This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
Introduction Datascience has taken over all economic sectors in recent times. To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
Pulse, a five-person startup specializing in unstructured datapreparation for machine learning models, has raised $3.9 Pulse sells businesses a toolkit designed to convert raw, unstructured data into formats ready for use by machine million in a funding round led by Nat Friedman and Daniel Gross.
In the rapidly evolving landscape of artificial intelligence, large language models (LLMs) have emerged as a transformative force for modern enterprises. These powerful models, exemplified by GPT-4 and its predecessors, offer the potential to drive innovation, enhance productivity, and fuel business growth.
For example, the relevant words to query the word "computer" might look like "desktop" , "laptop" , "keyboard" , "device" , etc. We will start by setting up libraries and datapreparation. Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Thats not the case.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. Yang holds a Bachelor’s and Master’s degree in ComputerScience from Texas A&M University. Malhar Mane is an Enterprise Solutions Architect at AWS based in Seattle.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Fine tuning Now that your SageMaker HyperPod cluster is deployed, you can start preparing to execute your fine tuning job. Datapreparation The foundation of successful language model fine tuning lies in properly structured and prepared training data.
in Mathematics and an MSCS in Artificial Intelligence, so I am more than qualified to mentor and teach undergraduate mathematics and computerscience courses, as well as many graduate courses in Math/CS. How to perform datapreparation? I also have an M.S. Know when not to use AI. How to select a dataset?
Many people use the term “pipeline” in MLOps which can be confusing since pipeline is computerscience term that refers to a linear sequence with a single input/output. For now, I would recommend learning MLflow since it is open-source and seems to be very popular.
AI engineering is the discipline focused on developing tools, systems, and processes to enable the application of artificial intelligence in real-world contexts, which combines the principles of systems engineering, software engineering, and computerscience to create AI systems.
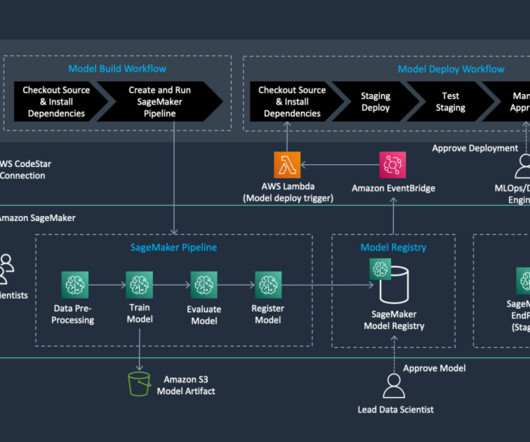
Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. We further specify the dependency of the datapreparation step on the SageMaker Feature Store ingestion step.
” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape.
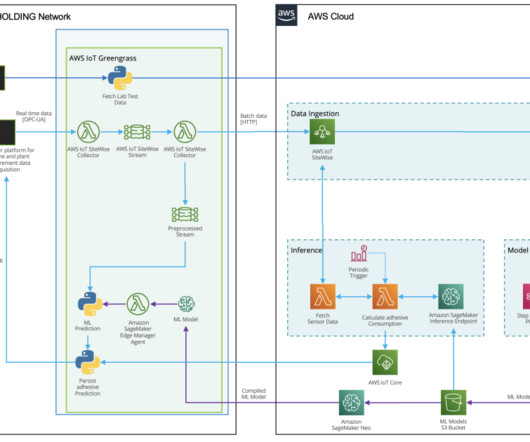
Data ingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Model training and optimization with SageMaker automatic model tuning Prior to the model training, a set of datapreparation activities are performed.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
input_ids return batch #apply the datapreparation function to all of our fine-tuning dataset samples using dataset's.map method. She is a technologist with a PhD in ComputerScience, a master’s degree in Education Psychology, and years of experience in datascience and independent consulting in AI/ML.
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Going into developing machine learning models with a hands-on, data-centric AI approach has its benefits and requires a few extra steps to achieve.
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. She has a Masters in ComputerScience from Rochester Institute of Technology. All code for this post is available in the GitHub repo.
Only involving necessary people to do case validation or augmentation tasks reduces the risk of document mishandling and human error when dealing with sensitive data. She has extensive experience in machine learning with a PhD degree in computerscience. When not helping customers, she enjoys outdoor activities.
We will start by setting up libraries and datapreparation. Setup and DataPreparation For this purpose, we will use the Pump Sensor Dataset , which contains readings of 52 sensors that capture various parameters (e.g., Or requires a degree in computerscience? detection of potential failures or issues).
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. Pooya Vahidi is a Senior Solutions Architect at AWS, passionate about computerscience, artificial intelligence, and cloud computing.
Data is split into a training dataset and a testing dataset. Both the training and validation data are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket for model training in the client account, and the testing dataset is used in the server account for testing purposes only.
Natural Language Processing (NLP) This is a field of computerscience that deals with the interaction between computers and human language. Computer Vision This is a field of computerscience that deals with the extraction of information from images and videos. Why is DataPreparation Crucial in AI Projects?
Often, to get an NLP application working for production use cases, we end up having to think about datapreparation and cleaning. This is covered with Haystack indexing pipelines , which allows you to design your own datapreparation steps, which ultimately write your documents to the database of your choice.
It simplifies the development and maintenance of ML models by providing a centralized platform to orchestrate tasks such as datapreparation, model training, tuning and validation. SageMaker Pipelines can help you streamline workflow management, accelerate experimentation and retrain models more easily. Nishant Krishnamoorthy is a Sr.
Data scientists can best improve LLM performance on specific tasks by feeding them the right dataprepared in the right way. Snorkel engineers and researchers, he noted, used scalable data development tools to improve many parts of this system, including their embedding and retrieval models. Slides for this session.
Option C: Use SageMaker Data Wrangler SageMaker Data Wrangler allows you to import data from various data sources including Amazon Redshift for a low-code/no-code way to prepare, transform, and featurize your data. She has extensive experience in machine learning with a PhD degree in ComputerScience.
Datapreparation In this post, we use several years of Amazon’s Letters to Shareholders as a text corpus to perform QnA on. For more detailed steps to prepare the data, refer to the GitHub repo. He holds a Bachelor’s degree in ComputerScience and Bioinformatics.
DataScience is an interdisciplinary field that uses scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It combines various techniques from statistics, mathematics, computerscience, and domain expertise to interpret complex data sets.
Data scientists can best improve LLM performance on specific tasks by feeding them the right dataprepared in the right way. Snorkel engineers and researchers, he noted, used scalable data development tools to improve many parts of this system, including their embedding and retrieval models. Slides for this session.
Understanding DataScienceDataScience involves analysing and interpreting complex data sets to uncover valuable insights that can inform decision-making and solve real-world problems. Verify that the data is accurate, complete, and up-to-date. High-quality data is the foundation of reliable analysis.
We will start by setting up libraries and datapreparation. Setup and DataPreparation To start, we will first download the Credit Card Fraud Detection dataset, which contains details (e.g., Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated?
Connection to the University of California, Irvine (UCI) The UCI Machine Learning Repository was created and is maintained by the Department of Information and ComputerSciences at the University of California, Irvine. Understanding how to handle these challenges effectively is key to building robust and accurate models.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. Recommended Educational Background Aspiring Azure Data Scientists typically benefit from a solid educational background in DataScience, computerscience, mathematics, or engineering.
In computerscience, a number can be represented with different levels of precision, such as double precision (FP64), single precision (FP32), and half-precision (FP16). Historical data is normally (but not always) independent inter-day, meaning that days can be parsed independently.
Key steps encompass: Datapreparation and splitting into training and validation sets. Iterative training across epochs with loss computation and backpropagation. Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computerscience?
However, another motivation was a personal reflection on a field that did not yet exist a little over a decade ago when I first began my advanced studies in computerscience. Moreover, the work carried out by data scientists is distinct from other types of data analysis, because it requires a wider breadth of multidisciplinary skills.
However, another motivation was a personal reflection on a field that did not yet exist a little over a decade ago when I first began my advanced studies in computerscience. Moreover, the work carried out by data scientists is distinct from other types of data analysis, because it requires a wider breadth of multidisciplinary skills.
In the following sections, we break down the datapreparation, model experimentation, and model deployment steps in more detail. Datapreparation Scalable Capital uses a CRM tool for managing and storing email data. Relevant email contents consist of subject, body, and the custodian banks.
He specializes in machine learning, AI, and computer vision domains, and holds a masters degree in ComputerScience from UT Dallas. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his free time, he enjoys traveling and photography.
Instead of relying on static datasets, it uses GPT-4 to generate instruction-following data across diverse scenarios. Data Curation in LLaVA Datapreparation in LLaVA is a three-tiered process: Conversational Data: Curating dialogues for interaction-focused tasks. Or requires a degree in computerscience?
We will start by setting up libraries and datapreparation. Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computerscience? intrusions or attacks) and “good” normal connections. That’s not the case.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about datascience and Bayesian statistics. in computerscience from the University of California, Berkeley; and Bachelors and Masters degrees fromMIT.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























