This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. Step-by-Step Guide: Predicting Student Engagement with CatBoost and Cross-Validation 1.
Grid search is a powerful technique that plays a crucial role in optimizing machinelearning models. By systematically exploring a set range of hyperparameters, grid search enables datascientists and machinelearning practitioners to significantly enhance the performance of their algorithms.
Machinelearning models are algorithms designed to identify patterns and make predictions or decisions based on data. These models are trained using historical data to recognize underlying patterns and relationships. Once trained, they can be used to make predictions on new, unseen data.
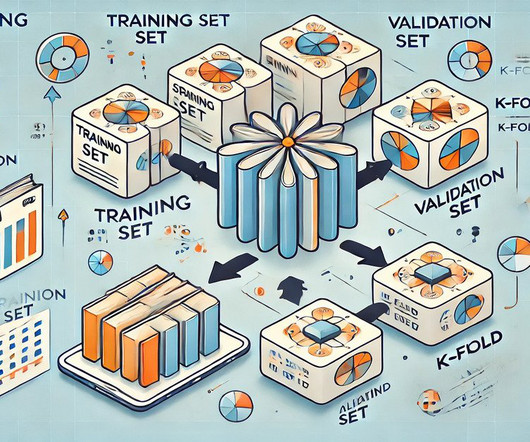
Validation set plays a pivotal role in the model training process for machinelearning. It serves as a safeguard, ensuring that models not only learn from the data they are trained on but are also able to generalize effectively to unseen examples. What is a validation set? What is a validation set?
Summary: Cross-validation in MachineLearning is vital for evaluating model performance and ensuring generalisation to unseen data. Various methods, like K-Fold and Stratified K-Fold, cater to different Data Scenarios. Various methods, like K-Fold and Stratified K-Fold, cater to different Data Scenarios.
While DevOps and MLOps share many similarities, MLOps requires a more specialized set of tools and practices to address the unique challenges posed by data-driven and computationally intensive ML workflows. Examples include: Cross-validation techniques for better model evaluation.
Datascientists use a technique called crossvalidation to help estimate the performance of a model as well as prevent the model from… Continue reading on MLearning.ai »
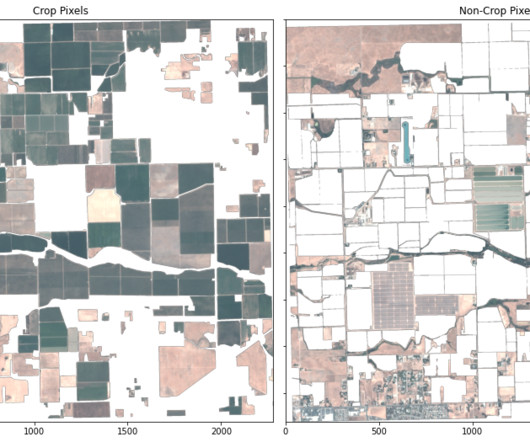
This guest post is co-written by Lydia Lihui Zhang, Business Development Specialist, and Mansi Shah, Software Engineer/DataScientist, at Planet Labs. In this post, we illustrate how to use a segmentation machinelearning (ML) model to identify crop and non-crop regions in an image.
Photo by Agence Olloweb on Unsplash Machinelearning model selection has always been a challenge. Whether youre predicting stock prices, diagnosing diseases, or optimizing marketing campaigns, the question remains: which model works best for my data? Upgrade to access all of Medium.
Location data is a key dimension whose volume and availability has grown exponentially in the last decade. A Light Gradient Boosted Trees Regressor with Early Stopping model was trained without any geospatial data on 5,657 residential home listings to provide a baseline for comparison. This produced a RMSLE CrossValidation of 0.3530.
The NAS is investing in new ways to bring vast amounts of data together with state-of-the-art machinelearning to improve air travel for everyone. Federated learning is a technique for collaboratively training a shared machinelearning model across data from multiple parties while preserving each party's data privacy.
Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. The cross-validations for all winners were reproduced by the DrivenData team. Lower is better. Unsurprisingly, the 0.10 quantile was easier to predict than the 0.90
Predictive modeling plays a crucial role in transforming vast amounts of data into actionable insights, paving the way for improved decision-making across industries. By leveraging statistical techniques and machinelearning, organizations can forecast future trends based on historical data.
Summary : Feature selection in MachineLearning identifies and prioritises relevant features to improve model accuracy, reduce overfitting, and enhance computational efficiency. Introduction Feature selection in MachineLearning is identifying and selecting the most relevant features from a dataset to build efficient predictive models.
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machinelearning: 1. Machinelearning algorithms rely on mathematical functions called “kernels” to make predictions based on input data.
Summary : Building a machinelearning model is just one step. Validating its performance on unseen data is crucial. Python offers various tools like train-test split and cross-validation to assess model generalizability. This helps identify overfitting and select the best model for real-world use.
Feature engineering in machinelearning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through Exploratory Data Analysis , imputation, and outlier handling, robust models are crafted. Hence, it is important to discuss the impact of feature engineering in MachineLearning.
The concepts of bias and variance in MachineLearning are two crucial aspects in the realm of statistical modelling and machinelearning. Understanding these concepts is paramount for any datascientist, machinelearning engineer, or researcher striving to build robust and accurate models.
A cheat sheet for DataScientists is a concise reference guide, summarizing key concepts, formulas, and best practices in Data Analysis, statistics, and MachineLearning. What are Cheat Sheets in Data Science? It includes data collection, data cleaning, data analysis, and interpretation.
