This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Clustering algorithms play a vital role in the landscape of machine learning, providing powerful techniques for grouping various data points based on their intrinsic characteristics. What are clustering algorithms? Key criteria include: The number of clusters data points can belong to.
Now, researchers from MIT, Microsoft, and Google are attempting to do just that with I-Con, or Information Contrastive Learning. Each guest (data point) finds a seat (cluster) ideally near friends (similar data). The architecture behind I-Con At its core, I-Con is built on an information-theoretic foundation.
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. The major components of RELand are illustrated in Fig.
Now, for this weeks issue, we have a very interesting article on information theory, exploring self-information, entropy, cross-entropy, and KL divergence these concepts bridge probability theory with real-world applications. Ill attend many discussions and am excited to meet some of you there.
From organizing vast datasets to finding similarities among complex information, unsupervised learning plays a pivotal role in enhancing decision-making processes and operational efficiencies. Autonomous classification Unsupervised learning allows systems to effectively group unsorted information. What is unsupervised learning?
It’s like having a super-powered tool to sort through information and make better sense of the world. By comprehending these technical aspects, you gain a deeper understanding of how regression algorithms unveil the hidden patterns within your data, enabling you to make informed predictions and solve real-world problems.
What is K Means Clustering K-Means is an unsupervised machine learning approach that divides the unlabeled dataset into various clusters. K stands for clustering, which divides data points into K clusters based on how far apart they are from each other’s centres.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Elbow curve: In unsupervised learning, particularly clustering, the elbow curve aids in determining the optimal number of clusters for a dataset. It plots the variance explained as a function of the number of clusters. The “elbow point” is a good indicator of the ideal cluster count.
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. Each book is a unique piece of information, and your goal is to organize them based on their characteristics. This is called clustering. As… Read the full blog for free on Medium.
The company’s projection of a $6090 billion AI market by 2027 is contingent on aggressive cluster deployments and sustained capital expenditure, factors that may not fully materialize. However, this growth assumes ideal conditionssustained capital expenditures, aggressive cluster deployments, and limited disruption from competitors.
Solution overview The steps to implement the solution are as follows: Create the EKS cluster. For more information on how to view and increase your quotas, refer to Amazon EC2 service quotas. Create the EKS cluster If you don’t have an existing EKS cluster, you can create one using eksctl. Prepare the Docker image.
Convert your graph to a clustering-friendly format with this article. Motivation· Installing the required packages:· Assumptions· Deepwalk/Node2vec· GNNs· LINE· Apply clustering to the embeddings· Conclusion· References Using a graph can be a good way of encoding lots of information. . ChatGPT, OpenAI, 30 Jan.
In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. It involves multiple data handling processes, like updating, deleting, or changing information. IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster.
They constitute essential tools for statistical analysis, hypothesis testing, and predictive modeling, furnishing a systematic approach to evaluate, analyze, and make informed decisions in scenarios involving randomness and unpredictability. It’s like continually refining your knowledge as you gather more data.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
The first vase was a cluster of four vessels, all at different levels For the exhibition, Front presented the three vases alongside the sketches they were based on. This involved feeding it information and images of objects they had previously designed so it would learn their style and approach.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
From vCenter, administrators can configure and control ESXi hosts, datacenters, clusters, traditional storage, software-defined storage, traditional networking, software-defined networking, and all other aspects of the vSphere architecture. VMware “clustering” is purely for virtualization purposes.
Analysts can use this information to provide incentives to buyers and sellers who frequently use the site, to attract new users, and to drive advertising and promotions. You’re now ready to sign in to both Aurora MySQL cluster and Amazon Redshift Serverless data warehouse and run some basic commands to test them. Port: Redshift 5439.
Retrieval Augmented Generation (RAG) is a widely used approach that solves real-world data problems by amalgamating the power of Generative AI and Information Retrieval. Feeding of the augmented information is crucial because otherwise the AI might generate some random information as it doesnt have any context of what has been asked.
Stage 2: Introduction of neural networks The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
our feed and ranking models) that would ingest vast amounts of information to make accurate recommendations that power most of our products. The number of failures scales with the size of the cluster, and having a job that spans the cluster makes it necessary to keep adequate spare capacity to restart the job as soon as possible.
