This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Run SQL, Python & Scala workloads with full data governance & cost-efficient multi-user compute. Unlock the power of Apache Spark™ with Unity Catalog Lakeguard on Databricks Data Intelligence Platform.
Introduction Dedicated SQL pools offer fast and reliable data import and analysis, allowing businesses to access accurate insights while optimizing performance and reducing costs. A clustered column store index is created on a table with a clustered column store architecture.
Here’s your guide to top vector databases in the market Query language Traditional databases: They rely on Structured Query Language (SQL), designed to navigate through relational databases. SQL querying has long been present in the industry, hence it comes with a rich ecosystem of support.
Read a comprehensive SQL guide for data analysis; Learn how to choose the right clustering algorithm for your data; Find out how to create a viral DataViz using the data from Data Science Skills poll; Enroll in any of 10 Free Top Notch Natural Language Processing Courses; and more.
They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference. Previously, data scientists often found themselves juggling multiple tools to support SQL in their workflow, which hindered productivity.
For this post we’ll use a provisioned Amazon Redshift cluster. Basic knowledge of a SQL query editor. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. A provisioned or serverless Amazon Redshift data warehouse. A SageMaker domain. Database name : Enter dev.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL, business intelligence (BI), and reporting tools. In this case, add the intended IAM role to the source Aurora MySQL cluster.
Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. This article was published as a part of the Data Science Blogathon. Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution.
From vCenter, administrators can configure and control ESXi hosts, datacenters, clusters, traditional storage, software-defined storage, traditional networking, software-defined networking, and all other aspects of the vSphere architecture. VMware “clustering” is purely for virtualization purposes.
Leveraging these advances, new technologies now support SQL on Hadoop, making in-cluster analytics of data in Hadoop a reality. Recent technology advances within the Apache Hadoop ecosystem have provided a big boost to Hadoop’s viability as an analytics environment—above and beyond just being a good place to store data.
The package is particularly well-suited for working with tabular data, such as spreadsheets or SQL tables, and provides powerful data cleaning, transformation, and wrangling capabilities. It provides a wide range of tools for supervised and unsupervised learning, including linear regression, k-means clustering, and support vector machines.
Choosing the Right Clustering Algorithm for your Dataset; DeepMind Has Quietly Open Sourced Three New Impressive Reinforcement Learning Frameworks; A European Approach to Masters Degrees in Data Science; The Future of Analytics and Data Science. Also: How AI will transform healthcare (and can it fix the US healthcare system?);
Under Settings , enter a name for your database cluster identifier. Set up an Aurora MySQL database Complete the following steps to create an Aurora MySQL database to host the structured sales data: On the Amazon RDS console, choose Databases in the navigation pane. Choose Create database. Select Aurora , then Aurora (MySQL compatible).
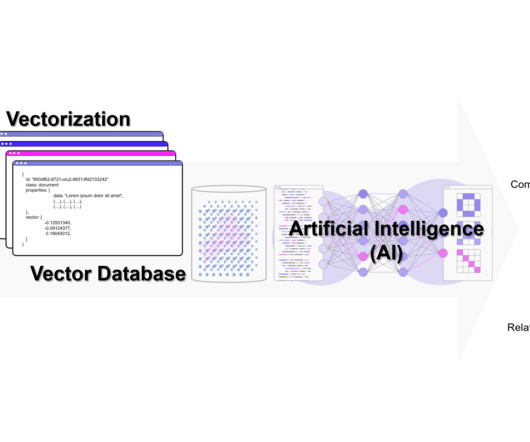
The following image uses these embeddings to visualize how topics are clustered based on similarity and meaning. You can then say that if an article is clustered closely to one of these embeddings, it can be classified with the associated topic. We can then use pgvector to find articles that are clustered together.
SQL Server 2019 SQL Server 2019 went Generally Available. AWS Parallel Cluster for Machine Learning AWS Parallel Cluster is an open-source cluster management tool. Azure Synapse Analytics This is the future of data warehousing. If you are at a University or non-profit, you can ask for cash and/or AWS credits.
Neben den relationalen Datenbanken (SQL) gibt es auch die NoSQL -Datenbanken wie den Key-Value-Store, Dokumenten- und Graph-Datenbanken mit recht speziellen Anwendungsgebieten. der k-Nächste-Nachbarn -Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering.
Most Data Science enthusiasts know how to write queries and fetch data from SQL but find they may find the concept of indexing to be intimidating. Clustered Indexes : have ordered files and built on non-unique columns. You may only build a single Primary or Clustered index on a table.
