This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
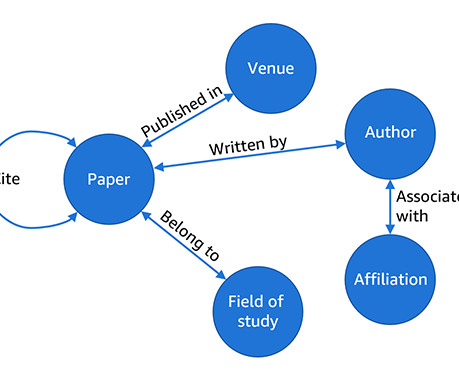
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
Amazon OpenSearch Serverless is a serverless deployment option for Amazon OpenSearch Service, a fully managed service that makes it simple to perform interactive log analytics, real-time application monitoring, website search, and vector search with its k-nearestneighbor (kNN) plugin.
In this tutorial, well explore how OpenSearch performs k-NN (k-NearestNeighbor) search on embeddings. How OpenSearch Uses Neural Search and k-NN Indexing Figure 6 illustrates the entire workflow of how OpenSearch processes a neural query and retrieves results using k-NearestNeighbor (k-NN) search.
a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. With GraphStorm, we release the tools that Amazon uses internally to bring large-scale graph ML solutions to production. license on GitHub. GraphStorm 0.1
Machine learning (ML) has proven that it is here with us for the long haul, everyone who had their doubts by calling it a phase should by now realize how wrong they are, ML has being used in various sector’s of society such as medicine, geospatial data, finance, statistics and robotics.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Vector and Semantic Search: Leverages machine learning-powered search techniques, including k-NN (k-nearestneighbors) and dense vector embeddings, for applications like AI-driven search, recommendation systems, and similarity search. Learning to Rank (LTR) and Re-Ranking: Uses ML models (e.g., Thats not the case.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. In this post, we deep dive into the technical details of this ML model.
Ce Zhang is an associate professor in ComputerScience at ETH Zürich. The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. You can approximate your machine learning training components into some simpler classifiers—for example, a k-nearestneighbors classifier.
Ce Zhang is an associate professor in ComputerScience at ETH Zürich. The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. You can approximate your machine learning training components into some simpler classifiers—for example, a k-nearestneighbors classifier.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module.
For more information, see Creating connectors for third-party ML platforms. Create an OpenSearch model When you work with machine learning (ML) models, in OpenSearch, you use OpenSearchs ml-commons plugin to create a model. You created an OpenSearch ML model group and model that you can use to create ingest and search pipelines.
Powering Neural Search : Enables advanced similarity-based retrieval using OpenSearchs k-NN (k-NearestNeighbors) indexing. Registering the Model in OpenSearch We first register the model using OpenSearchs ML Commons API. Or requires a degree in computerscience? The following function from utils.py
I am a PhD student in the computerscience department at Stanford, advised by Chris Ré working on some broad themes of understanding data-centric AI, weak supervision and theoretical machine learning. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
I am a PhD student in the computerscience department at Stanford, advised by Chris Ré working on some broad themes of understanding data-centric AI, weak supervision and theoretical machine learning. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
Read the full article here — [link] For final-year students pursuing a degree in computerscience or related disciplines, engaging in machine learning projects can be an excellent way to consolidate theoretical knowledge, gain practical experience, and showcase their skills to potential employers.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content