This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Real-world applications of CatBoost in predicting student engagement By the end of this story, you’ll discover the power of CatBoost, both with and without cross-validation, and how it can empower educational platforms to optimize resources and deliver personalized experiences. Key Advantages of CatBoost How CatBoost Works?
Among these trailblazers stands an exceptional individual, Mr. Nirmal, a visionary in the realm of data science, who has risen to become a driving […] The post The Success Story of Microsoft’s Senior DataScientist appeared first on Analytics Vidhya.
By systematically exploring a set range of hyperparameters, grid search enables datascientists and machine learning practitioners to significantly enhance the performance of their algorithms. Cross-validation with grid search Cross-validation is a fundamental technique that ensures the reliability of machine learning models.
Definition of validation dataset A validation dataset is a separate subset used specifically for tuning a model during development. By evaluating performance on this dataset, datascientists can make informed adjustments to enhance the model without compromising its integrity.
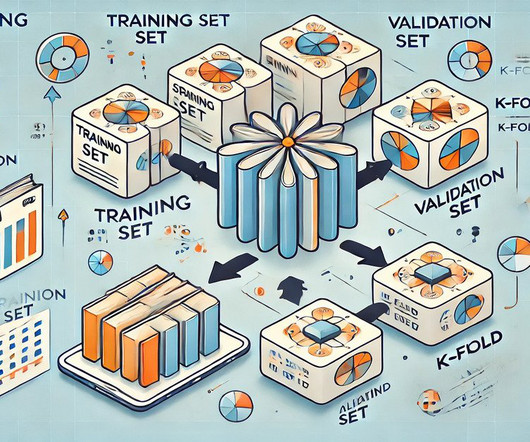
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Various methods, like K-Fold and Stratified K-Fold, cater to different Data Scenarios. Various methods, like K-Fold and Stratified K-Fold, cater to different Data Scenarios.
Importance of validation sets Model tuning: Validation sets allow datascientists to adjust model parameters and select optimal algorithms effectively. Purpose and functions of the validation set The validation set serves multiple purposes that are integral to the model training process.
Datascientists use a technique called crossvalidation to help estimate the performance of a model as well as prevent the model from… Continue reading on MLearning.ai »
Whether youre predicting stock prices, diagnosing diseases, or optimizing marketing campaigns, the question remains: which model works best for my data? Traditionally, we rely on cross-validation to test multiple models XGBoost, LGBM, Random Forest, etc. and pick the best one based on validation performance.
A Light Gradient Boosted Trees Regressor with Early Stopping model was trained without any geospatial data on 5,657 residential home listings to provide a baseline for comparison. This produced a RMSLE CrossValidation of 0.3530. By example, this model predicted a roughly $21,000 increase in price compared to its true price.
A cheat sheet for DataScientists is a concise reference guide, summarizing key concepts, formulas, and best practices in Data Analysis, statistics, and Machine Learning. It serves as a handy quick-reference tool to assist data professionals in their work, aiding in data interpretation, modeling , and decision-making processes.
Validating its performance on unseen data is crucial. Python offers various tools like train-test split and cross-validation to assess model generalizability. It is a crucial step in the model development process to ensure that the model generalizes well to unseen data and does not overfit or underfit the training data.
Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. The cross-validations for all winners were reproduced by the DrivenData team. Lower is better. Unsurprisingly, the 0.10 quantile was easier to predict than the 0.90
DataScientists are highly in demand across different industries for making use of the large volumes of data for analysisng and interpretation and enabling effective decision making. One of the most effective programming languages used by DataScientists is R, that helps them to conduct data analysis and make future predictions.
Well-prepared data is essential for developing robust predictive models. These strategies allow datascientists to focus on relevant data subsets, expediting the modeling process without sacrificing accuracy. Sampling techniques To enhance model development efficiency, sampling techniques can be utilized.
The torchvision package includes datasets and transformations for testing and validating computer vision models. Scikit-learn Scikit-learn is a versatile Python library that offers various algorithms and model evaluation metrics, including cross-validation and grid search for hyperparameter tuning.
Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. To avoid leakage during cross-validation, we grouped all plays from the same game into the same fold. Marc van Oudheusden is a Senior DataScientist with the Amazon ML Solutions Lab team at Amazon Web Services.
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together datascientists to tackle one of the most dynamic aspects of racing — pit stop strategies. Firepig refined predictions using detailed feature engineering and cross-validation.
Many datascientists I’ve spoken with agree that LLMs represent the future, yet they often feel that these models are too complex and detached from the everyday challenges faced in enterprise environments. Last Updated on September 2, 2024 by Editorial Team Author(s): Ori Abramovsky Originally published on Towards AI.
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machine learning: 1. This is often done using techniques such as cross-validation or grid search. What are kernels? Types of kernels. Purpose of kernels.
Meet the Winners ¶ Prize Name 1st place Rasyid Ridha (rasyidstat) 2nd place Roman Chernenko and Vitaly Bondar (Team ck-ua) 3rd place Matthew Aeschbacher (oshbocker) Rasyid Ridha ¶ Place: 1st Prize: $25,000 Home country: Indonesia Username: rasyidstat Background: Experienced DataScientist specializing in time series and forecasting.
This guest post is co-written by Lydia Lihui Zhang, Business Development Specialist, and Mansi Shah, Software Engineer/DataScientist, at Planet Labs. Planet and AWS’s partnership on geospatial ML SageMaker geospatial capabilities empower datascientists and ML engineers to build, train, and deploy models using geospatial data.
