This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By understanding machinelearning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Predict traffic jams by learning patterns in historical traffic data. Learn in detail about machinelearning algorithms 2.
MLOps practices include cross-validation, training pipeline management, and continuous integration to automatically test and validate model updates. Examples include: Cross-validation techniques for better model evaluation. Managing training pipelines and workflows for a more efficient and streamlined process.
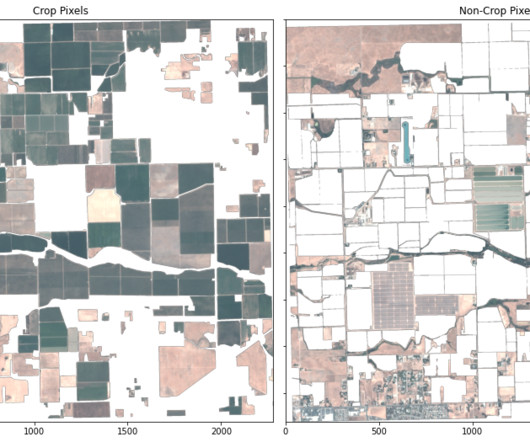
In this post, we illustrate how to use a segmentation machinelearning (ML) model to identify crop and non-crop regions in an image. Train the classifier on crop and non-crop pixels The KNN classification is performed with the scikit-learn KNeighborsClassifier.
Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. Explainability and Communication Bonus Track where solvers produced short documents explaining and communicating forecasts to water managers. Lower is better. Unsurprisingly, the 0.10
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
The NAS is investing in new ways to bring vast amounts of data together with state-of-the-art machinelearning to improve air travel for everyone. Federated learning is a technique for collaboratively training a shared machinelearning model across data from multiple parties while preserving each party's data privacy.
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machinelearning (ML) services for a mortgage underwriting use case. Solution overview Documentvalidation is a critical type of input for mortgage fraud decisions.
Figure 1 Preprocessing Data preprocessing is an essential step in building a MachineLearning model. We will generate a measure called Term Frequency, Inverse Document Frequency, shortened to tf-idf for each term in our dataset. the same result we are trying to achieve with “multi_class_classifier.ipynb”.
Summary: Hyperparameters in MachineLearning are essential for optimising model performance. They are set before training and influence learning rate and batch size. This summary explores hyperparameter categories, tuning techniques, and tools, emphasising their significance in the growing MachineLearning landscape.
Feature engineering in machinelearning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Embrace the benefits of feature engineering to unlock the full potential of your Machine-Learning endeavors and achieve accurate predictions in diverse real-world scenarios.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion in 2022 and is expected to grow to USD 505.42
Image annotation is the act of labeling images for AI and machinelearning models. The resulting structured data is then used to train a machinelearning algorithm. There are a lot of image annotation techniques that can make the process more efficient with deep learning.
Summary: The KNN algorithm in machinelearning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Unlocking the Power of KNN Algorithm in MachineLearningMachinelearning algorithms are significantly impacting diverse fields.
Summary: Feature extraction in MachineLearning is essential for transforming raw data into meaningful features that enhance model performance. Introduction MachineLearning has become a cornerstone in transforming industries worldwide. The global market was valued at USD 36.73 from 2023 to 2030.
Summary: Support Vector Machine (SVM) is a supervised MachineLearning algorithm used for classification and regression tasks. Introduction MachineLearning has revolutionised various industries by enabling systems to learn from data and make informed decisions. What is the SVM Algorithm in MachineLearning?
I saw this as an exciting opportunity to test and expand my machinelearning skills in a practical, real-world setting. Also, I have 10 years of experience with C++ cross-platform development, especially in the medical imaging domain, and for embedded solutions. quantile forecast. What motivated you to compete in this challenge?
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of PyCaret} Image by Author In the rapidly evolving realm of data science, the imperative to automate machinelearning workflows has become an indispensable requisite for enterprises aiming to outpace their competitors.
Photo by Robo Wunderkind on Unsplash In general , a data scientist should have a basic understanding of the following concepts related to kernels in machinelearning: 1. Machinelearning algorithms rely on mathematical functions called “kernels” to make predictions based on input data. What are kernels? Linear Kernels 2.
