This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It is practically impossible to test it on every single member of the population. Inferential statistics employ techniques such as hypothesistesting and regression analysis (also discussed later) to determine the likelihood of observed patterns occurring by chance and to estimate population parameters.
This plot is particularly useful for tasks like hypothesistesting, anomaly detection, and model evaluation. Bias-Variance tradeoff: Understanding the tradeoff between bias and variance is fundamental in machinelearning. It plots the variance explained as a function of the number of clusters.
Statistical analysis and hypothesistesting Statistical methods provide powerful tools for understanding data. Hypothesistesting, correlation, and regression analysis, and distribution analysis are some of the essential statistical tools that data scientists use.
Machinelearning engineer vs data scientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machinelearning engineers and data scientists have gained prominence.
They can be used to test hypotheses, estimate parameters, and make predictions. Machinelearning is a field of computer science that uses statistical techniques to build models from data. These algorithms learn patterns from labeled training data and generalize those patterns to make predictions on unseen data.
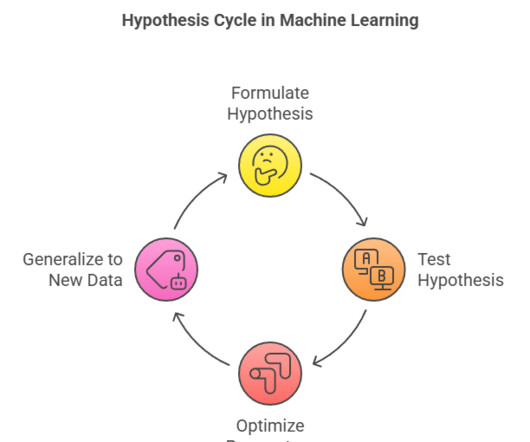
Summary: In MachineLearning, a hypothesis represents a candidate model mapping inputs to outputs. It guides algorithms in testing assumptions, optimizing parameters, and minimizing errors. It guides algorithms in testing assumptions, optimizing parameters, and minimizing errors.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion in 2022 and is expected to grow to USD 505.42
Familiarity with basic programming concepts and mathematical principles will significantly enhance your learning experience and help you grasp the complexities of Data Analysis and MachineLearning. Basic Programming Concepts To effectively learn Python, it’s crucial to understand fundamental programming concepts.
Second, advancements in technology, such as big data and machinelearning, have made it easier and more efficient to analyze data. A strong foundation in statistics is crucial to apply statistical methods and models to analysis, including concepts like hypothesistesting, regression, and clustering analysis.
Machinelearning The 6 key trends you need to know in 2021 ? They bring deep expertise in machinelearning , clustering , natural language processing , time series modelling , optimisation , hypothesistesting and deep learning to the team. Download the free, unabridged version here.
They cover a wide range of topics, ranging from Python, R, and statistics to machinelearning and data visualization. These bootcamps are focused training and learning platforms for people. Nowadays, individuals tend to opt for bootcamps for quick results and faster learning of any particular niche.
This means that as the sample size increases, the distribution of the sum or average becomes more tightly clustered around the mean of the distribution, and the shape of the distribution becomes more bell-shaped. One of the most important applications is hypothesistesting. [I
Summary: Python simplicity, extensive libraries like Pandas and Scikit-learn, and strong community support make it a powerhouse in Data Analysis. It excels in data cleaning, visualisation, statistical analysis, and MachineLearning, making it a must-know tool for Data Analysts and scientists.
Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, MachineLearning algorithms, and data manipulation techniques. Explain the bias-variance tradeoff in MachineLearning. Here is a brief description of the same.
Parameters thus serve as the foundation for hypothesistesting, predictive modelling, and decision-making. Low standard deviation suggests that most values cluster around the mean, while high standard deviation indicates a broader spread. Do you know about the types and components of statistical modelling ?
This could be linear regression, logistic regression, clustering , time series analysis , etc. Reinforcement Learning: Reinforcement learning is a machinelearning paradigm where an agent learns to take actions in an environment to maximize cumulative rewards.
Hence, you can use R for classification, clustering, statistical tests and linear and non-linear modelling. It provides a comprehensive suite of tools, libraries, and packages specifically designed for statistical analysis, data manipulation, visualization, and machinelearning. How is R Used in Data Science?
