This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Latent Semantic Analysis and its Uses in NaturalLanguageProcessing appeared first on Analytics Vidhya. Textual data, even though very important, vary considerably in lexical and morphological standpoints. Different people express themselves quite differently when it comes to […].
IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster. A file records vectors that belong to each cluster. It enables comparison and detailed data search within clusters. While HNSW speeds up the process, IVF also increases its efficiency.
Classification in machinelearning involves the intriguing process of assigning labels to new data based on patterns learned from training examples. Machinelearning models have already started to take up a lot of space in our lives, even if we are not consciously aware of it.
Here are some key ways data scientists are leveraging AI tools and technologies: 6 Ways Data Scientists are Leveraging Large Language Models with Examples Advanced MachineLearning Algorithms: Data scientists are utilizing more advanced machinelearning algorithms to derive valuable insights from complex and large datasets.
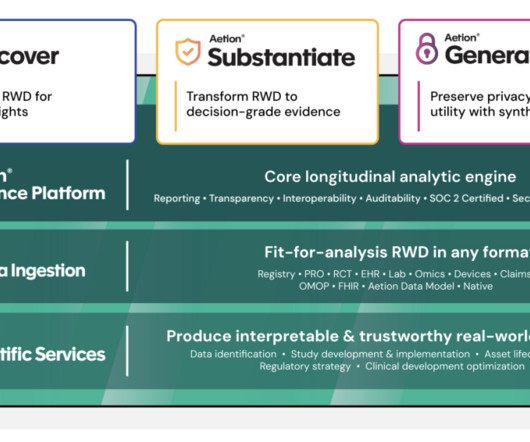
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.
Python machinelearning packages have emerged as the go-to choice for implementing and working with machinelearning algorithms. These libraries, with their rich functionalities and comprehensive toolsets, have become the backbone of data science and machinelearning practices.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
By leveraging GenAI, we can streamline and automate data-cleaning processes: Clean data to use AI? Three ways to use GenAI for better data Improving data quality can make it easier to apply machinelearning and AI to analytics projects and answer business questions. Clean data through GenAI!
These professionals venture into new frontiers like machinelearning, naturallanguageprocessing, and computer vision, continually pushing the limits of AI’s potential. This is used for tasks like clustering, dimensionality reduction, and anomaly detection.
Last Updated on June 27, 2023 by Editorial Team Source: Unsplash This piece dives into the top machinelearning developer tools being used by developers — start building! In the rapidly expanding field of artificial intelligence (AI), machinelearning tools play an instrumental role.
In this blog post, we’ll explore five project ideas that can help you build expertise in computer vision, naturallanguageprocessing (NLP), sales forecasting, cancer detection, and predictive maintenance using Python.
In our test environment, we observed 20% throughput improvement and 30% latency reduction across multiple naturallanguageprocessing models. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
Read a comprehensive SQL guide for data analysis; Learn how to choose the right clustering algorithm for your data; Find out how to create a viral DataViz using the data from Data Science Skills poll; Enroll in any of 10 Free Top Notch NaturalLanguageProcessing Courses; and more.
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using NaturalLanguageProcessing (NLP) or more specific from Named-Entity Recognition (NER).
Beginner’s Guide to ML-001: Introducing the Wonderful World of MachineLearning: An Introduction Everyone is using mobile or web applications which are based on one or other machinelearning algorithms. You might be using machinelearning algorithms from everything you see on OTT or everything you shop online.
Well, it’s NaturalLanguageProcessing which equips the machines to work like a human. But there is much more to NLP, and in this blog, we are going to dig deeper into the key aspects of NLP, the benefits of NLP and NaturalLanguageProcessing examples. What is NLP?
der k-Nächste-Nachbarn -Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering. Die Texte müssen in diese transformiert werden, eventuell auch nach diesen in Cluster eingeteilt und für verschiedene Trainingsszenarien separiert werden. Die Ähnlichkeitsbetrachtung erfolgt mit Distanzmessung im Vektorraum.
It is used for machinelearning, naturallanguageprocessing, and computer vision tasks. Scikit-learn Scikit-learn is an open-source machinelearning library for Python. It is easy to learn and use, even for beginners. It is open-source, so it is free to use and modify.
Machinelearning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors.
By leveraging statistical techniques and machinelearning, organizations can forecast future trends based on historical data. Through various statistical methods and machinelearning algorithms, predictive modeling transforms complex datasets into understandable forecasts.
