This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster. A file records vectors that belong to each cluster. It enables comparison and detailed data search within clusters. While HNSW speeds up the process, IVF also increases its efficiency.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster.
Hence, acting as a translator it converts human language into a machine-readable form. Their impact on ML tasks has made them a cornerstone of AI advancements. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings.
Solving Machine Learning Tasks with MLCoPilot: Harnessing Human Expertise for Success Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machine learning code. This is where ML CoPilot enters the scene.
For instance, today’s machine learning tools are pushing the boundaries of naturallanguageprocessing, allowing AI to comprehend complex patterns and languages. These tools are becoming increasingly sophisticated, enabling the development of advanced applications.
Use plain English to build ML models to identify profitable customer segments. In this post, we explore the concept of querying data using naturallanguage, eliminating the need for SQL queries or coding skills. Last Updated on May 9, 2023 by Editorial Team Author(s): Sriram Parthasarathy Originally published on Towards AI.
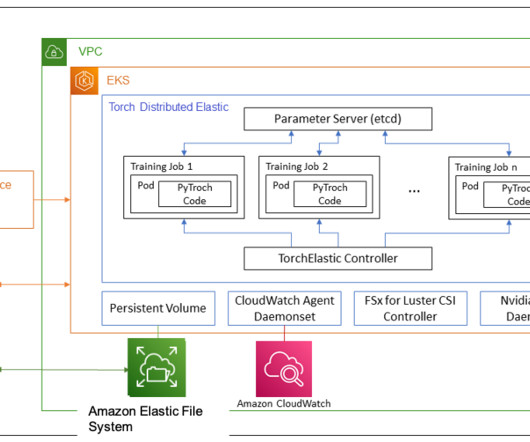
Machine learning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale. The following figure shows how FSDP works for two data parallel processes.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. Solution overview You can use DeepSeeks distilled models within the AWS managed machine learning (ML) infrastructure. Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS.
It is used for machine learning, naturallanguageprocessing, and computer vision tasks. TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs. It is a cloud-based platform, so it can be accessed from anywhere.
Featured Community post from the Discord Aman_kumawat_41063 has created a GitHub repository for applying some basic ML algorithms. It offers pure NumPy implementations of fundamental machine learning algorithms for classification, clustering, preprocessing, and regression. This repo is designed for educational exploration.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. You can then generate focused summaries from those groupings’ content using an LLM.
When Meta introduced distributed GPU-based training , we decided to construct specialized data center networks tailored for these GPU clusters. We have successfully expanded our RoCE networks, evolving from prototypes to the deployment of numerous clusters, each accommodating thousands of GPUs.
Hence, acting as a translator it converts human language into a machine-readable form. Their impact on ML tasks has made them a cornerstone of AI advancements. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings.
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machine learning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
In these cases, the model sizes are smaller, which means the communication overhead with GPUs or ML accelerator instances outweighs their compute performance benefits. As early adopters of Graviton for ML workloads, it was initially challenging to identify the right software versions and the runtime tunings.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. Best practices for ml model packaging Here is how you can package a model efficiently.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs).
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. 3 feature visual representation of a K-means Algorithm.
Using the Neuron Distributed library with SageMaker SageMaker is a fully managed service that provides developers, data scientists, and practitioners the ability to build, train, and deploy machine learning (ML) models at scale. Cluster update is currently enabled for the TRN1 instance family as well as P and G GPU-based instance types.
They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources. Kubernetes’s declarative, API -driven infrastructure has helped free up DevOps and other teams from manually driven processes so they can work more independently and efficiently to achieve their goals.
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. About the Authors Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia.
Our commitment to innovation led us to a pivotal challenge: how to harness the power of machine learning (ML) to further enhance our competitive edge while balancing this technological advancement with strict data security requirements and the need to streamline access to our existing internal resources.
Historically, naturallanguageprocessing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
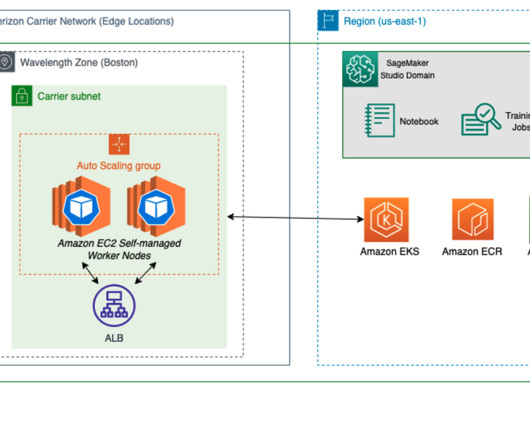
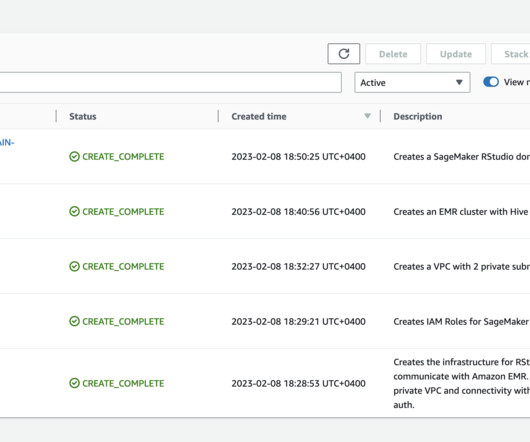
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. 1 Public subnet.
Naturallanguageprocessing, computer vision, data mining, robotics, and other competencies are strengthened in the course. However, you are expected to possess intermediate coding experience and a background as an AI ML engineer; to begin with the course. Generative AI with LLMs course by AWS AND DEEPLEARNING.AI
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. We recently developed four more new models.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. NLTK is appreciated for its broader nature, as it’s able to pull the right algorithm for any job.
As one of the most prominent use cases to date, machine learning (ML) at the edge has allowed enterprises to deploy ML models closer to their end-customers to reduce latency and increase responsiveness of their applications. Even ground and aerial robotics can use ML to unlock safer, more autonomous operations.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process.
Embeddings capture the information content in bodies of text, allowing naturallanguageprocessing (NLP) models to work with language in a numeric form. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. SageMaker Training is a managed batch ML compute service that reduces the time and cost to train and tune models at scale without the need to manage infrastructure. SageMaker-managed clusters of ml.p4d.24xlarge
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Data scientists and data engineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing.
Alida’s customers receive tens of thousands of engaged responses for a single survey, therefore the Alida team opted to leverage machine learning (ML) to serve their customers at scale. The new service achieved a 4-6 times improvement in topic assertion by tightly clustering on several dozen key topics vs. hundreds of noisy NLP keywords.
In our solution, we implement a hyperparameter grid search on an EKS cluster for tuning a bert-base-cased model for classifying positive or negative sentiment for stock market data headlines. A desired cluster can simply be configured using the eks.conf file and launched by running the eks-create.sh to launch the cluster.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content