In Inferential Statistics, you can learn P-Value , T-Value , HypothesisTesting , and A/B Testing , which will help you to understand your data in the form of mathematics. Performance Metrics These are used to evaluate the performance of a machine-learning algorithm.
Whether you’re venturing into machinelearning, predictive analytics, or data visualization, honing the following top Data Science skills is essential for success. Leveraging libraries such as Scikit-learn and TensorFlow, Data Scientists can implement machinelearning algorithms with ease and precision.
Mastering programming, statistics, MachineLearning, and communication is vital for Data Scientists. A typical Data Science syllabus covers mathematics, programming, MachineLearning, data mining, big data technologies, and visualisation. Summary: Data Science is becoming a popular career choice.
Proficient in programming languages like Python or R, data manipulation libraries like Pandas, and machinelearning frameworks like TensorFlow and Scikit-learn, data scientists uncover patterns and trends through statistical analysis and data visualization. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
By understanding crucial concepts like MachineLearning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
Artificial Intelligence, on the other hand, refers to the simulation of human intelligence in machines programmed to think and learn like humans. AI encompasses various subfields, including MachineLearning (ML), Natural Language Processing (NLP), robotics, and computer vision.
Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers. Statistical Analysis Introducing statistical methods and techniques for analysing data, including hypothesistesting, regression analysis, and descriptive statistics.
Clustering: Grouping similar data points to identify segments within the data. Techniques HypothesisTesting: Determining whether enough evidence supports a specific claim or hypothesis. MachineLearning: Utilising algorithms that improve predictions through learning from data.
Concepts such as probability distributions, hypothesistesting, and regression analysis are fundamental for interpreting data accurately. MachineLearning Understanding MachineLearning algorithms is essential for predictive analytics. Ensuring data quality is vital for producing reliable results.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, MachineLearning, Natural Language Processing , Statistics and Mathematics. Learn probability, testing for hypotheses, regression, classification, and grouping, among other topics.
MachineLearningMachineLearning (ML) is a crucial component of Data Science. It enables computers to learn from data without explicit programming. Deep Learning: Advanced neural networks drive Deep Learning , allowing AI to process vast amounts of data and recognise complex patterns.
Modeling & Algorithms: Applying statistical models (like regression, classification, clustering) or MachineLearning algorithms to identify deeper patterns, make predictions, or classify data points. Pattern & Trend Spotting: Makes it easier to identify relationships, trends over time, clusters, and anomalies.
It covers essential topics such as SQL queries, data visualization, statistical analysis, machinelearning concepts, and data manipulation techniques. Statistical Analysis: Learn the Central Limit Theorem, correlation, and basic calculations like mean, median, and mode. The median is the middle value in a sorted list of numbers.
They will quantify these impacts by calculating lap times, identifying strategic patterns, and validating their findings with hypothesistesting. Participants will use EDA and statistical analysis to understand how tire management and pit stop decisions impact race outcomes.
Showcase Diverse Skills: Include projects that highlight different aspects of data analysis, such as Data Cleaning, visualization, statistical analysis, predictive modeling, or machinelearning. These languages offer a large variety of libraries and packages made for machinelearning, data analysis, and data manipulation.
Developing predictive models using MachineLearning Algorithms will be a crucial part of your role, enabling you to forecast trends and outcomes. Techniques like regression analysis, hypothesistesting , and clustering help uncover patterns and relationships within the data.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machinelearning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science? What is a random forest?
By visualizing data distributions, scatter plots, or heatmaps, data scientists can quickly identify outliers, clusters, or trends that might go unnoticed in raw data. It helps in illustrating data transformations, statistical techniques, or MachineLearning algorithms in a visual and intuitive manner.
MachineLearning Inference is a critical aspect of applying trained models to real-world data. Understanding the inference process enhances our ability to utilize machinelearning effectively and navigate the complexities of data-driven technologies. What is machinelearning inference?
It finds its relevance across various fields, particularly in statistics and machinelearning, offering insights into the behavior of different datasets. Applications of Hellinger distance Hellinger Distance has diverse applications in both statistics and machinelearning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content