This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Latent Semantic Analysis and its Uses in NaturalLanguageProcessing appeared first on Analytics Vidhya. Textual data, even though very important, vary considerably in lexical and morphological standpoints. Different people express themselves quite differently when it comes to […].
In this blog post, we’ll explore five project ideas that can help you build expertise in computer vision, naturallanguageprocessing (NLP), sales forecasting, cancer detection, and predictive maintenance using Python.
These professionals venture into new frontiers like machine learning, naturallanguageprocessing, and computer vision, continually pushing the limits of AI’s potential. This is used for tasks like clustering, dimensionality reduction, and anomaly detection. What are some emerging AI applications that excite you?
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using NaturalLanguageProcessing (NLP) or more specific from Named-Entity Recognition (NER). Why we did it? It is a nice show-case many people are interested in.
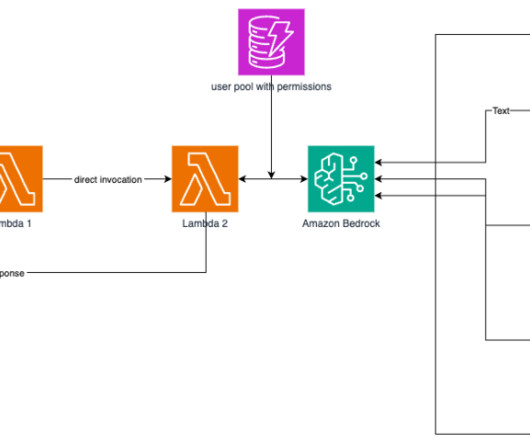
Agent architecture The following diagram illustrates the serverless agent architecture with standard authorization and real-time interaction, and an LLM agent layer using Amazon Bedrock Agents for multi-knowledge base and backend orchestration using API or Python executors. Domain-scoped agents enable code reuse across multiple agents.
With SageMaker, you can streamline the entire model deployment process. Solution overview SageMaker JumpStart provides FMs through two primary interfaces: Amazon SageMaker Studio and the SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use JumpStart models.
It is an AI framework and a type of naturallanguageprocessing (NLP) model that enables the retrieval of information from an external knowledge base. Facebook AI similarity search (FAISS) FAISS is used for similarity search and clustering dense vectors. Haystack It is a Python framework that is built on Elasticsearch.
Programming Language (R or Python). Programmers can start with either R or Python. For academics and domain experts, R is the preferred language. it is overwhelming to learn data science concepts and a general-purpose language like python at the same time. R being a statistical language is an easier option.
In this post, we explore the concept of querying data using naturallanguage, eliminating the need for SQL queries or coding skills. NaturalLanguageProcessing (NLP) and advanced AI technologies can allow users to interact with their data intuitively by asking questions in plain language.
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learning algorithms. Acquiring proficiency in Python has become essential for individuals aiming to excel in these domains. Why do you need Python machine learning packages?
The algorithm learns to find patterns or structure in the data by clustering similar data points together. WHAT IS CLUSTERING? Clustering is an unsupervised machine learning technique that is used to group similar entities. Those groups are referred to as clusters.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. 3 feature visual representation of a K-means Algorithm.
It is used for machine learning, naturallanguageprocessing, and computer vision tasks. It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. TensorFlow was also used by Netflix to improve its recommendation engine.
Code generation : LLMs can generate code, such as Python or Java code. Understanding Large Language Models Best examples of large language models Let’s explore a range of noteworthy large language models that have made waves in the field: 1. Question answering : LLMs can answer questions about text.
Sonnet model for naturallanguageprocessing. This could be, for example, Keep all your replies as short as possible or If I ask for code its always Python. For example, the query Remember to always use Python as a programming language will trigger the execution of this tool.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 Vision models.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. client( service_name='bedrock', region_name='us-west-2', ) bedrock_runtime = boto3.client(
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. Java has numerous libraries designed for the language, including CoreNLP, OpenNLP, and others.
They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization. Here’s a list of key skills that are typically covered in a good data science bootcamp: Programming Languages : Python : Widely used for its simplicity and extensive libraries for data analysis and machine learning.
For instance, today’s machine learning tools are pushing the boundaries of naturallanguageprocessing, allowing AI to comprehend complex patterns and languages. PyTorch PyTorch, a Python-based machine learning library, stands out among its peers in the machine learning tools ecosystem.
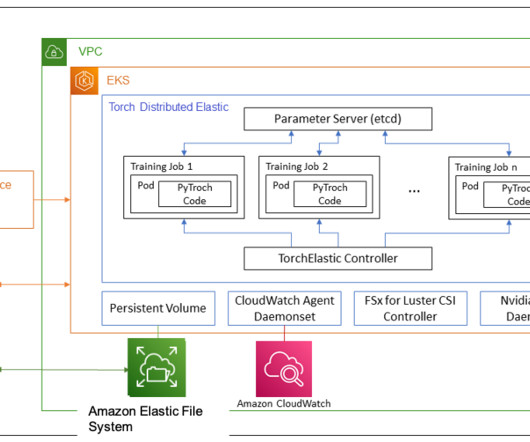
In our solution, we implement a hyperparameter grid search on an EKS cluster for tuning a bert-base-cased model for classifying positive or negative sentiment for stock market data headlines. A desired cluster can simply be configured using the eks.conf file and launched by running the eks-create.sh to launch the cluster.
