This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Go to the PivotTable Analyze tab >> select Pivot Chart >> select Clustered Column. Add data labels: Expand Chart Elements >> click Data Labels. Regional Performance Column Chart Select the Regional pivot table. Format: Title: Sales by Region. Different colors for each region. Data labels on top of columns.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
These professionals venture into new frontiers like machine learning, naturallanguageprocessing, and computer vision, continually pushing the limits of AI’s potential. This is used for tasks like clustering, dimensionality reduction, and anomaly detection. What are some emerging AI applications that excite you?
Step 1: Cover the Fundamentals You can skip this step if you already know the basics of programming, machine learning, and naturallanguageprocessing. The key here is to focus on concepts like supervised vs. unsupervised learning, regression, classification, clustering, and model evaluation. So, lets get started.
Clustering algorithms (K-Means) classify wallet activity to forecast shifts on a larger scale. No model, however sophisticated, can account for the black swan events, regulatory changes, or exchange outages. XGBoost/Random ForestGood with many variable predictions like BTC dominance, open interest and ETH correlation.
Predictive modeling is a mathematical process that focuses on utilizing historical and current data to predict future outcomes. By identifying patterns within the data, it helps organizations anticipate trends or events, making it a vital component of predictive analytics.
The implementation uses Slacks event subscription API to process incoming messages and Slacks Web API to send responses. The incoming event from Slack is sent to an endpoint in API Gateway, and Slack expects a response in less than 3 seconds, otherwise the request fails. Sonnet model for naturallanguageprocessing.
Probability is the measurement of the likelihood of events. Probability distributions are collections of all events and their probabilities. Clustering (Unsupervised). With Clustering the data is divided into groups. By applying clustering based on distance, the villages are divided into groups. Probability.
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. They are typically trained on clusters of computers or even on cloud computing platforms.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
With IBM Watson NLP, IBM introduced a common library for naturallanguageprocessing, document understanding, translation, and trust. This tutorial walks you through the steps to serve pretrained Watson NLP models using Knative Serving in a Red Hat OpenShift cluster. For more information see [link].
Amazon OpenSearch Service is a fully managed solution that simplifies the deployment, operation, and scaling of OpenSearch clusters in the AWS Cloud. Log and Event Analytics: Index, store, and analyze logs from cloud applications, security monitoring tools, and observability platforms to detect trends and troubleshoot issues.
Doctors and medical professionals have long struggled to predict and understand the adverse drug events prescriptions can have on their patients, but machine learning and artificial intelligence can help doctors prescribe drugs more intelligently. Then, we begin training our first preliminary models using the data set.
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. submit_btn.click(main, inputs=[data,qs], outputs=[answer]) : Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources. Kubernetes’s declarative, API -driven infrastructure has helped free up DevOps and other teams from manually driven processes so they can work more independently and efficiently to achieve their goals.
Webex by Cisco is a leading provider of cloud-based collaboration solutions, including video meetings, calling, messaging, events, polling, asynchronous video, and customer experience solutions like contact center and purpose-built collaboration devices. This post is co-authored with Travis Mehlinger and Karthik Raghunathan from Cisco.
That’s when researchers in information retrieval prototyped what they called question-answering systems, apps that use naturallanguageprocessing ( NLP ) to access text, initially in narrow topics such as baseball. The History of Retrieval-Augmented Generation The roots of the technique go back at least to the early 1970s.
Running SageMaker Processing jobs takes place fully within a managed SageMaker cluster, with individual jobs placed into instance containers at run time. The managed cluster, instances, and containers report metrics to Amazon CloudWatch , including usage of GPU, CPU, memory, GPU memory, disk metrics, and event logging.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. submit_btn.click(main, inputs=[data,qs], outputs=[answer]) : Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
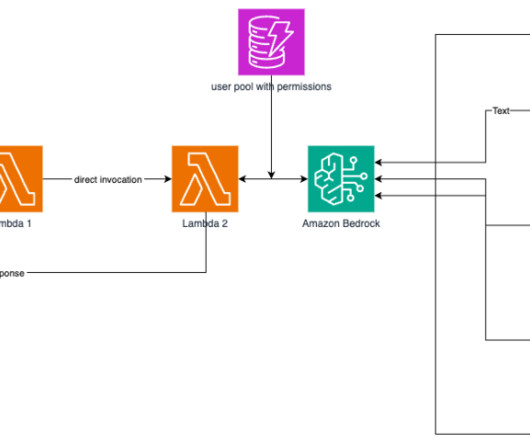
The document ingestion workflow (numbered in blue in the preceding diagram) processes content through five distinct stages: Documents uploaded to Amazon Simple Storage Service (Amazon S3) automatically invoke Lambda functions through S3 Event Notifications. This event-driven architecture provides immediate processing of new documents.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
The Bay Area Chapter of Women in Big Data (WiBD) hosted its second successful episode on the NLP (NaturalLanguageProcessing), Tools, Technologies and Career opportunities. The event was part of the chapter’s technical talk series 2023. Computational Linguistics is rule based modeling of naturallanguages.