Summary: MachineLearning Engineer design algorithms and models to enable systems to learn from data. Introduction MachineLearning is rapidly transforming industries. Who is a MachineLearning Engineer? They ensure that MachineLearning solutions are accurate, scalable, and maintainable.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion by 2031, growing at a CAGR of 34.20%.
In recent years, the field of machinelearning has gained tremendous momentum, offering powerful solutions and valuable insights from vast amounts of data. However, the process of building machinelearning models traditionally involved a time-consuming and resource-intensive approach, requiring extensive expertise.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
With advanced analytics derived from machinelearning (ML), the NFL is creating new ways to quantify football, and to provide fans with the tools needed to increase their knowledge of the games within the game of football. Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season.
Many datascientists I’ve spoken with agree that LLMs represent the future, yet they often feel that these models are too complex and detached from the everyday challenges faced in enterprise environments. Last Updated on September 2, 2024 by Editorial Team Author(s): Ori Abramovsky Originally published on Towards AI.
Summary: The KNN algorithm in machinelearning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Nevertheless, its applications across classification, regression, and anomaly detection tasks highlight its importance in modern data analytics methodologies.
Widely used in image segmentation, speech recognition, and anomaly detection, GMM is essential for complex Data Analysis. Introduction The Gaussian Mixture Model (GMM) stands as one of the most powerful and flexible tools in the field of unsupervised MachineLearning and statistics.
Summary: Feature extraction in MachineLearning is essential for transforming raw data into meaningful features that enhance model performance. Understanding techniques, such as dimensionality reduction and feature encoding, is crucial for effective data preprocessing and analysis. The global market was valued at USD 36.73
Amazon SageMaker is a fully managed machinelearning (ML) service providing various tools to build, train, optimize, and deploy ML models. Datascientists train multiple ML algorithms to examine millions of consumer data records, identify anomalies, and evaluate if a person is eligible for credit.
Meet the Winners ¶ Prize Name 1st place Rasyid Ridha (rasyidstat) 2nd place Roman Chernenko and Vitaly Bondar (Team ck-ua) 3rd place Matthew Aeschbacher (oshbocker) Rasyid Ridha ¶ Place: 1st Prize: $25,000 Home country: Indonesia Username: rasyidstat Background: Experienced DataScientist specializing in time series and forecasting.
DataScientists are highly in demand across different industries for making use of the large volumes of data for analysisng and interpretation and enabling effective decision making. One of the most effective programming languages used by DataScientists is R, that helps them to conduct data analysis and make future predictions.
Tabular data has been around for decades and is one of the most common data types used in data analysis and machinelearning. Traditionally, tabular data has been used for simply organizing and reporting information. The synthetic datasets were created using a deep-learning generative network called CTGAN.[3]
Mastering Tree-Based Models in MachineLearning: A Practical Guide to Decision Trees, Random Forests, and GBMs Image created by the author on Canva Ever wondered how machines make complex decisions? Just like a tree branches out, tree-based models in machinelearning do something similar. Let’s get started!
Steamlining model management and deployment with SageMaker Amazon SageMaker is a managed machinelearning platform that provides datascientists and data engineers familiar concepts and tools to build, train, deploy, govern , and manage the infrastructure needed to have highly available and scalable model inference endpoints.
I am involved in an educational program where I teach machine and deep learning courses. Machinelearning is my passion and I often take part in competitions. S1 and S2 features and AGBM labels were carefully preprocessed according to statistics of training data. What motivated you to compete in this challenge?
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together datascientists to tackle one of the most dynamic aspects of racing — pit stop strategies. With every second on the track critical, the challenge showcased how data can shape decisions that define race outcomes.
Revolutionizing Healthcare through Data Science and MachineLearning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating data science, machinelearning, and information technology.
First-time project and model registration Photo by Isaac Smith on Unsplash The world of machinelearning and data science is awash with technicalities. Machinelearning problems could grow to such an extent that you constantly lose track of what you are doing. The fix around this is model tracking.
The results of this GCMS challenge could not only support NASA scientists to more quickly analyze data, but is also a proof-of-concept of the use of data science and machinelearning techniques on complex GCMS data for future missions. What motivated you to compete in this challenge?
Summary of approach: In the end I managed to create two submissions, both employing an ensemble of models trained across all 10-fold cross-validation (CV) splits, achieving a private leaderboard (LB) score of 0.7318. I consider myself as a machinelearning engineer who enjoys taking part in various machinelearning competitions.
Fantasy Football is a popular pastime for a large amount of the world, we gathered data around the past 6 seasons of player performance data to see what our community of datascientists could create. By leveraging cross-validation, we ensured the model’s assessment wasn’t reliant on a singular data split.
Many datascientists I’ve spoken with agree that LLMs represent the future, yet they often feel that these models are too complex and detached from the everyday challenges faced in enterprise environments. Prompts are simply the new models. The key challenge is the conceptual shift; once you’ve made that, the rest will follow.
Data Science interviews are pivotal moments in the career trajectory of any aspiring datascientist. Having the knowledge about the data science interview questions will help you crack the interview. Data Science skills that will help you excel professionally. Explain the bias-variance tradeoff in MachineLearning.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machinelearning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. Visualizing data using t-SNE.” Selvaraju, Ramprasaath R.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content