This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. This is called clustering. In Data Science, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset.
SupportVectorMachines (SVM): This algorithm finds a hyperplane that best separates data points of different classes in high-dimensional space. Clustering Algorithms: Clustering algorithms can group data points with similar features. Points that don’t belong to any well-defined cluster might be anomalies.
They are also used in machine learning, such as supportvectormachines and k-means clustering. Robust inference: Robust inference is a technique that is used to make inferences that are not sensitive to outliers or extreme observations.
Zheng’s “Guide to Data Structures and Algorithms” Parts 1 and Part 2 1) Big O Notation 2) Search 3) Sort 3)–i)–Quicksort 3)–ii–Mergesort 4) Stack 5) Queue 6) Array 7) Hash Table 8) Graph 9) Tree (e.g.,
Scikit-learn Scikit-learn is a powerful library for machine learning in Python. It provides a wide range of tools for supervised and unsupervised learning, including linear regression, k-means clustering, and supportvectormachines.
SupportVectorMachines (SVM) SVMs are powerful classification algorithms that work by finding the hyperplane that best separates different classes in high-dimensional space. K-Means Clustering K-means clustering partitions data into k distinct clusters based on feature similarity.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. What is Classification? Hence, the assumption causes a problem.
Scikit-learn Scikit-learn is a powerful library for machine learning in Python. It provides a wide range of tools for supervised and unsupervised learning, including linear regression, k-means clustering, and supportvectormachines.
SmartCore SmartCore is a machine learning library written in Rust that provides a variety of algorithms for regression, classification, clustering, and more. The library encompasses both conventional and advanced machine learning techniques, including linear regression, k-means clustering, random forests, and supportvectormachines.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Examples include: Spam vs. Not Spam Disease Positive vs. Negative Fraudulent Transaction vs. Legitimate Transaction Popular algorithms for binary classification include Logistic Regression, SupportVectorMachines (SVM), and Decision Trees. These models can detect subtle patterns that might be missed by human radiologists.
Comparison with Other Classification Techniques Associative classification differs from traditional classification methods like decision trees and supportvectormachines (SVM). RapidMiner supports various data mining operations, including classification, clustering, and association rule mining.
Supervised machine learning algorithms, such as linear regression and decision trees, are fundamental models that underpin predictive modeling. Unsupervised learning models, like clustering and dimensionality reduction, aid in uncovering hidden structures within data. Decision trees are used to classify data into different categories.
In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering. This is similar as you consider many factors while you pay someone for essay , which may include referencing, evidence-based argument, cohesiveness, etc.
Classification algorithms include logistic regression, k-nearest neighbors and supportvectormachines (SVMs), among others. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decision trees, neural networks, and supportvectormachines. Clustering algorithms, such as k-means, group similar data points, and regression models predict trends based on historical data.
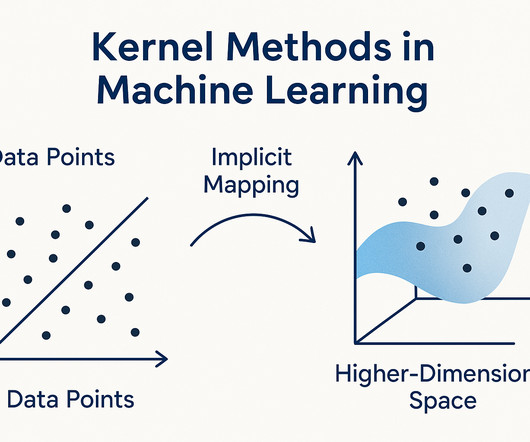
Helping Algorithms Like SVM SupportVectorMachines ( SVM ) are popular machine learning tools that work well with kernel methods. Use the RBF kernel when your data clusters in circular shapes or when you expect the relationships to change gradually. Think of it like changing your viewpoint to solve a puzzle.
The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering. The idea is to sort the labels into clusters to create a meta-label space.
We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker. A cluster of pings represents popular spots where devices gathered or stopped, such as stores or restaurants. Manually managing a DIY compute cluster is slow and expensive.
Common Machine Learning Algorithms Machine learning algorithms are not limited to those mentioned below, but these are a few which are very common. Linear Regression Decision Trees SupportVectorMachines Neural Networks Clustering Algorithms (e.g.,
Examples of supervised learning models include linear regression, decision trees, supportvectormachines, and neural networks. Common examples include: Linear Regression: It is the best Machine Learning model and is used for predicting continuous numerical values based on input features.
