions and AI/ML applications.
The architecture deploys a simple service in a Kubernetes pod within an EKS cluster. The Kubernetes Event Driven Autoscaler ( KEDA ) is configured to automatically scale the number of service pods, based on the custom metrics available in Prometheus. xlarge nodes is included to run system pods that are needed by the cluster.
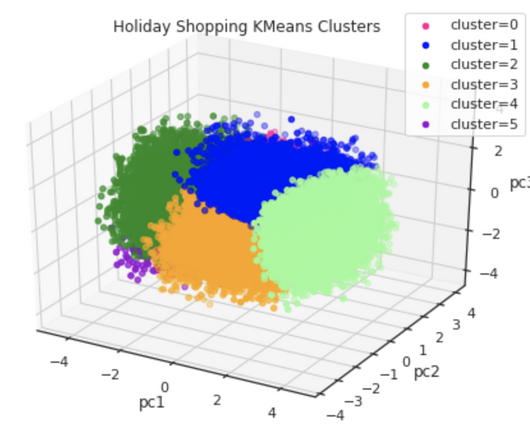
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. What is Classification?
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Geobox enables city departments to do the following: Improved climate adaptation planning – Informed decisions reduce the impact of extreme heat events.
It can represent a geographical area as a whole or it can represent an event associated with a geographical area. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
This capability allows for the seamless addition of SageMaker HyperPod managed compute to EKS clusters, using automated node and job resiliency features for foundation model (FM) development. FMs are typically trained on large-scale compute clusters with hundreds or thousands of accelerators.
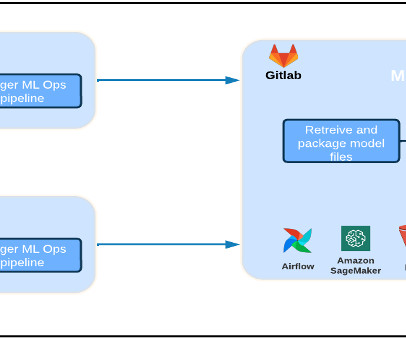
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. Best practices for ml model packaging Here is how you can package a model efficiently.
Meta is currently operating many data centers with GPU training clusters across the world. Meta’s training infrastructure comprises dozens of AI clusters of varying sizes, with a plan to scale to 600,000 GPUs in the next year. It runs thousands of training jobs every day from hundreds of different Meta teams.
The listing writer microservice publishes listing change events to an Amazon Simple Notification Service (Amazon SNS) topic, which an Amazon Simple Queue Service (Amazon SQS) queue subscribes to. The cluster comprises 3 cluster manager nodes (m6g.xlarge.search instance) dedicated to manage cluster operations.
The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem. Consumers read the events and process the data in real-time. Editor’s note: Kai Waehner is a speaker for ODSC Europe this June.
You can run Spark applications interactively from Amazon SageMaker Studio by connecting SageMaker Studio notebooks and AWS Glue Interactive Sessions to run Spark jobs with a serverless cluster. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Webex by Cisco is a leading provider of cloud-based collaboration solutions, including video meetings, calling, messaging, events, polling, asynchronous video, and customer experience solutions like contact center and purpose-built collaboration devices. The following diagram illustrates the WxAI architecture on AWS.
Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Design patterns for building ML applications.
Amazon SageMaker Canvas Amazon SageMaker Canvas is a visual machine learning (ML) service that enables business analysts and data scientists to build and deploy custom ML models without requiring any ML experience or having to write a single line of code. Through Atlas Data Federation, data is extracted into Amazon S3 bucket.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
It uses predictive modelling to forecast future events and adaptiveness to improve with new data, plus generalization to analyse fresh data. This scenario highlights a common reality in the Machine Learning landscape: despite the hype surrounding ML capabilities, many projects fail to deliver expected results due to various challenges.
For any machine learning (ML) problem, the data scientist begins by working with data. Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. In order to provision a highly scalable cluster that is resilient to hardware failures, Thomson Reuters turned to Amazon SageMaker HyperPod.
With terabytes of data generated by the product, the security analytics team focuses on building machine learning (ML) solutions to surface critical attacks and spotlight emerging threats from noise. Solution overview The following diagram illustrates the ML platform architecture.
We introduce some use case-specific methods, such as temporal frame smoothing and clustering, to enhance the video search performance. Less frequent frame sampling might make sense when working with longer videos, whereas more frequent frame sampling might be needed to catch fast-occurring events.
AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. For more information, refer to Preview: Use Amazon SageMaker to Build, Train, and Deploy ML Models Using Geospatial Data.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster.
Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources. AI and machine learning Building and deploying artificial intelligence (AI) and machine learning (ML) systems requires huge volumes of data and complex processes like high performance computing and big data analysis.
Historically, our space has perceived streaming as a complex technology reserved for experienced data engineers with a deep understanding of incremental event processing. When combined with event-time windows, analyzing the embeddings in real-time becomes much more feasible. October 2022).
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content