This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
K-NearestNeighbors (KNN): This method classifies a data point based on the majority class of its Knearestneighbors in the training data. Document Clustering: Grouping documents based on topic or content for efficient information retrieval. accuracy).
The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. What are KNearestNeighbors in Machine Learning? Definition of KNN Algorithm KNearestNeighbors (KNN) is a simple yet powerful machine learning algorithm for classification and regression tasks.
Figure 5 Feature Extraction and Evaluation Because most classifiers and learning algorithms require numerical feature vectors with a fixed size rather than raw text documents with variable length, they cannot analyse the text documents in their original form.
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
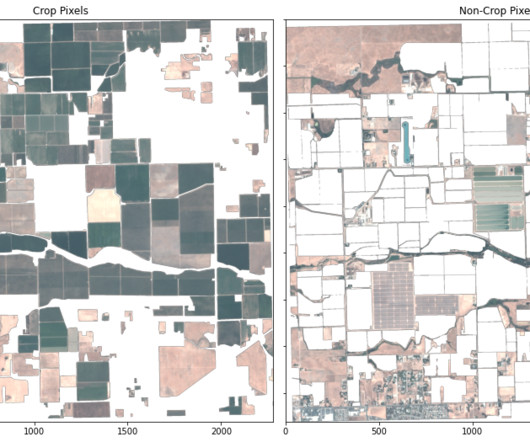
In this analysis, we use a K-nearestneighbors (KNN) model to conduct crop segmentation, and we compare these results with ground truth imagery on an agricultural region. The number of neighbors, a parameter greatly affecting the estimator’s performance, is tuned using cross-validation in KNN cross-validation.
Cross-Validation: A model evaluation technique that assesses how well a model will generalise to an independent dataset. J Jupyter Notebook: An open-source web application that allows users to create and share documents containing live code, equations, visualisations, and narrative text.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content