This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Explainable AI is no longer just an optional add-on when using ML algorithms for corporate decision making. The post Adding Explainability to Clustering appeared first on Analytics Vidhya. Introduction The ability to explain decisions is increasingly becoming important across businesses.
The post Understand The DBSCAN Clustering Algorithm! ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, I’m gonna explain about DBSCAN algorithm. appeared first on Analytics Vidhya.
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters. Create a new training plan.
At the time, I knew little about AI or machine learning (ML). But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML. Panic set in as we realized we would be competing on stage in front of thousands of people while knowing little about ML.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. We use the Time Series Clustering using TSFresh + KMeans notebook, which is available on our GitHub repo.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
It usually comprises parsing log data into vectors or machine-understandable tokens, which you can then use to train custom machine learning (ML) algorithms for determining anomalies. You can adjust the inputs or hyperparameters for an ML algorithm to obtain a combination that yields the best-performing model. scikit-learn==0.21.3
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. As the global Python market is projected to reach USD 100.6
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Ray is an open source framework that makes it straightforward to create, deploy, and optimize distributed Python jobs. At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. We primarily focus on ML training use cases.
Business challenge Today, many developers use AI and machine learning (ML) models to tackle a variety of business cases, from smart identification and natural language processing (NLP) to AI assistants. You can train foundation models (FMs) for weeks and months without disruption by automatically monitoring and repairing training clusters.
GraphStorm is a low-code enterprise graph machine learning (ML) framework that provides ML practitioners a simple way of building, training, and deploying graph ML solutions on industry-scale graph data. billion edges after adding reverse edges. seconds Evaluation Summary Total evaluations: 11 Average evaluation time: 1.90
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
Upcoming Webinars: How to build stunning Data Science Web applications in Python Thu, Feb 23, 2023, 12:00 PM — 1:00 PM EST This webinar presents Taipy, a new low-code Python package that allows you to create complete Data Science applications, including graphical visualization and the management of algorithms, models, and pipelines.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The dataset was stored in an Amazon Simple Storage Service (Amazon S3) bucket, which served as a centralized data repository.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1. Having access to a JupyterLab IDE with Python 3.9, 3.10, or 3.11
Pyspark MLlib | Classification using Pyspark ML In the previous sections, we discussed about RDD, Dataframes, and Pyspark concepts. In this article, we will discuss about Pyspark MLlib and Spark ML. using PySpark we can run applications parallelly on the distributed cluster… blog.devgenius.io
Solution overview SageMaker JumpStart provides FMs through two primary interfaces: Amazon SageMaker Studio and the SageMaker Python SDK. SageMaker Studio is a comprehensive interactive development environment (IDE) that offers a unified, web-based interface for performing all aspects of the machine learning (ML) development lifecycle.
With HyperPod, users can begin the process by connecting to the login/head node of the Slurm cluster. Alternatively, you can also use the AWS CloudFormation template provided in the Own Account workshop and follow the instructions to set up a cluster and a development environment to access and submit jobs to the cluster.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building data pipelines. Their technical skills enable them to build efficient and scalable machine learning solutions.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
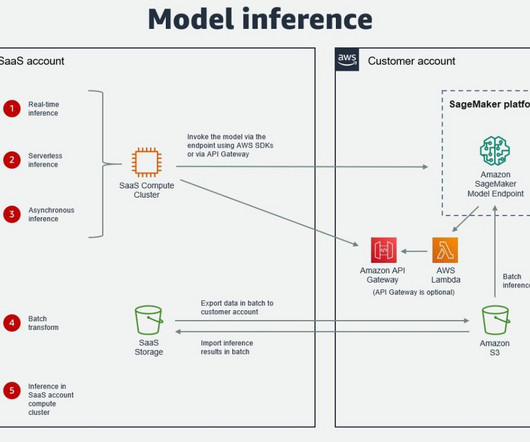
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. There are a few different ways in which authentication across AWS accounts can be achieved when data in the SaaS platform is accessed from SageMaker and when the ML model is invoked from the SaaS platform.
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machine learning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
Extract ‘superpixels’ of an Image using the clustering approach Before we get into the Image Segmentation using K-Means clustering, let’s quickly brush upon the basics. K-Means Clustering The basic underlying idea behind any clustering algorithm is to partition a set of values into a specific number of cluster.
