This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
AI engineering is the discipline focused on developing tools, systems, and processes to enable the application of artificial intelligence in real-world contexts, which combines the principles of systems engineering, software engineering, and computerscience to create AI systems.
Deep Learning has been used to achieve state-of-the-art results in a variety of tasks, including image recognition, NaturalLanguageProcessing, and speech recognition. NaturalLanguageProcessing (NLP) This is a field of computerscience that deals with the interaction between computers and human language.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific entities or phrases. She has extensive experience in machine learning with a PhD degree in computerscience.
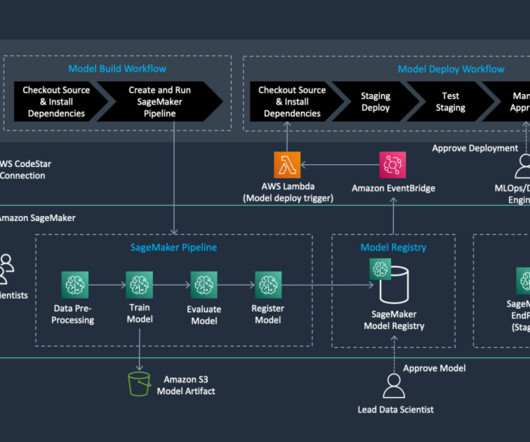
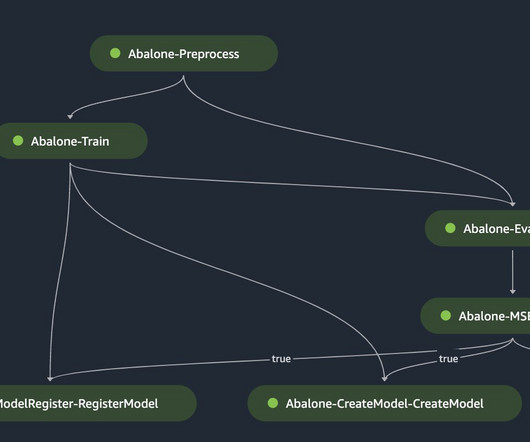
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. Romina’s areas of interest are naturallanguageprocessing, large language models, and MLOps.
It simplifies the development and maintenance of ML models by providing a centralized platform to orchestrate tasks such as datapreparation, model training, tuning and validation. SageMaker Pipelines can help you streamline workflow management, accelerate experimentation and retrain models more easily. Nishant Krishnamoorthy is a Sr.
Haystack FileConverters and PreProcessor allow you to clean and prepare your raw files to be in a shape and format that your naturallanguageprocessing (NLP) pipeline and language model of choice can deal with. An indexing pipeline may also include a step to create embeddings for your documents.
Datapreparation In this post, we use several years of Amazon’s Letters to Shareholders as a text corpus to perform QnA on. For more detailed steps to prepare the data, refer to the GitHub repo. He holds a Bachelor’s degree in ComputerScience and Bioinformatics.
It combines various techniques from statistics, mathematics, computerscience, and domain expertise to interpret complex data sets. AI encompasses various subfields, including Machine Learning (ML), NaturalLanguageProcessing (NLP), robotics, and computer vision.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. Algorithm Development: Crafting algorithms to solve complex business problems and optimise processes. Azure Cognitive Services offers ready-to-use models that seamlessly integrate into existing data workflows.
In computerscience, a number can be represented with different levels of precision, such as double precision (FP64), single precision (FP32), and half-precision (FP16). The benchmark used is the RoBERTa-Base, a popular model used in naturallanguageprocessing (NLP) applications, that uses the transformer architecture.
By implementing a modern naturallanguageprocessing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. In the following sections, we break down the datapreparation, model experimentation, and model deployment steps in more detail.
Instead of relying on static datasets, it uses GPT-4 to generate instruction-following data across diverse scenarios. Data Curation in LLaVA Datapreparation in LLaVA is a three-tiered process: Conversational Data: Curating dialogues for interaction-focused tasks. Or requires a degree in computerscience?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content