This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data engineering startup Prophecy is giving a new turn to datapipeline creation. Known for its low-code SQL tooling, the California-based company today announced data copilot, a generative AI assistant that can create trusted datapipelines from natural language prompts and improve pipeline quality …
Observo AI, an artificial intelligence-powered datapipeline company that helps companies solve observability and security issues, said Thursday it has raised $15 million in seed funding led by Felici
He spearheads innovations in distributed systems, big-datapipelines, and social media advertising technologies, shaping the future of marketing globally. in ComputerScience and Engineering with a stellar GPA of 8.61, Harshit set a high bar for aspiring innovators. His work today reflects this vision. and M.Tech.)
When I was studying math and computerscience, I discovered machine learning and found it fascinatingit let me combine theory with practical problem-solving in all kinds of industries. Then I lead datascience projectsdesigning models, laying out datapipelines, and making sure everything is tested thoroughly.
Home Table of Contents Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a DataPipeline Adversarial Learning with NSL CIFAR-10 Dataset Configuring Your Development Environment Need Help Configuring Your Development Environment? We open our config.py
DataScience Fundamentals Going beyond knowing machine learning as a core skill, knowing programming and computerscience basics will show that you have a solid foundation in the field. Computerscience, math, statistics, programming, and software development are all skills required in NLP projects.
Data scientists with a PhD or a master’s degree in computerscience or a related field can earn more than $150,000 per year. Data scientists who work in the financial services industry or the healthcare industry can also earn more than the average. The average salary for a data engineer is $107,500 per year.
Machine learning is a field of computerscience that uses statistical techniques to build models from data. These models can be used to predict future outcomes or to classify data into different categories. Inferential statistics are used to make inferences about a population based on a sample.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core datascience skills like programming, computerscience, algorithms, and so on. Research Why should a data scientist need to have research skills, even outside of academia you ask?
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know. Cloud Platforms: AWS, Azure, Google Cloud, etc.
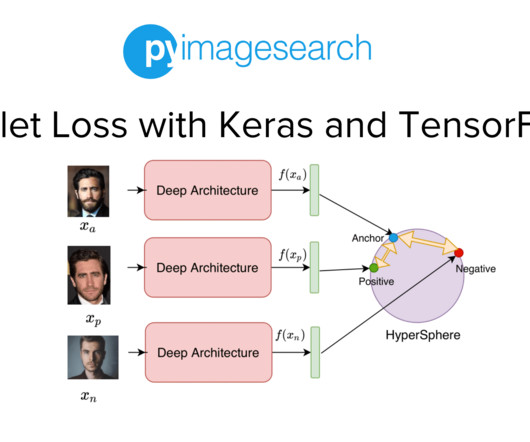
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
Data Engineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Statistics : Fundamental statistical concepts and methods, including hypothesis testing, probability, and descriptive statistics.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. That’s not the case.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Above all, this solution offers you a native Spark way to implement an end-to-end datapipeline from Amazon Redshift to SageMaker.
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
Just as a writer needs to know core skills like sentence structure and grammar, data scientists at all levels should know core datascience skills like programming, computerscience, algorithms, and soon. While knowing Python, R, and SQL is expected, youll need to go beyond that.
The rise of the foundation model ecosystem (which is the result of decades of research in machine learning), natural language processing (NLP) and other fields, has generated a great deal of interest in computerscience and AI circles. Foundation models can use language, vision and more to affect the real world.
SGT release and deployment – The SGT that is output from the earlier optimization step is deployed as part of the datapipeline that feeds the trained LLM. He also taught ComputerScience and Math to High School, University, and Professional students.
Solution Design Creating a high-level architectural design that encompasses datapipelines, model training, deployment strategies, and integration with existing systems. There are several online platforms offering courses in artificial intelligence, datascience, machine learning and others.
Initializing the Siamese Model for Data Analysis Next, we create our siameseModel using the SiameseModel class as we had done during inference in the previous tutorial. Structuring Data for Siamese Model Evaluation We create two lists to store the faces in our database and their corresponding labels (i.e., faces and faceLabels ).
Orchestrating Data Assets instead of Tasks, with Dagster Sandy Ryza | Lead Engineer — Dagster Project | Elementl Asset-based orchestration works well with modern data stack tools like dbt, Meltano, Airbyte, and Fivetran, because those tools already think in terms of assets.
It integrates smoothly with other data processing libraries like Spark, Pandas, NumPy, and more, as well as ML frameworks like TensorFlow and PyTorch. This allows building end-to-end datapipelines and ML workflows on top of Ray. The goal is to make distributed data processing and ML easier for practitioners and researchers.
Specifically, we will develop our datapipeline, implement the loss functions discussed in Part 1 and write our own code to train the CycleGAN model end-to-end using Keras and TensorFlow. Finally, we combine and consolidate our entire training data (i.e., Or requires a degree in computerscience?
We will understand the dataset and the datapipeline for our application and discuss the salient features of the NSL framework in detail. config.py ) The datapipeline (i.e., Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? That’s not the case.
Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources.
Recommended Educational Background Aspiring Azure Data Scientists typically benefit from a solid educational background in DataScience, computerscience, mathematics, or engineering.
In computerscience, a number can be represented with different levels of precision, such as double precision (FP64), single precision (FP32), and half-precision (FP16). An important part of the datapipeline is the production of features, both online and offline.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computerscience? All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. That’s not the case.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? Enter Keras Core!
Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex datapipelines. With his background in computerscience, he is very interested in using technology to build solutions to real-world problems.
He focuses on Deep learning including NLP and Computer Vision domains. Greg Benson is a Professor of ComputerScience at the University of San Francisco and Chief Scientist at SnapLogic. He helps customers achieve high performance model inference on SageMaker.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a datapipeline. About the Authors Greg Benson is a Professor of ComputerScience at the University of San Francisco and Chief Scientist at SnapLogic.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content