Datascientists train multiple ML algorithms to examine millions of consumer data records, identify anomalies, and evaluate if a person is eligible for credit. This is a common problem that datascientists face when training their models. About the Authors Tristan Miller is a Lead DataScientist at Best Egg.
While it requires careful selection of the number of components and can be computationally intensive, its flexibility and interpretability make it a staple in the datascientists toolkit. Frequently Asked Questions What is the Main Advantage of a Gaussian Mixture Model Over K-Means?
Currently pursuing graduate studies at NYU's center for data science. Alejandro Sáez: DataScientist with consulting experience in the banking and energy industries currently pursuing graduate studies at NYU's center for data science.
Fantasy Football is a popular pastime for a large amount of the world, we gathered data around the past 6 seasons of player performance data to see what our community of datascientists could create. By leveraging cross-validation, we ensured the model’s assessment wasn’t reliant on a singular data split.
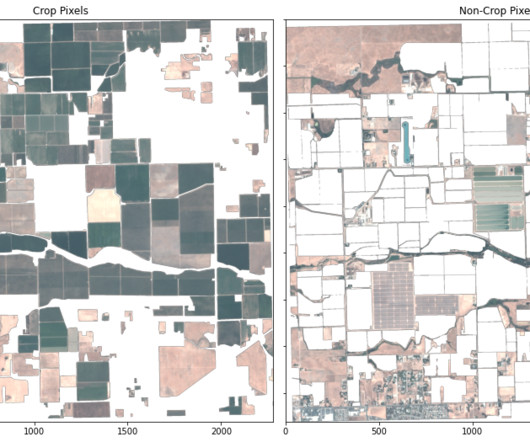
S1 and S2 features and AGBM labels were carefully preprocessed according to statistics of training data. Training data was splited into 5 folds for crossvalidation. Outliers were replaced by the lower or upper limitations. Incorporating time and location information for each pixel (i.e.
Steamlining model management and deployment with SageMaker Amazon SageMaker is a managed machine learning platform that provides datascientists and data engineers familiar concepts and tools to build, train, deploy, govern , and manage the infrastructure needed to have highly available and scalable model inference endpoints.
By selecting MLOps tools that address these vital aspects, you will create a continuous cycle from datascientists to deployment engineers to deploy models quickly without sacrificing quality. Examples include: Cross-validation techniques for better model evaluation.
Model Extraction and Registration For the first version, I want to fit a KNeighborsClassifier to fit the data. Additionally, I will use StratifiedKFold cross-validation to perform multiple train-test splits. After fitting our model, we will extract it with the Joblib library and finally get it registered in the Model Registry.
However, over the past decade, its usage has evolved significantly due to several key factors: Kaggle Competitions: Kaggle emerged in 2010 [1] and popularized data science and machine learning competitions using real-world tabular datasets.
Understanding these mathematical foundations allows datascientists to make informed decisions, improving model accuracy and interpretability. Here, we discuss two critical aspects: the impact on model accuracy and the use of cross-validation for comparison.
Understanding these concepts is paramount for any datascientist, machine learning engineer, or researcher striving to build robust and accurate models. To mitigate variance in machine learning, techniques like regularization, cross-validation, early stopping, and using more diverse and balanced datasets can be employed.
Revolutionizing Healthcare through Data Science and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating data science, machine learning, and information technology.
EDA, imputation, encoding, scaling, extraction, outlier handling, and cross-validation ensure robust models. Feature Engineering enhances model performance, and interpretability, mitigates overfitting, accelerates training, improves data quality, and aids deployment. Steps of Feature Engineering 1.
Many datascientists I’ve spoken with agree that LLMs represent the future, yet they often feel that these models are too complex and detached from the everyday challenges faced in enterprise environments. Prompts are simply the new models. The key challenge is the conceptual shift; once you’ve made that, the rest will follow.
Data Science interviews are pivotal moments in the career trajectory of any aspiring datascientist. Having the knowledge about the data science interview questions will help you crack the interview. What is cross-validation, and why is it used in Machine Learning?
The results of this GCMS challenge could not only support NASA scientists to more quickly analyze data, but is also a proof-of-concept of the use of data science and machine learning techniques on complex GCMS data for future missions. Ridge models are in principal the least overfitting models.
programs offer comprehensive Data Analysis and Statistical methods training, providing a solid foundation for Statisticians and DataScientists. It emphasises probabilistic modeling and Statistical inference for analysing big data and extracting information. You will learn by practising DataScientists.
In some cases, cross-validation techniques like k-fold cross-validation or stratified sampling may be used to get more reliable estimates of performance. Consider performing this tuning within a cross-validation framework to avoid overfitting to a specific test set.
Cross-validation is recommended as best practice to provide reliable results because of this. Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables datascientists & ML teams to track, compare, explain, & optimize their experiments.
Using built-in automation workflows , either through the no-code Graphical User Interface (GUI) or the code-centric DataRobot for datascientists , both datascientists and non-datascientists—such as asset managers and investment analysts—can build, evaluate, understand, explain, and deploy their own models.
Model Evaluation and Tuning After building a Machine Learning model, it is crucial to evaluate its performance to ensure it generalises well to new, unseen data. Unit testing ensures individual components of the model work as expected, while integration testing validates how those components function together.
Were using Bayesian optimization for hyperparameter tuning and cross-validation to reduce overfitting. The data set contains features like opportunity name, opportunity details, needs, associated product name, product details, product groups. This helps make sure that the clustering is accurate and relevant.
Experimentation and cross-validation help determine the dataset’s optimal ‘K’ value. Distance Metrics Distance metrics measure the similarity between data points in a dataset. Cross-Validation: Employ techniques like k-fold cross-validation to evaluate model performance and prevent overfitting.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content