Logistic Regression K-Nearest Neighbors (K-NN) SupportVectorMachine (SVM) Kernel SVM Naive Bayes Decision Tree Classification Random Forest Classification I will not go too deep about these algorithms in this article, but it’s worth it for you to do it yourself. Great example of this tecnique is K-means clustering algorithm.
Machine learning algorithms for unstructured data include: K-means: This algorithm is a data visualization technique that processes data points through a mathematical equation with the intention of clustering similar data points. Isolation forest models can be found on the free machine learning library for Python, scikit-learn.
The goal of unsupervised learning is to identify structures in the data, such as clusters, dimensions, or anomalies, without prior knowledge of the expected output. Some popular classification algorithms include logistic regression, decision trees, random forests, supportvectormachines (SVMs), and neural networks.
It helps in discovering hidden patterns and organizing text data into meaningful clusters. Machine Learning algorithms, including Naive Bayes, SupportVectorMachines (SVM), and deep learning models, are commonly used for text classification. within the text.
The earlier models that were SOTA for NLP mainly fell under the traditional machine learning algorithms. These included the Supportvectormachine (SVM) based models. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM ” by Deepak Narayanan et al.
It constructs multiple decision trees and combines their predictions to achieve accurate results in identifying different types of network traffic SupportVectorMachines (SVM) : SVM is used for both classification and anomaly detection.
Supervised learning algorithms, like decision trees, supportvectormachines, or neural networks, enable IoT devices to learn from historical data and make accurate predictions. Unsupervised learning Unsupervised learning involves training machine learning models with unlabeled datasets.
Practical Applications of Linear Algebra in Machine Learning Discover the practical applications of Linear Algebra in Machine Learning, including data preprocessing, model training, dimensionality reduction, and clustering. Model Training Most Machine Learning models rely heavily on Linear Algebra during training phases.
SupportVectorMachines (SVM) SVMs classify data points by finding the optimal hyperplane that maximises the margin between classes. Python facilitates the application of various unsupervised algorithms for clustering and dimensionality reduction. classification, regression) and data characteristics.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Machine Learning Algorithms Candidates should demonstrate proficiency in a variety of Machine Learning algorithms, including linear regression, logistic regression, decision trees, random forests, supportvectormachines, and neural networks. How do you handle missing values in a dataset?
SVM-based classifier: Amazon Titan Embeddings In this scenario, it is likely that user interactions belonging to the three main categories ( Conversation , Services , and Document_Translation ) form distinct clusters or groups within the embedding space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
Clustering Algorithms Techniques such as K-means clustering can help identify groups of similar data points. Points that do not belong to any cluster may be considered anomalies. SupportVectorMachines (SVM) SVM can be employed for anomaly detection by finding the hyperplane that best separates normal data from anomalies.
This harmonization is particularly critical in algorithms such as k-Nearest Neighbors and SupportVectorMachines, where distances dictate decisions. Scaling steps in as a guardian, harmonizing the scales and ensuring that algorithms treat each feature fairly.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. It identifies regions of high data point density as clusters and flags points with low densities as anomalies. Points that don’t belong to any cluster or are in low-density regions are considered anomalies.
Are there clusters of customers with different spending patterns? #3. Model Training We train multiple machine learning models, including Logistic Regression, Random Forest, Gradient Boosting, and SupportVectorMachine. SupportVectorMachine (svm): Versatile model for linear and non-linear data.
Applications : Stock price prediction and financial forecasting Analysing sales trends over time Demand forecasting in supply chain management Clustering Models Clustering is an unsupervised learning technique used to group similar data points together. Popular clustering algorithms include k-means and hierarchical clustering.
Statistical methods, machine learning algorithms, and data mining techniques are employed to extract meaningful insights from the collected data. This analysis may involve feature engineering, dimensionality reduction, clustering, classification, regression, or other statistical modeling approaches.
scikit-learn – The most widely Machine learning for text used for Python, scikit-learn is an open-source, free machine learning library. It has many useful tools for stats modeling and machine learning including regression, classification, and clustering.
Sentence embeddings can also be used in text classification by representing entire sentences as high-dimensional vectors and then feeding them into a classifier. Clustering — we can cluster our sentences, useful for topic modeling. The article is clustering “Fine Food Reviews” dataset. The new model offers: 90%-99.8%
left: neutral pose — do nothing | right: fist — close gripper | Photos from myo-readings-dataset left: extension — move forward | right: flexion — move backward | Photos from myo-readings-dataset This project uses the scikit-learn implementation of a SupportVectorMachine (SVM) trained for gesture recognition.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content