This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
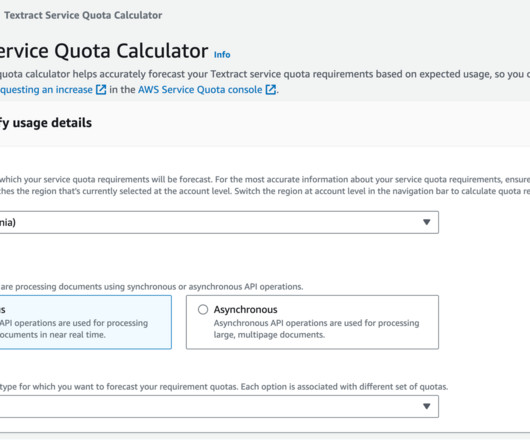
To be successful with a graph database—such as Amazon Neptune, a managed graph database service—you need a graph datamodel that captures the data you need and can answer your questions efficiently. Building that model is an iterative process.
Today, we officially take the step to combine the data, models, compute, distribution and talent. xAI and Xs futures are intertwined, Musk wrote in a post on X. This combination will unlock immense potential by blending xAIs advanced AI capability and expertise with Xs massive reach.
In order for us to start using any kind of data logic on this, we need to identify the board location first. Author(s): Ashutosh Malgaonkar Originally published on Towards AI. Here is how tic tac toe looks. So, let us figure out a system to determine board location.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
Whether it’s an insurance company leveraging location for better underwriting or risk assessment, a financial services organization enriching transactions for validation and accurate merchant assignment, or a telecommunications company optimizing 5G rollouts and creating new services, there’s one essential commonality: location data.
FastAPI leverages Pydantic for datamodeling, one of the standout features of FastAPI, though it is not exclusive to it, which then allows FastAPI to validate incoming data automatically against the defined schema (e.g., Or requires a degree in computerscience? type checks, format checks). Thats not the case.
Writing this code is much harder, because you're not just telling a computer what to do, you're also grappling with another user's mental model of your code. Now it's equal part computerscience and psychology of reasoning, or something. It's common to see documentation for dev tools structured like a computer program.
Yingwei received his PhD in computerscience from Texas A&M University. With over 8 years of experience building AI and machine learning models for industrial applications, he specializes in generative AI, computer vision, and time series modeling. candidate in computerscience at UNC-Charlotte.
Ruan graduated from the Federal Institute of Rio Grande do Norte, and is studying hard to become a data scientist or engineer at a big tech company. This year he plans to apply to universities in the USA to study computerscience or datascience. Wesley is passionate about defending environmental causes.
In this blog post, we’ll examine what is data warehouse architecture and what exactly constitutes good data warehouse architecture as well as how you can implement one successfully without needing some kind of computerscience degree!
Skills and Tools of Data Engineers Data Engineering requires a unique set of skills, including: Database Management: SQL, NoSQL, NewSQL, etc. Data Warehousing: Amazon Redshift, Google BigQuery, etc. DataModeling: Entity-Relationship (ER) diagrams, data normalization, etc.
What do machine learning engineers do: They implement and train machine learning modelsDatamodeling One of the primary tasks in machine learning is to analyze unstructured datamodels, which requires a solid foundation in datamodeling. How to become a machine learning engineer without a degree?
With these focus areas, you can conduct an architecture review from different aspects to enhance the effectivity, observability, and scalability of the three components of an AI/ML project, data, model, or business goal. She has extensive experience in machine learning with a PhD degree in computerscience.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. js and Tableau Datascience, data analytics and IBM Practicing datascience isn’t without its challenges.
Steven Wu is an Assistant Professor in the School of ComputerScience at Carnegie Mellon University, with his primary appointment in the Software and Societal Systems Department, and affiliated appointments with the Machine Learning Department and the Human-Computer Interaction Institute.
ChromaDB offers several notable features: Efficient vector storage – ChromaDB uses advanced indexing techniques to efficiently store and retrieve high-dimensional vector data, enabling fast similarity searches and nearest neighbor queries. He holds a Bachelor’s in ComputerScience with a minor in Economics from Tufts University.
Some of the common career opportunities in BI include: Entry-level roles Data analyst: A data analyst is responsible for collecting and analyzing data, creating reports, and presenting insights to stakeholders. They may also be involved in datamodeling and database design.
Some of the common career opportunities in BI include: Entry-level roles Data analyst: A data analyst is responsible for collecting and analyzing data, creating reports, and presenting insights to stakeholders. They may also be involved in datamodeling and database design.
