This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional exact nearestneighbor search methods (e.g., brute-force search and k -nearestneighbor (kNN)) work by comparing each query against the whole dataset and provide us the best-case complexity of. On Line 28 , we sort the distances and select the top knearestneighbors.
Dylan holds a BSc and MEng degree in ComputerScience from Cornell University. Dylan has decades of experience working directly with customers and creating products and solutions in the database, analytics and AI/ML domain. His primary interests include distributed systems.
We shall look at various types of machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. R Studios and GIS In a previous article, I wrote about GIS and R.,
According to IBM, machine learning is a subfield of computerscience and artificial intelligence (AI) that focuses on using data and algorithms to simulate human learning processes while progressively increasing their accuracy.
Leveraging a comprehensive dataset of diverse fault scenarios, various machine learning algorithms—including Random Forest (RF), K-NearestNeighbors (KNN), and Long Short-Term Memory (LSTM) networks—are evaluated. An ensemble methodology, RF-LSTM Tuned KNN, is proposed to enhance detection accuracy and robustness.
The proven classifier models, k - nearestneighbor (KNN) and support vecter machine (SVM) models, are integrated to classify the extracted deep CNN features. 3 distinct experiments with the same deep CNN features but different classifier models (softmax, KNN, SVM) are performed.
Formally, often k-nearestneighbors (KNN) or approximate nearestneighbor (ANN) search is often used to find other snippets with similar semantics. He received his PhD in ComputerScience from Purdue University in 2008. in ComputerScience from University of Massachusetts Amherst in 2006.
ML is a computerscience, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others.
This technique expresses a text item as a feature vector, which can be used to compute cosine similarity with other item feature vectors. Figure 7: TF-IDF calculation (source: Towards Data Science ). The item ratings of these -closest neighbors are then used to recommend items to the given user. That’s not the case.
To solve the problem of finding the field of study for any given paper, simply perform a k-nearestneighbor search on the embeddings. Da got his PhD in computerscience from the Johns Hopkins University. In this case, the model reaches an MRR of 0.31 on the test set of the constructed graph.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. To make this work, we need to transform the textual interactions into a format that allows algebraic operations.
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. He has a degree in Mathematics and ComputerScience from the University of Illinois at Urbana Champaign. Some plays are mixed into other coverage types, as shown in the following figure (right).
In most cases, you will use an OpenSearch Service vector database as a knowledge base, performing a k-nearestneighbor (k-NN) search to incorporate semantic information in the retrieval with vector embeddings. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph.
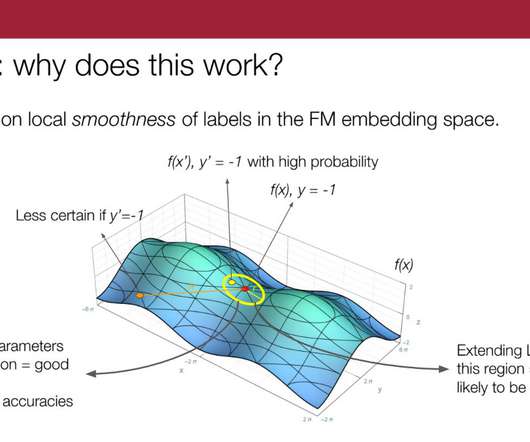
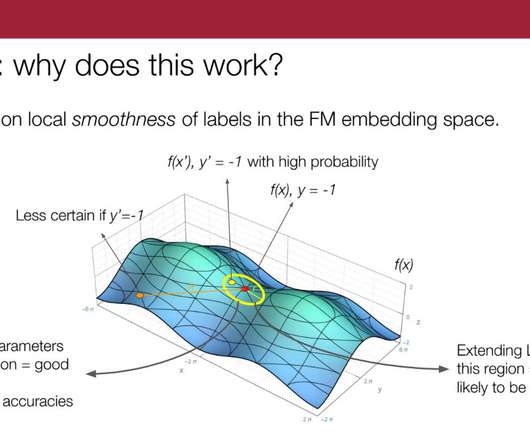
I am a PhD student in the computerscience department at Stanford, advised by Chris Ré working on some broad themes of understanding data-centric AI, weak supervision and theoretical machine learning. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
I am a PhD student in the computerscience department at Stanford, advised by Chris Ré working on some broad themes of understanding data-centric AI, weak supervision and theoretical machine learning. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
Read the full article here — [link] For final-year students pursuing a degree in computerscience or related disciplines, engaging in machine learning projects can be an excellent way to consolidate theoretical knowledge, gain practical experience, and showcase their skills to potential employers.
Ce Zhang is an associate professor in ComputerScience at ETH Zürich. You can approximate your machine learning training components into some simpler classifiers—for example, a k-nearestneighbors classifier. This talk was followed by an audience Q&A conducted by Snorkel AI’s Priyal Aggarwal.
Ce Zhang is an associate professor in ComputerScience at ETH Zürich. You can approximate your machine learning training components into some simpler classifiers—for example, a k-nearestneighbors classifier. This talk was followed by an audience Q&A conducted by Snorkel AI’s Priyal Aggarwal.
Artificial Intelligence (AI): A branch of computerscience focused on creating systems that can perform tasks typically requiring human intelligence. KK-Means Clustering: An unsupervised learning algorithm that partitions data into K distinct clusters based on feature similarity.
For example, The K-NearestNeighbors algorithm can identify unusual login attempts based on the distance to typical login patterns. The Local Outlier Factor (LOF) algorithm measures the local density deviation of a data point with respect to its neighbors. Or requires a degree in computerscience?
Amazon OpenSearch Serverless is a serverless deployment option for Amazon OpenSearch Service, a fully managed service that makes it simple to perform interactive log analytics, real-time application monitoring, website search, and vector search with its k-nearestneighbor (kNN) plugin.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content