It excels in soft clustering, handling overlapping clusters, and modelling diverse cluster shapes. Its ability to model complex, multimodal data distributions makes it invaluable for clustering , density estimation, and pattern recognition tasks. GMM handles overlapping and non-spherical clusters better than K-Means.
For this analysis we will only use the first two components, the result is a two-dimensional plot where similar operating conditions cluster together, besides the two main components we will use a gradient to represent the Remaining Useful Life (RUL). Ordering components by how much variance they explain. Source: Image by the author.
This conversational agent offers a new intuitive way to access the extensive quantity of seed product information to enable seed recommendations, providing farmers and sales representatives with an additional tool to quickly retrieve relevant seed information, complementing their expertise and supporting collaborative, informed decision-making.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.
Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We use this cluster design for Llama 3 training. We built these clusters on top of Grand Teton , OpenRack , and PyTorch and continue to push open innovation across the industry. The other cluster features an NVIDIA Quantum2 InfiniBand fabric.
Hadoop has become synonymous with big data processing, transforming how organizations manage vast quantities of information. Hadoop is an open-source framework that supports distributed data processing across clusters of computers. This architecture allows efficient file access and management within a cluster environment.
This is used for tasks like clustering, dimensionality reduction, and anomaly detection. For example, clustering customers based on their purchase history to identify different customer segments. Feature engineering: Creating informative features can help reduce bias and improve model performance.
Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information. Working with vector data is tough because regular databases, which usually handle one piece of information at a time, can’t handle the complexity and large amount of this type of data.
However, this approach has several shortcomings: Loss of information : When biological relationships are reduced to numerical adjacency matrices, much of the detailed context is lost. Gene set enrichment : Identify clusters of genes that behave similarly under perturbations and describe their common function.
It is an AI framework and a type of natural language processing (NLP) model that enables the retrieval of information from an external knowledge base. It ensures that the information is more accurate and up-to-date by combining factual data with contextually relevant information.
Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python. It provides a wide range of tools for supervised and unsupervised learning, including linear regression, k-means clustering, and support vector machines.
The purpose of data archiving is to ensure that important information is not lost or corrupted over time and to reduce the cost and complexity of managing large amounts of data on primary storage systems. This information helps organizations understand what data they have, where it’s located, and how it can be used.
They scan and store information across long sequences, but as context length grows (think thousands of words), this approach becomes incredibly slow and computationally heavy. To address this, researchers have explored Sparse Attention which selectively processes only the most important information instead of everything.
Harnessing orthogonal multi-omic information, this model successfully generates molecular and phenotypic profiles, resulting in an increase of 32.7% Here, the authors develop MOSA, a method designed to augment DepMap cell line data to synthetically generate multiomics data, increase efficacy of cell clustering and biomarker identification.
They are also used in machine learning, such as support vector machines and k-means clustering. Robust inference: Robust inference is a technique that is used to make inferences that are not sensitive to outliers or extreme observations. This technique is often used in cases where the data is contaminated with errors or outliers.
The capacity of a neural network to absorb information is limited by its number of parameters. In this work, we address these challenges and finally realize the promise of conditional computation, achieving greater than 1000x improvements in model capacity with only minor losses in computational efficiency on modern GPU clusters.
Kafka is based on the idea of a distributed commit log, which stores and manages streams of information that can still work even […] The post Build a Scalable Data Pipeline with Apache Kafka appeared first on Analytics Vidhya. It was made on LinkedIn and shared with the public in 2011.
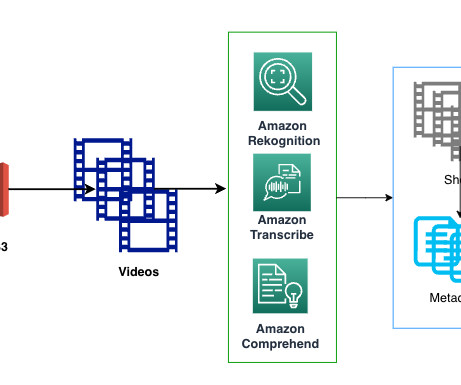
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. The goal of this processing is to aggregate useful information and remove null or less significant information that wouldn’t add value for embedding generation.
As the number of dimensions increases, the volume of the space increases exponentially, making it challenging to find patterns or clusters. This process not only helps in retaining the most informative aspects of the data but also streamlines the training process, making it faster and less resource-intensive.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content