Atlas is a multi-cloud database service provided by MongoDB in which the developers can create clusters, databases and indexes directly in the cloud, without installing anything locally. Get Started with Atlas MongoDB Atlas After the Cluster has been created, its time to create a Database and a collection. What is MongoDB Atlas?
It communicates with the Cluster Manager to allocate resources and oversee task progress. SparkContext: Facilitates communication between the Driver program and the Spark Cluster. Cluster Manager: Responsible for resource allocation and monitoring Spark applications during execution.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
The skill clusters are formed via the discipline of Topic Modelling , a method from unsupervised machine learning , which show the differences in the distribution of requirements between them. The presentation is currently limited to the current situation on the labor market. Why we did it?
To create, update, and manage a relational database, we use a relational database management system that most commonly runs on Structured Query Language (SQL). NoSQL databases — NoSQL is a vast category that includes all databases that do not use SQL as their primary data access language.
However, this leads to skyrocketing cloud costs due to inefficient data processing and the need for resource-consuming cluster solutions. Queries are executed up to 1000x faster than comparable SQL queries. One crucial requirement for a well-elastic and scalable cluster is the quick startup time of new cluster nodes to avoid latencies.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there! AS ip_1, r.ip AND l.ip < r.ip
The prompts are managed through Lambda functions to use OpenSearch Service and Anthropic Claude 2 on Amazon Bedrock to search the client’s database and generate an appropriate response to the client’s business analysis, including the response in plain English, the reasoning, and the SQL code.
Clusters : Clusters are groups of interconnected nodes that work together to process and store data. Clustering allows for improved performance and fault tolerance as tasks can be distributed across nodes. Each node is capable of processing and storing data independently.
In contrast, horizontal scaling involves distributing the workload across multiple servers or nodes, commonly known as clustering. With Structured Query Language (SQL), these systems allow data analysts to zoom in, slice and dice data, perform complex joins, and uncover hidden patterns.
Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. Responsibility for maintenance and troubleshooting: Rockets DevOps/Technology team was responsible for all upgrades, scaling, and troubleshooting of the Hadoop cluster, which was installed on bare EC2 instances.
Acquire knowledge of machine learning : Understand different algorithms and techniques used for predictive modeling, classification, and clustering. Develop data manipulation and analysis skills : Gain proficiency in using libraries and tools like pandas and SQL to manipulate, preprocess, and analyze data effectively.
The package is particularly well-suited for working with tabular data, such as spreadsheets or SQL tables, and provides powerful data cleaning, transformation, and wrangling capabilities. It provides a wide range of tools for supervised and unsupervised learning, including linear regression, k-means clustering, and support vector machines.
SQL traces SQL tracing is not natively supported by SAP BTP Kyma. It requires the use of third-party performance monitoring tools, databases with built-in SQL tracing capabilities, log4j logging frameworks, and so on. However, Instana can support SQL tracing.
You can run Spark applications interactively from Amazon SageMaker Studio by connecting SageMaker Studio notebooks and AWS Glue Interactive Sessions to run Spark jobs with a serverless cluster. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster. There is no need to set up and manage clusters.
We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker. A cluster of pings represents popular spots where devices gathered or stopped, such as stores or restaurants. Manually managing a DIY compute cluster is slow and expensive.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
You can use Fargate with Amazon ECS to run containers without having to manage servers, clusters, or virtual machines. An LLM evaluates each question along with the chat history from the same session to determine its nature and which subject area it falls under (such as SQL, action, search, or SME).
This blog post will go through how data professionals may use SageMaker Data Wrangler’s visual interface to locate and connect to existing Amazon EMR clusters with Hive endpoints. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters. This is TLS enabled.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
” Data management and manipulation Data scientists often deal with vast amounts of data, so it’s crucial to understand databases, data architecture, and query languages like SQL. Familiarity with regression techniques, decision trees, clustering, neural networks, and other data-driven problem-solving methods is vital.
It supports various data types and offers advanced features like data sharing and multi-cluster warehouses. dbt focuses on transforming raw data into analytics-ready tables using SQL-based transformations. Snowflake’s architecture separates storage and compute, enabling elastic scalability and cost-effective operations.
As such, you should begin by learning the basics of SQL. SQL is an established language used widely in data engineering. Just like programming, SQL has multiple dialects. Besides SQL, you should also learn how to model data. As a data engineer, you will be primarily working on databases. Follow Industry Trends.
They should be proficient in languages like Python, R or SQL to effectively analyze data and create custom scripts to automate data processing and analysis. A strong foundation in statistics is crucial to apply statistical methods and models to analysis, including concepts like hypothesis testing, regression, and clustering analysis.
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks. An EMR cluster with EMR runtime roles enabled. internal in the certificate subject definition.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content