This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SupportVectorMachines (SVM) SVMs are powerful classification algorithms that work by finding the hyperplane that best separates different classes in high-dimensional space. K-Means Clustering K-means clustering partitions data into k distinct clusters based on feature similarity.
Pattern Recognition and Prediction Classification algorithms excel at recognizing patterns in data, which is crucial for: PredictiveAnalytics : By learning from historical data, classification models can predict future outcomes. These models can detect subtle patterns that might be missed by human radiologists.
Models: Bridging data and predictive insights Models, in the context of data science, are mathematical representations of real-world phenomena. They play a pivotal role in predictiveanalytics and machine learning, enabling data scientists to make informed forecasts and decisions based on historical data patterns.
Applications of Associative Classification Associative classification is a versatile technique used across multiple industries to improve decision-making and predictiveanalytics. It provides a collection of Machine Learning algorithms for data mining tasks such as classification, regression, clustering, and association rule mining.
Supervised learning is commonly used for risk assessment, image recognition, predictiveanalytics and fraud detection, and comprises several types of algorithms. Regression algorithms —predict output values by identifying linear relationships between real or continuous values (e.g., temperature, salary).
AI algorithms can uncover hidden correlations within IoT data, enabling predictiveanalytics and proactive actions. Here are some key advantages: Enhanced predictiveanalytics AI-powered IoT devices can predict future outcomes and behaviors based on historical data patterns.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? AI models can be trained to recognize patterns and make predictions.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? AI models can be trained to recognize patterns and make predictions.
Statistical methods, machine learning algorithms, and data mining techniques are employed to extract meaningful insights from the collected data. This analysis may involve feature engineering, dimensionality reduction, clustering, classification, regression, or other statistical modeling approaches.
Machine Learning with Python Machine Learning (ML) empowers systems to learn from data and improve their performance over time without explicit programming. Algorithms in ML identify patterns and make decisions, which is crucial for applications like predictiveanalytics and recommendation systems.
Applications : Stock price prediction and financial forecasting Analysing sales trends over time Demand forecasting in supply chain management Clustering Models Clustering is an unsupervised learning technique used to group similar data points together. Popular clustering algorithms include k-means and hierarchical clustering.
Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. Common Applications of Machine Learning Machine Learning has numerous applications across industries.
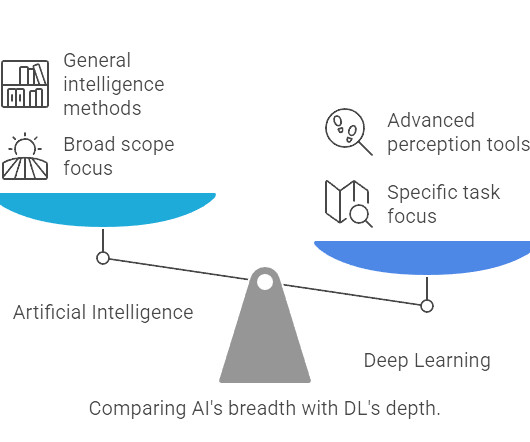
DL Enhances PredictiveAnalytics: Excels in image and speech recognition tasks. Deep Learning Focuses on Neural Networks : Specializes in complex pattern recognition. AI Drives Automation and Efficiency : Improves processes across industries. Both Drive Technological Innovation: Transform industries with intelligent systems.
Both PyTorch and TensorFlow/Keras are still the go-to machine learning frameworks for a number of tasks, largely thanks to their ability to scale and be used for more resource-intensive tasks like deep learning; these two frameworks arent limited to just basic ML.
Healthcare Data Science is revolutionising healthcare through predictiveanalytics, personalised medicine, and disease detection. For example, it helps predict patient outcomes, optimise hospital operations, and discover new drugs. Finance: AI-driven algorithms analyse historical data to detect fraud and predict market trends.
(Or even better than that) Machine learning has transformed the way businesses operate by automating processes, analyzing data patterns, and improving decision-making. It plays a crucial role in areas like customer segmentation, fraud detection, and predictiveanalytics. Unsupervised learning outputs are not as direct.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content