This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s your guide to top vector databases in the market Query language Traditional databases: They rely on Structured Query Language (SQL), designed to navigate through relational databases. SQL querying has long been present in the industry, hence it comes with a rich ecosystem of support.
Read a comprehensive SQL guide for data analysis; Learn how to choose the right clustering algorithm for your data; Find out how to create a viral DataViz using the data from Data Science Skills poll; Enroll in any of 10 Free Top Notch NaturalLanguageProcessing Courses; and more.
Neben den relationalen Datenbanken (SQL) gibt es auch die NoSQL -Datenbanken wie den Key-Value-Store, Dokumenten- und Graph-Datenbanken mit recht speziellen Anwendungsgebieten. der k-Nächste-Nachbarn -Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using NaturalLanguageProcessing (NLP) or more specific from Named-Entity Recognition (NER). Why we did it? It is a nice show-case many people are interested in.
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share best practices on developing Text-to-SQL use cases using Meta Llama 3 models. Training involved a dataset of over 15 trillion tokens across two GPU clusters, significantly more than Meta Llama 2.
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. They are typically trained on clusters of computers or even on cloud computing platforms.
They classify, regress, or cluster data based on learned patterns but do not create new data. NaturalLanguageProcessing (NLP) for Data Interaction Generative AI models like GPT-4 utilize transformer architectures to understand and generate human-like text based on a given context.
Clustering (Unsupervised). With Clustering the data is divided into groups. By applying clustering based on distance, the villages are divided into groups. The center of each cluster is the optimal location for setting up health centers. The center of each cluster is the optimal location for setting up health centers.
It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster. There is no need to set up and manage clusters.
In this post, we explore the concept of querying data using naturallanguage, eliminating the need for SQL queries or coding skills. NaturalLanguageProcessing (NLP) and advanced AI technologies can allow users to interact with their data intuitively by asking questions in plain language.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. Knowing some SQL is also essential.
An AI assistant is an intelligent system that understands naturallanguage queries and interacts with various tools, data sources, and APIs to perform tasks or retrieve information on behalf of the user. You can use Fargate with Amazon ECS to run containers without having to manage servers, clusters, or virtual machines.
Photo by adrianna geo on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.23.20 This Week Sentence Transformers txtai: AI-Powered Search Engine Fine-tuning Custom Datasets Data API Endpoint With SQL It’s LIT ? Fury What a week. Let’s recap. old mermaid money found on the Titanic ?
They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
You can integrate a Data Wrangler data preparation flow into your machine learning (ML) workflows to simplify data preprocessing and feature engineering, taking data preparation to production faster without the need to author PySpark code, install Apache Spark, or spin up clusters. They become part of the.flow file within Data Wrangler.
Amazon Bedrock Guardrails implements content filtering and safety checks as part of the query processing pipeline. Anthropic Claude LLM performs the naturallanguageprocessing, generating responses that are then returned to the web application.
Familiarity with libraries like pandas, NumPy, and SQL for data handling is important. This includes skills in data cleaning, preprocessing, transformation, and exploratory data analysis (EDA). Additionally, knowledge of model evaluation, hyperparameter tuning, and model selection is valuable.
You’ll get hands-on practice with unsupervised learning techniques, such as K-Means clustering, and classification algorithms like decision trees and random forest. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing. This is widely used in NaturalLanguageProcessing (NLP), where it plays a pivotal role in pre-processing unstructured textual data. The below flow diagram illustrates this process.
Additionally, its naturallanguageprocessing capabilities and Machine Learning frameworks like TensorFlow and scikit-learn make Python an all-in-one language for Data Science. SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases.
