This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Latent Semantic Analysis and its Uses in NaturalLanguageProcessing appeared first on Analytics Vidhya. Textual data, even though very important, vary considerably in lexical and morphological standpoints. Different people express themselves quite differently when it comes to […].
The new HPE system is optimized to quickly deploy high-performing, secure and energy efficient AI clusters for use in large language model training, naturallanguageprocessing and multi-modal training.
IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster. A file records vectors that belong to each cluster. It enables comparison and detailed data search within clusters. While HNSW speeds up the process, IVF also increases its efficiency.
Researchers, data scientists, and machine learning practitioners alike have embraced t-SNE for its effectiveness in transforming extensive datasets into visual representations, enabling a clearer understanding of relationships, clusters, and patterns within the data.
Read a comprehensive SQL guide for data analysis; Learn how to choose the right clustering algorithm for your data; Find out how to create a viral DataViz using the data from Data Science Skills poll; Enroll in any of 10 Free Top Notch NaturalLanguageProcessing Courses; and more.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.
Large Language Models (LLMs) have revolutionized naturallanguageprocessing but can exhibit biases and may generate toxic content. We investigate the unintended consequences of RLHF on the creativity of LLMs through three experiments focusing on the Llama-2 series.
Well, it’s NaturalLanguageProcessing which equips the machines to work like a human. But there is much more to NLP, and in this blog, we are going to dig deeper into the key aspects of NLP, the benefits of NLP and NaturalLanguageProcessing examples. What is NLP? However, the road is not so smooth.
These professionals venture into new frontiers like machine learning, naturallanguageprocessing, and computer vision, continually pushing the limits of AI’s potential. This is used for tasks like clustering, dimensionality reduction, and anomaly detection. What are some emerging AI applications that excite you?
GenAI can help by automatically clustering similar data points and inferring labels from unlabeled data, obtaining valuable insights from previously unusable sources. NaturalLanguageProcessing (NLP) is an example of where traditional methods can struggle with complex text data.
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using NaturalLanguageProcessing (NLP) or more specific from Named-Entity Recognition (NER).
NaturalLanguageProcessing (NLP): Data scientists are incorporating NLP techniques and technologies to analyze and derive insights from unstructured data such as text, audio, and video. This enables them to extract valuable information from diverse sources and enhance the depth of their analysis. H2O.ai: – H2O.ai
The agent uses naturallanguageprocessing (NLP) to understand the query and uses underlying agronomy models to recommend optimal seed choices tailored to specific field conditions and agronomic needs. What corn hybrids do you suggest for my field?”.
To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique. They used JMeter to call the Asynchronous Inference endpoint to simulate real production load on the cluster.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
Faiss is a library for efficient similarity search and clustering of dense vectors. They are used in a variety of AI applications, such as image search, naturallanguageprocessing, and recommender systems. It is designed for storing and searching for large datasets of embeddings.
When Meta introduced distributed GPU-based training , we decided to construct specialized data center networks tailored for these GPU clusters. We have successfully expanded our RoCE networks, evolving from prototypes to the deployment of numerous clusters, each accommodating thousands of GPUs.
They are set to redefine how developers approach naturallanguageprocessing. Clustering : Employed for grouping text strings based on their similarities, facilitating the organization of related information. The realm of artificial intelligence continues to evolve with New OpenAI embedding models.
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Delete the MongoDB Atlas cluster. Solution overview The following diagram illustrates the solution architecture. Set up the database access and network access. Delete the Lambda function.
The algorithm learns to find patterns or structure in the data by clustering similar data points together. WHAT IS CLUSTERING? Clustering is an unsupervised machine learning technique that is used to group similar entities. Those groups are referred to as clusters.
In this blog post, we’ll explore five project ideas that can help you build expertise in computer vision, naturallanguageprocessing (NLP), sales forecasting, cancer detection, and predictive maintenance using Python.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. Their impact on ML tasks has made them a cornerstone of AI advancements.
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. They are typically trained on clusters of computers or even on cloud computing platforms.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. 3 feature visual representation of a K-means Algorithm.
Exploring Disease Mechanisms : Vector databases facilitate the identification of patient clusters that share similar disease progression patterns. Here are a few key components of the discussed process described below: Feature engineering : Transforming raw clinical data into meaningful numerical representations suitable for vector space.
The algorithms can then use this knowledge to classify new, unseen data into predefined categories Naturallanguageprocessing (NLP) : NLP is a subset of machine learning that focuses on the interaction between computers and human language.
It is an AI framework and a type of naturallanguageprocessing (NLP) model that enables the retrieval of information from an external knowledge base. Facebook AI similarity search (FAISS) FAISS is used for similarity search and clustering dense vectors. Let’s take a deeper look into understanding RAG.
They often play a crucial role in clustering and segmenting data, helping businesses identify trends without prior knowledge of the outcome. They are particularly effective in applications such as image recognition and naturallanguageprocessing, where traditional methods may fall short.
Clustering (Unsupervised). With Clustering the data is divided into groups. By applying clustering based on distance, the villages are divided into groups. The center of each cluster is the optimal location for setting up health centers. The center of each cluster is the optimal location for setting up health centers.
Distributed model training requires a cluster of worker nodes that can scale. Amazon Elastic Kubernetes Service (Amazon EKS) is a popular Kubernetes-conformant service that greatly simplifies the process of running AI/ML workloads, making it more manageable and less time-consuming.
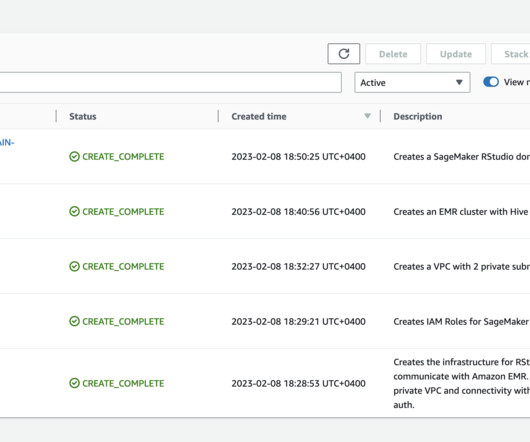
Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster. There is no need to set up and manage clusters. He specializes in NaturalLanguageProcessing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
In this post, we explore the concept of querying data using naturallanguage, eliminating the need for SQL queries or coding skills. NaturalLanguageProcessing (NLP) and advanced AI technologies can allow users to interact with their data intuitively by asking questions in plain language.
In our test environment, we observed 20% throughput improvement and 30% latency reduction across multiple naturallanguageprocessing models. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
Its prowess lies in naturallanguageprocessing (NLP) tasks like sentiment analysis, question-answering, and text classification. Boosting efficiency with language summarization Explore how generative AI can revolutionize IT support teams, automating tasks and expediting solutions.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. Their impact on ML tasks has made them a cornerstone of AI advancements.
They classify, regress, or cluster data based on learned patterns but do not create new data. NaturalLanguageProcessing (NLP) for Data Interaction Generative AI models like GPT-4 utilize transformer architectures to understand and generate human-like text based on a given context.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. For example, let’s say you had a collection of customer emails or online product reviews.
It is used for machine learning, naturallanguageprocessing, and computer vision tasks. TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs.
From decision trees and neural networks to regression models and clustering algorithms, a variety of techniques come under the umbrella of machine learning. Big data processing With the increasing volume of data, big data technologies have become indispensable for Applied Data Science.
Using RStudio on SageMaker and Amazon EMR together, you can continue to use the RStudio IDE for analysis and development, while using Amazon EMR managed clusters for larger data processing. In this post, we demonstrate how you can connect your RStudio on SageMaker domain with an EMR cluster. Choose Create stack.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







