

Traditional vs Vector databases: Your guide to make the right choice
Data Science Dojo
MARCH 8, 2024
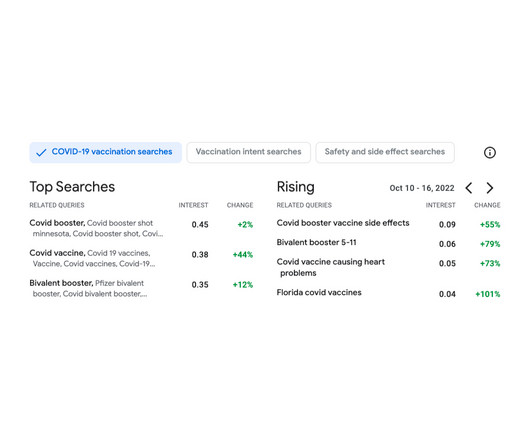
In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. It involves multiple data handling processes, like updating, deleting, or changing information. IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster.













































Let's personalize your content