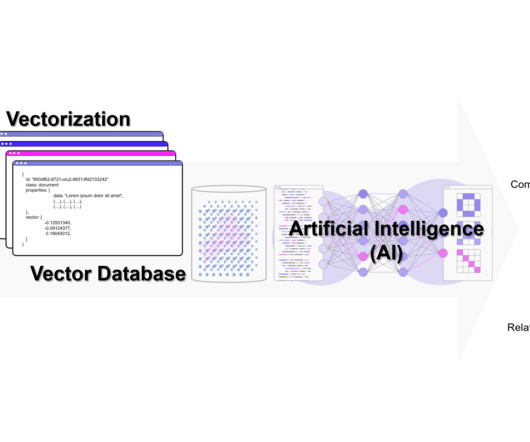
Querying Mechanism Relational databases depend on SQL (Structured Query Language) for querying. As such, you can expect to interact with a library for a Vector Database rather than an entire language like SQL. A common example is word embeddings in naturallanguageprocessing. into vector embeddings.
Run the @feature_processor code remotely In this section, we demonstrate running the feature processing code remotely as a Spark application using the @remote decorator described earlier. We run the feature processing remotely using Spark to scale to large datasets. Take the average of price to create avg_price.
Data preprocessing is a fundamental and essential step in the field of sentiment analysis, a prominent branch of naturallanguageprocessing (NLP). Noise refers to random errors or irrelevant data points that can adversely affect the modeling process.
Relational databases (like MySQL) or No-SQL databases (AWS DynamoDB) can store structured or even semi-structured data but there is one inherent problem. Options (Free vs Paid) Closing Introduction In today’s increasingly globalized world, the ability to communicate in multiple languages has become a highly valuable skill.
While knowing Python, R, and SQL is expected, youll need to go beyond that. NaturalLanguageProcessing (NLP) has emerged as a dominant area, with tasks like sentiment analysis, machine translation, and chatbot development leading the way. Employers arent just looking for people who can program.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. These laws will have an outsized impact on how far LLMs can progress in the new feature and something prompt engineers will be monitoring closely.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, Machine Learning, NaturalLanguageProcessing , Statistics and Mathematics. After that, move towards unsupervised learning methods like clustering and dimensionality reduction.
Clustering: An unsupervised Machine Learning technique that groups similar data points based on their inherent similarities. D Data Mining : The process of discovering patterns, insights, and knowledge from large datasets using various techniques such as classification, clustering, and association rule learning.
For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Soda Core Soda Core is an open-source data quality management framework for SQL, Spark, and Pandas-accessible data.
These may include programming languages (such as Python , R, or SQL), data structures, algorithms, and problem-solving abilities. Learn about supervised and unsupervised learning, regression, classification, clustering, and evaluation metrics. Explore popular machine learning libraries like sci-kit-learn and TensorFlow.
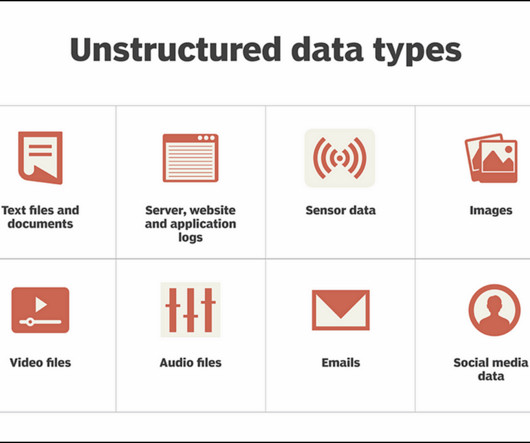
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. This text has a lot of information, but it is not structured.
In general, it’s a large language model, not altogether that different from language machine learning models we’ve seen in the past that do various naturallanguageprocessing tasks. GPT-3 is related to ChatGPT, which is the thing I guess the whole world’s heard about now.
Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. One of the areas I encourage folks to think about when it comes to language choice is the community support behind things. Let’s look at the healthcare vertical for context.
Amazon Bedrock Knowledge Bases provides industry-leading embeddings models to enable use cases such as semantic search, RAG, classification, and clustering, to name a few, and provides multilingual support as well. The following diagram illustrates the OpenSearch Serverless architecture.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content