This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. Enter KNearestNeighbor (k-NN), a technique that personifies the very essence of propinquity and Neighborly dynamics.
The K-NearestNeighbors Algorithm Math Foundations: Hyperplanes, Voronoi Diagrams and Spacial Metrics. Diagram 1 Phenoms and 57s are both clustered around their respective centroids. Clustering methods are a hot topic in data analisys 2.3 K-NearestNeighbors Suppose that a new aircraft is being made.
We shall look at various types of machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. R Studios and GIS In a previous article, I wrote about GIS and R.,
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Common machine learning algorithms for supervised learning include: K-nearestneighbor (KNN) algorithm : This algorithm is a density-based classifier or regression modeling tool used for anomaly detection. “Means,” or average data, refers to the points in the center of the cluster that all other data is related to.
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. This method takes a parameter, which we set to 3.
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. This is one of the best Machine learning projects in Python. Doctor-Patient Appointment System in Python using Flask Hey guys, in this blog we will see a Doctor-Patient Appointment System for Hospitals built in Python using Flask.
In this comprehensive article, we delve into the depths of feature scaling in Machine Learning, uncovering its importance, methods, and advantages while showcasing practical examples using Python. Understanding Feature Scaling in Machine Learning: Feature scaling stands out as a fundamental process.
Python The code has been tested with Python version 3.13. For clarity of purpose and reading, weve encapsulated each of seven steps in its own Python script. Return to the command line, and execute the script: python create_invoke_role.py Return to the command line and execute the script: python create_connector_role.py
OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing trillions of requests per month. Initializes the OpenSearch Service client using the Boto3 Python library. We use the streamlit Python package to create a front-end illustration for this application.
Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (Data Science) kernel to run the sample code. Pandas is an open-source data analysis and manipulation tool built on top of the Python programming language. For this post, we use the Amazon Berkeley Objects Dataset. unsqueeze(0).to(device)
Further, it will provide a step-by-step guide on anomaly detection Machine Learning python. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. It identifies regions of high data point density as clusters and flags points with low densities as anomalies.
Youtube Comments Extraction and Sentiment Analysis Flask App Hey, guys in this blog we will implement Youtube Comments Extraction and Sentiment Analysis in Python using Flask. This is one of the best Machine learning projects with source code in Python. It is going to be a very interesting project. Working Video of our App [link] 20.
This is one of the best Machine Learning Projects for final year in Python. Youtube Comments Extraction and Sentiment Analysis Flask App Hey, guys in this blog we will implement Youtube Comments Extraction and Sentiment Analysis in Python using Flask. Main Screen Result Screen Working Video of our App [link] 3.
Clustering: An unsupervised Machine Learning technique that groups similar data points based on their inherent similarities. D Data Mining : The process of discovering patterns, insights, and knowledge from large datasets using various techniques such as classification, clustering, and association rule learning.
Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. customer segmentation), clustering algorithms like K-means or hierarchical clustering might be appropriate.
This allows it to evaluate and find relationships between the data points which is essential for clustering. They are: Based on shallow, simple, and interpretable machine learning models like support vector machines (SVMs), decision trees, or k-nearestneighbors (kNN).
There are majorly two categories of sampling techniques based on the usage of statistics, they are: Probability Sampling techniques: Clustered sampling, Simple random sampling, and Stratified sampling. The K-NearestNeighbor Algorithm is a good example of an algorithm with low bias and high variance.
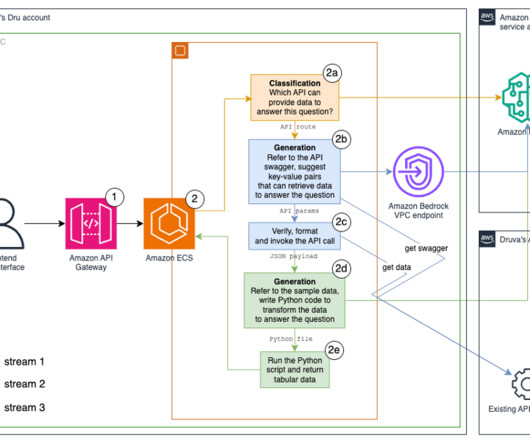
Generate and run data transformation Python code. We tried different methods, including k-nearestneighbor (k-NN) search of vector embeddings, BM25 with synonyms , and a hybrid of both across fields including API routes, descriptions, and hypothetical questions. Generate and invoke private API calls.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content