This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both ML Algorithms, and we’ll explore them more in detail in a bit. They are both ML Algorithms, and we’ll explore them more in detail in a bit.
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
The K-NearestNeighbors Algorithm Math Foundations: Hyperplanes, Voronoi Diagrams and Spacial Metrics. Diagram 1 Phenoms and 57s are both clustered around their respective centroids. Clustering methods are a hot topic in data analisys 2.3 K-NearestNeighbors Suppose that a new aircraft is being made.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster.
k-NearestNeighbors (k-NN) k-NN is a simple algorithm that classifies new instances based on the majority class among its knearest neighbours in the training dataset. K-Means ClusteringK-means clustering partitions data into k distinct clusters based on feature similarity.
The implementation included a provisioned three-node sharded OpenSearch Service cluster. Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks. Each provisioned node was r7g.4xlarge, FloTorch used HSNW indexing in OpenSearch Service.
Machine learning (ML) has proven that it is here with us for the long haul, everyone who had their doubts by calling it a phase should by now realize how wrong they are, ML has being used in various sector’s of society such as medicine, geospatial data, finance, statistics and robotics.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? This will be a good way to get familiar with ML. Types of Machine Learning for GIS 1.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
To further boost these capabilities, OpenSearch offers advanced features, such as: Connector for Amazon Bedrock You can seamlessly integrate Amazon Bedrock machine learning (ML) models with OpenSearch through built-in connectors for services, enabling direct access to advanced ML features. For data handling, 24 data nodes (r6gd.2xlarge.search
To search against the database, you can use a vector search, which is performed using the k-nearestneighbors (k-NN) algorithm. With Amazon OpenSearch Serverless, you don’t need to provision, configure, and tune the instance clusters that store and index your data.
ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning. How is it actually looks in a real life process of ML investigation? Unsupervised learning Unsupervised learning is applied with clustering models with unlabeled data, so our goal is to detect new features and patterns.
There are different kinds of unsupervised learning algorithms, including clustering, anomaly detection, neural networks, etc. The algorithms will perform the task using unsupervised learning clustering, allowing the dataset to divide into groups based on the similarities between images. It can be either agglomerative or divisive.
In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). Prerequisites. Deploy the solution as a local web application.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. PyTorch is an open-source ML framework that accelerates the path from research prototyping to production deployment. You can use CLIP with Amazon SageMaker to perform encoding.
As Data Scientists, we all have worked on an ML classification model. In this article, we will talk about feasible techniques to deal with such a large-scale ML Classification model. In this article, you will learn: 1 What are some examples of large-scale ML classification models? Let’s take a look at some of them.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. And effectively in the latent space, they form kind of tight clusters for these unseen concepts that are very well-connected components.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. And effectively in the latent space, they form kind of tight clusters for these unseen concepts that are very well-connected components.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. And effectively in the latent space, they form kind of tight clusters for these unseen concepts that are very well-connected components.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. In this post, we deep dive into the technical details of this ML model.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module.
For more information, see Creating connectors for third-party ML platforms. Create an OpenSearch model When you work with machine learning (ML) models, in OpenSearch, you use OpenSearchs ml-commons plugin to create a model. You created an OpenSearch ML model group and model that you can use to create ingest and search pipelines.
This harmonization is particularly critical in algorithms such as k-NearestNeighbors and Support Vector Machines, where distances dictate decisions. To start your learning journey in Machine Learning, you can opt for a free course in ML. Having expertise in this domain will give you an edge over your competitors.
On the other hand, 48% use ML and AI for gaining insights into the prospects and customers. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. It identifies regions of high data point density as clusters and flags points with low densities as anomalies.
This can lead to enhancing accuracy but also increasing the efficiency of downstream tasks such as classification, retrieval, clusterization, and anomaly detection, to name a few. This can lead to higher accuracy in tasks like image classification and clusterization due to the fact that noise and unnecessary information are reduced.
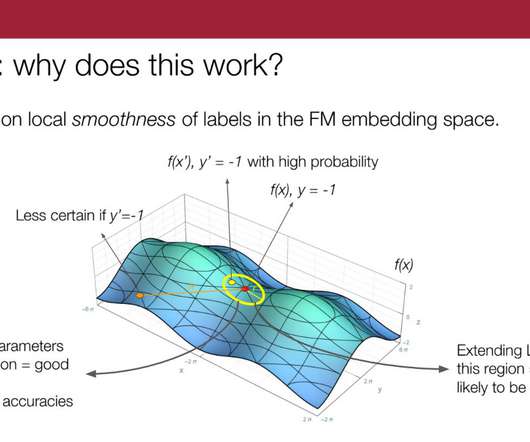
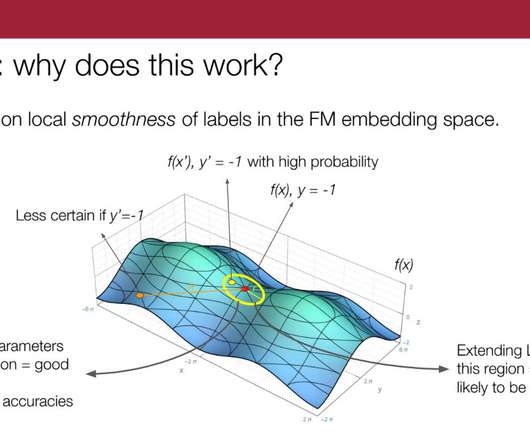
We tackle that by learning these clusters in the foundation models embedding space and providing those clusters as the subgroups—and basically learning a weak supervision model on each of those clusters. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
We tackle that by learning these clusters in the foundation models embedding space and providing those clusters as the subgroups—and basically learning a weak supervision model on each of those clusters. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
The sub-categories of this approach are negative sampling, clustering, knowledge distillation, and redundancy reduction. Some common quantitative evaluations are linear probing , Knearestneighbors (KNN), and fine-tuning. D BECOME a WRITER at MLearning.ai // invisible ML // Detect AI img Mlearning.ai
How to perform Face Recognition using KNN So in this blog, we will see how we can perform Face Recognition using KNN (K-NearestNeighbors Algorithm) and Haar cascades. Checkout the code walkthrough [link] 13. Haar cascades are very fast as compared to other ways of detecting faces (like MTCNN) but with an accuracy tradeoff.
How to perform Face Recognition using KNN So in this blog, we will see how we can perform Face Recognition using KNN (K-NearestNeighbors Algorithm) and Haar cascades. Checkout the code walkthrough [link] 13. Haar cascades are very fast as compared to other ways of detecting faces (like MTCNN) but with an accuracy tradeoff.
Most dominant colors in an image using KMeans clustering In this blog, we will find the most dominant colors in an image using the K-Means clustering algorithm, this is a very interesting project and personally one of my favorites because of its simplicity and power. It can also be thought of as the ‘Hello World of ML world.
This allows it to evaluate and find relationships between the data points which is essential for clustering. They are: Based on shallow, simple, and interpretable machine learning models like support vector machines (SVMs), decision trees, or k-nearestneighbors (kNN).
There are majorly two categories of sampling techniques based on the usage of statistics, they are: Probability Sampling techniques: Clustered sampling, Simple random sampling, and Stratified sampling. It is introduced into an ML Model when an ML algorithm is made highly complex. Define bias-variance trade-off? What will you do?
Feature vectors play a central role in the world of machine learning (ML), serving as the backbone of data representation in various applications. Feature vector vs. feature map While feature vectors and feature maps serve similar purposes in ML, they have distinct roles that are important to understand.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content