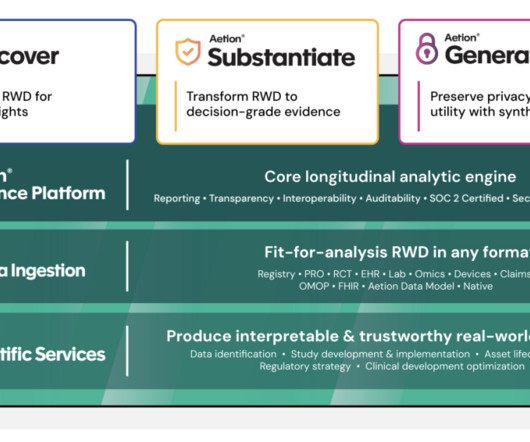










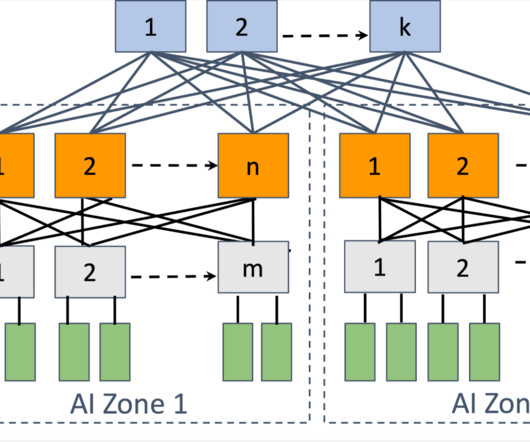































Let's personalize your content