They’re available through the SageMaker Python SDK. In these cases, you might be able to speed up the process by distributing training over multiple machines or processes in a cluster. Dask is an open-source parallel computing library that allows for distributed parallel processing of large datasets in Python.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing. This is widely used in NaturalLanguageProcessing (NLP), where it plays a pivotal role in pre-processing unstructured textual data. The below flow diagram illustrates this process.
Naturallanguageprocessing, computer vision, data mining, robotics, and other competencies are strengthened in the course. Generative AI with large language models course involves skills in the said streams while training models and applying generative AI to business scenarios.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. SageMaker features and capabilities help developers and data scientists get started with naturallanguageprocessing (NLP) on AWS with ease.
You need to be highly proficient in programming languages to help businesses solve problems. Python is one of the widely used programming languages in the world having its own significance and benefits. Its efficacy may allow kids from a young age to learn Python and explore the field of Data Science.
In this article, we will explore the concept of applied text mining in Python and how to do text mining in Python. Introduction to Applied Text Mining in Python Before going ahead, it is important to understand, What is Text Mining in Python? How To Do Text Mining in Python? within the text.
You can now fine-tune and deploy Mistral text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. You can fine-tune the models using either the SageMaker Studio UI or SageMaker Python SDK. The model is made available under the permissive Apache 2.0
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion. Use metadata query language to filter output ( $eq , $ne , $in , $nin , $and , and $or ).
Historically, naturallanguageprocessing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
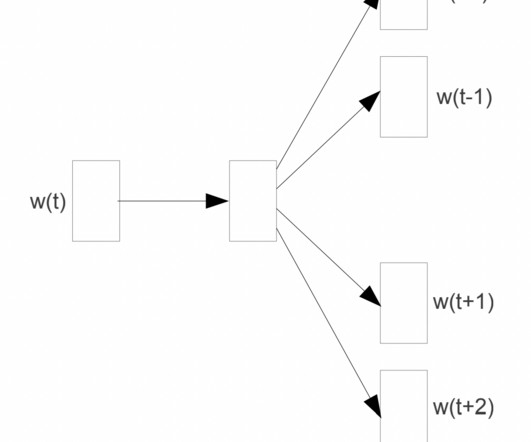
NLP A Comprehensive Guide to Word2Vec, Doc2Vec, and Top2Vec for NaturalLanguageProcessing In recent years, the field of naturallanguageprocessing (NLP) has seen tremendous growth, and one of the most significant developments has been the advent of word embedding techniques.
In high performance computing (HPC) clusters, such as those used for deep learning model training, hardware resiliency issues can be a potential obstacle. Although hardware failures while training on a single instance may be rare, issues resulting in stalled training become more prevalent as a cluster grows to tens or hundreds of instances.
A Beginner’s Guide to FAISS, use-cases, Mathematical foundations & implementation FAISS (Facebook AI Similarity Search) is an open-source library developed by Facebook AI Research (FAIR) for high-dimensional data similarity search and clustering. Photo by Mick Haupt on Unsplash What is similarity search?
With advances in machine learning, deep learning, and naturallanguageprocessing, the possibilities of what we can create with AI are limitless. However, the process of creating AI can seem daunting to those who are unfamiliar with the technicalities involved. What is required to build an AI system?
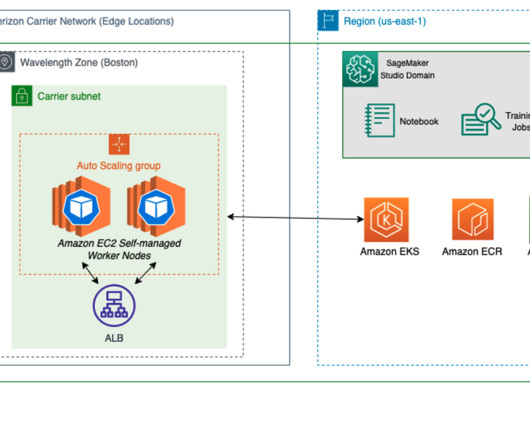
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. sourcedir.tar.gz
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. This module provides a comprehensive set of tools and abstractions that streamline the process of incorporating and deploying these advanced AI models.
It offers pure NumPy implementations of fundamental machine learning algorithms for classification, clustering, preprocessing, and regression. It is widely implemented in many image-processing libraries in different programming languages. We will demonstrate the implementation done in Python to ensure easy comprehension.
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. This is one of the best Machine learning projects in Python. Doctor-Patient Appointment System in Python using Flask Hey guys, in this blog we will see a Doctor-Patient Appointment System for Hospitals built in Python using Flask.
You can integrate a Data Wrangler data preparation flow into your machine learning (ML) workflows to simplify data preprocessing and feature engineering, taking data preparation to production faster without the need to author PySpark code, install Apache Spark, or spin up clusters. Choose Python (Pandas). After notebook files (.ipynb)
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content