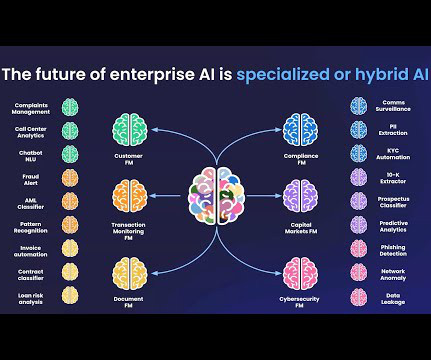






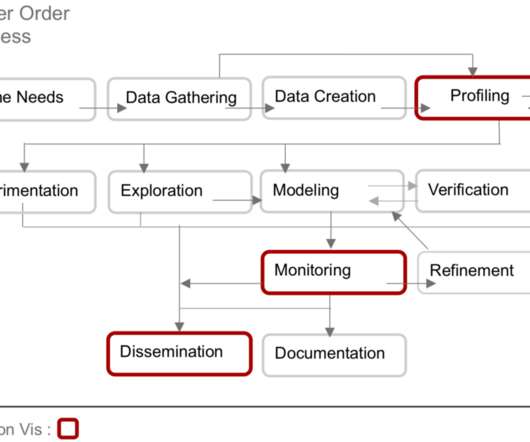
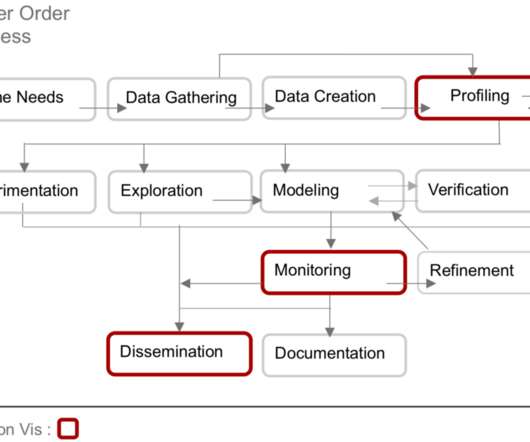











Let's personalize your content