This enables them to respond quickly to changing conditions or events. In IoT, unsupervised learning algorithms are valuable for tasks such as clustering similar devices, identifying patterns in data, or detecting anomalies without prior knowledge of expected outcomes.
Also known as outlier detection, anomaly detection is an unsupervised learning technique that is used to find rare occurrences or suspicious events in your data. The unusual data points may point to a problem or rare event that can be subject to further investigation. Clustering. Common Applications.
It optimises decision trees, probabilistic models, clustering, and reinforcement learning. Entropy enhances clustering, federated learning, finance, and bioinformatics. Mathematical Definition and Formula of Entropy The mathematical formula for entropy H(X) is: Here: P(xi) is the probability of the iii-th event.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. SageMaker features and capabilities help developers and data scientists get started with naturallanguageprocessing (NLP) on AWS with ease.
We add the record identifier model_year_status and event time ingest_time to this feature group. Add the event time to the ingest_time column. Run the @feature_processor code remotely In this section, we demonstrate running the feature processing code remotely as a Spark application using the @remote decorator described earlier.
PBAs, such as graphics processing units (GPUs), have an important role to play in both these phases. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. Additionally, rate of manufacturing is slow, with an H100 taking 6 months to make.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately?
Third-generation Tensor Cores have accelerated AI tasks, leading to breakthroughs in image recognition, naturallanguageprocessing, and speech recognition. Below, 8 different A100 hardware configurations are compared for the same NaturalLanguageProcessing (NLP) inference. How Many Are Needed?
This event frequently occurs in video streaming platforms that constantly purchase a variety of content from multiple vendors and production companies for a limited time. OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing trillions of requests per month.
The figure below illustrates a high-level overview of our asynchronous event-driven architecture. Step 3 The S3 bucket is configured to trigger an event when the user uploads the input content. This notification is sent to an Amazon SQS queue and handled by a Lambda function called Process Input.
Will this novel toolset help professionals NVIDIA’s AI Tools Suite Is Built for Humanoid Robotics NVIDIA’s suite of AI tools was announced by co-founder and chief executive officer Jensen Huang at the annual Special Interest Group on Computer Graphics and Interactive Techniques event in 2024. Interested in attending an ODSC event?
The model assumes that the future state depends only on the current state, not on the sequence of events that preceded it—a property known as the Markov property. GMMs are adequate for clustering and density estimation tasks. NaturalLanguageProcessing (NLP) In NLP , probabilistic models enhance text understanding and generation.
For example, Modularizing a naturallanguageprocessing (NLP) model for sentiment analysis can include separating the word embedding layer and the RNN layer into separate modules, which can be packaged and reused in other NLP models to manage code and reduce duplication and computational resources required to run the model.
Similar Audio: Audio recordings of the same event or sound but with different microphone placements or background noise. Clustering: Clustering can group texts using features like embedding vectors or TF-IDF vectors. Duplicate texts naturally tend to fall into the same clusters. Clustering Techniques (e.g.,
These solutions use data clustering, historical data, and present-derived features to create a multivariate time-series forecasting framework. phData implemented an end-to-end trend scoring methodology using NaturalLanguageProcessing and forecasting techniques that involved human-in-the-loop feedback.
Generative language models have proven remarkably skillful at solving logical and analytical naturallanguageprocessing (NLP) tasks. The resulting Amazon S3 events trigger a Lambda function that inserts a message to an SQS queue. Furthermore, the use of prompt engineering can notably enhance their performance.
Diagnostic Analytics Projects: Diagnostic analytics seeks to determine the reasons behind specific events or patterns observed in the data. 3. Predictive Analytics Projects: Predictive analytics involves using historical data to predict future events or outcomes. Root cause analysis is a typical diagnostic analytics task.
NaturalLanguageProcessing (NLP) has emerged as a dominant area, with tasks like sentiment analysis, machine translation, and chatbot development leading the way. Clustering methods are similarly important, particularly for grouping data into meaningful segments without predefined labels.
Includes statistical naturallanguageprocessing techniques. It simplifies complex AI topics like clustering , dimensionality , and regression , providing practical examples and numeric calculations to enhance understanding. Key Features: Explains AI algorithms like clustering and regression.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. Interested in attending an ODSC event? Learn more about our upcoming events here.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content