Chris had earned an undergraduate computerscience degree from Simon Fraser University and had worked as a database-oriented software engineer. April 2018), which focused on users who do understand joins and curating federated data sources. Relationships in Tableau 2020.2 (May Beginning in Tableau 2020.2,
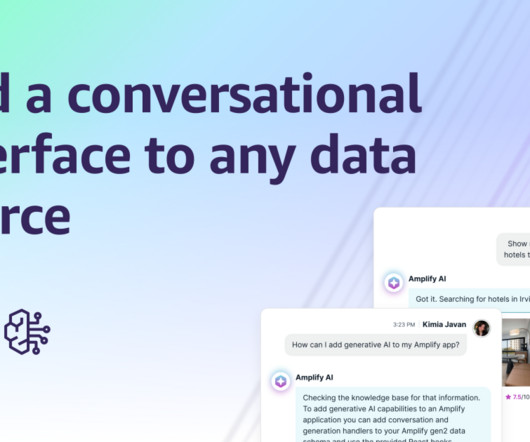
When building generative AI applications using Amazon Bedrock, it’s often necessary to enhance the capabilities of the models by giving them access to external data or functionality. These tools act as bridges, allowing models to retrieve application-specific, real-time or dynamic information […]
It uses advanced tools to look at raw data, gather a data set, process it, and develop insights to create meaning. Areas making up the datascience field include mining, statistics, data analytics, datamodeling, machine learning modeling and programming.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Open-source projects, academic institutions, startups and legacy tech companies all contributed to the development of foundation models.
Hyperparameter overview When training any machine learning (ML) model, you are generally dealing with three types of data: input data (also called the training data), model parameters, and hyperparameters. You use the input data to train your model, which in effect learns your model parameters.
Ensuring data accuracy and consistency through cleansing and validation processes. Data Analysis and Modelling Applying statistical techniques and analytical tools to identify trends, patterns, and anomalies. Developing datamodels to support analysis and reporting.
The database would need to be highly available and resilient, with features like automatic failover and data replication to ensure that the system remains up and running even in the face of hardware or software failures. This could be achieved through the use of a NoSQL datamodel, such as document or key-value stores.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? They are often built by data scientists who are not software engineers or computerscience majors by training. Why did something break?
Thomson Reuters knew they would need to run a series of experiments—training LLMs from 7B to more than 30B parameters, starting with an FM and continuous pre-training (using various techniques) with a mix of Thomson Reuters and general data. Ankit Anand is a Senior Foundation Models Go-To-Market (GTM) Specialist at AWS.
This kind of SFT trains the model to recognize patterns of behavior demonstrated by the humans in the demonstration training data. Model producers need to do this type of fine-tuning to show that their models are capable of performing such tasks for downstream adopters. He is an ACM Fellow and IEEE Fellow.
Chris had earned an undergraduate computerscience degree from Simon Fraser University and had worked as a database-oriented software engineer. April 2018), which focused on users who do understand joins and curating federated data sources. Relationships in Tableau 2020.2 (May Beginning in Tableau 2020.2,
When extended to videos, this iterative process must be applied to multiple frames, multiplying the computational load. Increased parameter count – To handle the additional complexity of video data, models often require more parameters, leading to larger memory footprints and increased computational demands.
Because of this, they will be required to work closely with business stakeholders, data teams, and even other tech-focused members of an organization to sure that the needs of the organization are met and comply with overall business objectives.
Unsupervised learning requires no labels and identifies underlying patterns in the data. Model architectures that qualify as “supervised learning”—from traditional regression models to random forests to most neural networks—require labeled data for training. What are some examples of Foundation Models?
As Data Scientists, you will find immense job opportunities with advanced skills in SQL in the market. You will learn datamodelling to indexes and SQL query functions. It also includes learning on security and privacy mechanisms, the advanced SQL certificate will allow you to enhance your expertise.
Data Architect Designs and creates data systems and structures for optimal organisation and retrieval of information. 24,30000 Datamodelling, system architecture, communication skills Pursue degrees in computerscience or related fields, gain experience in database design, and stay updated on industry trends.
This means that as you define your endpoints and datamodels, FastAPI automatically creates detailed, interactive documentation for your API, making it easier for developers and clients to understand and use your service. Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated?
Especially as those baseline models get so good. Ok, so we’ll have more need for ML engineers than data scientists, right? Let’s talk about computerscience education. I believe that packaging/building/deploying the vanilla, run-of-the-mill ML model will become common knowledge for backend devs. Not so fast.
Mikiko Bazeley: Most people are really surprised to hear that my background in college was not computerscience. I actually did not pick up Python until about a year before I made the transition to a data scientist role. How did you manage to jump from a more analytical, scientific type of role to a more engineering one?
Nowadays, with the advent of deep learning and convolutional neural networks, this process can be automated, allowing the model to learn the most relevant features directly from the data. Model Training: With the labeled data and identified features, the next step is to train a machine learning model.
Educational background Most Big Data Engineers possess a bachelor’s degree in computerscience, software engineering, or related fields, which provides a foundation for understanding complex data issues.
Although QLoRA reduces computational requirements and memory footprint, FSDP, a data/model parallelism technique, will help shard the model across all eight GPUs (one ml.p4d.24xlarge 24xlarge ), enabling training the model even more efficiently.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content