Pinecone is a vector database that is designed for machinelearning applications. It is fast, scalable, and supports a variety of machinelearning algorithms. Faiss is a library for efficient similarity search and clustering of dense vectors. Milvus is used by companies such as Alibaba, Baidu, and Tencent.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
There are several techniques used in intelligent data classification, including: Machinelearning : Machinelearning algorithms can be trained on large datasets to recognize patterns and categories within the data. These algorithms can learn from the data itself, adapting and improving over time as they analyze more data.
Basics of MachineLearning. Machinelearning is the science of building models automatically. Whereas in machinelearning, the algorithm understands the data and creates the logic. Whereas in machinelearning, the algorithm understands the data and creates the logic. Semi-Supervised Learning.
Summary: Linear Algebra is foundational to MachineLearning, providing essential operations such as vector and matrix manipulations. Introduction Linear Algebra is a fundamental mathematical discipline that underpins many algorithms and techniques in MachineLearning.
Machinelearning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale. The following figure shows how FSDP works for two data parallel processes.
You can find it in the turning of the seasons, in the way sand trails along a ridge, in the branch clusters of the creosote bush or the pattern of its leaves. Yet, it is possible to see peril in the finding of ultimate perfection. .” ~ Dune (1965) I find the concept of embeddings to be one of the most fascinating ideas in machinelearning.
MachineLearning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. What is Classification?
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machinelearning (ML) and analytics solutions in R at scale. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. 1 NAT gateway.
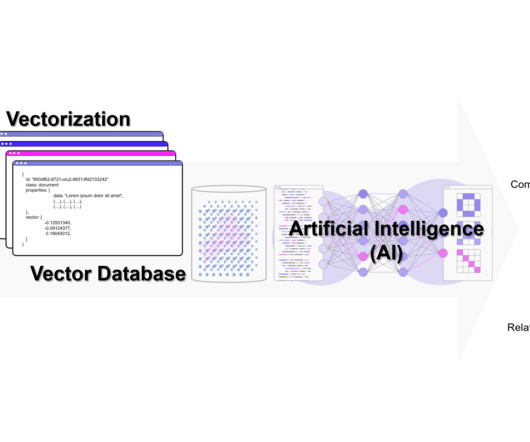
Embeddings play a key role in naturallanguageprocessing (NLP) and machinelearning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. In her free time, she likes to go for long runs along the beach.
Amazon SageMaker enables enterprises to build, train, and deploy machinelearning (ML) models. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Delete the MongoDB Atlas cluster. Set up the database access and network access.
They are set to redefine how developers approach naturallanguageprocessing. Clustering : Employed for grouping text strings based on their similarities, facilitating the organization of related information. The realm of artificial intelligence continues to evolve with New OpenAI embedding models.
MachineLearning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. There are two types of MachineLearning techniques, including supervised and unsupervised learning. What is Unsupervised MachineLearning?
INTRODUCTION MachineLearning is a subfield of artificial intelligence that focuses on the development of algorithms and models that allow computers to learn and make predictions or decisions based on data, without being explicitly programmed. WHAT IS CLUSTERING? Those groups are referred to as clusters.
To keep up with the pace of consumer expectations, companies are relying more heavily on machinelearning algorithms to make things easier. How do artificial intelligence, machinelearning, deep learning and neural networks relate to each other? Machinelearning is a subset of AI.
How this machinelearning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. Thus, this type of task is very important for exploratory data analysis.
As technology continues to impact how machines operate, MachineLearning has emerged as a powerful tool enabling computers to learn and improve from experience without explicit programming. What is MachineLearning? Types of MachineLearning Model: MachineLearning models can be broadly categorized as: 1.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
Summary: MachineLearning Engineer design algorithms and models to enable systems to learn from data. Introduction MachineLearning is rapidly transforming industries. A MachineLearning Engineer plays a crucial role in this landscape, designing and implementing algorithms that drive innovation and efficiency.
If you want a gentle introduction to machinelearning for computer vision, you’re in the right spot. Here at PyImageSearch we’ve been helping people just like you master deep learning for computer vision. Also, you might want to check out our computer vision for deep learning program before you go.
In this post, we explore the concept of querying data using naturallanguage, eliminating the need for SQL queries or coding skills. NaturalLanguageProcessing (NLP) and advanced AI technologies can allow users to interact with their data intuitively by asking questions in plain language.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. Before that, he worked on developing machinelearning methods for fraud detection for Amazon Fraud Detector.
Summary: MachineLearning is categorised into four main types: supervised, unsupervised, semi-supervised, and Reinforcement Learning. Introduction MachineLearning is revolutionising industries by enabling machines to learn from data and make decisions without explicit programming.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content