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. He’s the author of the bestselling book “Interpretable Machine Learning with Python,” and the upcoming book “DIY AI.”
Running machine learning (ML) workloads with containers is becoming a common practice. What you get is an ML development environment that is consistent and portable. With containers, scaling on a cluster becomes much easier. Create a task definition to define an ML training job to be run by Amazon ECS.
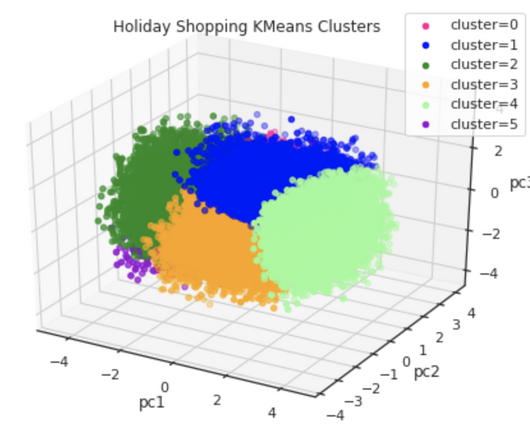
Use plain English to build ML models to identify profitable customer segments. Here is an example plot we will create by just asking in plain English to create 3 clusters (using kmeans) using income and spending variables, and present the breakdown of spending for each cluster without writing any code.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. kubectl for working with Kubernetes clusters.
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. A grid system is established with a 48-meter grid size using Mapbox’s Supermercado Python library at zoom level 19, enabling precise spatial analysis.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
Snowpark ML is transforming the way that organizations implement AI solutions. Snowpark allows ML models and code to run on Snowflake warehouses. By “bringing the code to the data,” we’ve seen ML applications run anywhere from 4-100x faster than other architectures. df = session.table("BBC_ARTICLES").filter(col("CLASS")
However, it lacked essential services required for machine learning (ML) applications, such as frontend and backend infrastructure, DNS, load balancers, scaling, blob storage, and managed databases. With our new model, we first tried performing inference in Python with Flask and PyTorch, as well as with BentoML.
ML models have grown significantly in recent years, and businesses increasingly rely on them to automate and optimize their operations. However, managing ML models can be challenging, especially as models become more complex and require more resources to train and deploy. What is MLOps?
Let’s get started with the best machine learning (ML) developer tools: TensorFlow TensorFlow, developed by the Google Brain team, is one of the most utilized machine learning tools in the industry. PyTorch PyTorch, a Python-based machine learning library, stands out among its peers in the machine learning tools ecosystem.
Azure Machine Learning is Microsoft’s enterprise-grade service that provides a comprehensive environment for data scientists and ML engineers to build, train, deploy, and manage machine learning models at scale. You can explore its capabilities through the official Azure ML Studio documentation. Awesome, right?
It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. TensorFlow was also used by Netflix to improve its recommendation engine. PyTorch PyTorch is another open-source software library for numerical computation using data flow graphs.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs).
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. Best practices for ml model packaging Here is how you can package a model efficiently.
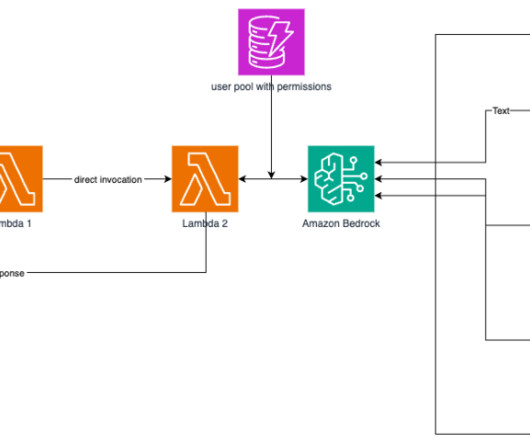
Our commitment to innovation led us to a pivotal challenge: how to harness the power of machine learning (ML) to further enhance our competitive edge while balancing this technological advancement with strict data security requirements and the need to streamline access to our existing internal resources.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. What does a modern technology stack for streamlined ML processes look like?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content