Here, we use AWS HealthOmics storage as a convenient and cost-effective omic data store and Amazon Sagemaker as a fully managed machinelearning (ML) service to train and deploy the model. Data preparation and loading into sequence store The initial step in our machinelearning workflow focuses on preparing the data.
Participants used historical data from past Mexican Grand Prix events and insights from the 2024 F1 season to create machine-learning models capable of predicting key race elements. Aleks ensured the model could be implemented without complications by delivering structured outputs and comprehensive documentation.
Indeed, the most robust predictive trading algorithms use machinelearning (ML) techniques. Moving on to the fun stuff… Setting up our environment First, we’ll set up our environment with a Prophet machinelearning model to forecast prices. It’s time to use machinelearning to forecast prices. Easy peasy.
Through machinelearning and artificial intelligence, we’ve seen how organizations can harness this information to make informed decisions and grow their businesses. Detecting and removing outliers from your data can significantly improve the accuracy of any other machinelearning models you train on your data.
Source: [link] Similarly, while building any machinelearning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. MLOps tools play a pivotal role in every stage of the machinelearning lifecycle. What is MLOps?
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machinelearning and deep learning. Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence.
By understanding crucial concepts like MachineLearning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
MachineLearning models adapt to changing data dynamics for reliable predictions. AI in Time Series Forecasting Artificial Intelligence (AI) has transformed Time Series Forecasting by introducing models that can learn from data without explicit programming for each scenario. What is Time Series Forecasting? accuracy, precision).
Some of the most common performance metrics for machinelearning models include: Classification Model Metrics A classification model is a model that is trained to assign class labels to input data based on certain patterns or features. They vary according to the model type and use cases.
Summary: XGBoost is a highly efficient and scalable MachineLearning algorithm. Introduction Boosting is a powerful MachineLearning ensemble technique that combines multiple weak learners, typically decision trees, to form a strong predictive model. It reduces overfitting using L1 and L2 penalties.
Unlocking Predictive Power: How Bayes’ Theorem Fuels Naive Bayes Algorithm to Solve Real-World Problems [link] Introduction In the constantly shifting realm of machinelearning, we can see that many intricate algorithms are rooted in the fundamental principles of statistics and probability.
We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods. LLMs use a combination of machinelearning and human input; image from OpenAI Data preparation and preprocessing The first, and perhaps most crucial, step in LLM training is data preparation.
Amazon SageMaker Pipelines includes features that allow you to streamline and automate machinelearning (ML) workflows. In both LSA and LDA, each document is treated as a collection of words only and the order of the words or grammatical role does not matter, which may cause some information loss in determining the topic.
A cheat sheet for Data Scientists is a concise reference guide, summarizing key concepts, formulas, and best practices in Data Analysis, statistics, and MachineLearning. MachineLearningMachinelearning is at the heart of Data Science.
This was necessary as the registry is where a machinelearning practitioner can keep track of experiments and model versions. Sometimes this is a good thing as it may be beneficial to the outcome that a data scientist or machinelearning practitioner may desire.
DataRobot combines these datasets and data types into one training dataset used to build machinelearning models. For example, the model produced a RMSLE (Root Mean Squared Logarithmic Error) CrossValidation of 0.0825 and a MAPE (Mean Absolute Percentage Error) CrossValidation of 6.215.
For more details on the model components, check out the models documentation. Complex Dependencies are Captured: The selfattention mechanism in transformers effectively models longterm dependencies. Additional Functionalities But theres more to APDTFlow than just the forecasting engine.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machinelearning applications from start to finish. Please refer to this documentation link. This is part 2 of the three-series article. We can perform tons of operations like pandas DataFrame.
Resources Comet Documentation: Comet's official documentation provides detailed information on integrating Comet into machinelearning projects, tracking experiments, and visualizing results. The cosmos of optimized recommendations await, ready to delight and inspire users around the globe.
Given that the whole theory of machinelearning assumes today will behave at least somewhat like yesterday, what can algorithms and models do for you in such a chaotic context ? This is a relatively straightforward process that handles training with cross-validation, optimization, and, later on, full dataset training.
We’re about to learn how to create a clean, maintainable, and fully reproducible machinelearning model training pipeline. The preprocessing stage involves cleaning, transforming, and encoding the data, making it suitable for machinelearning algorithms. Too good to be true? Not at all.
Scikit-learn stands out as a prominent Python library in the machinelearning realm, providing a versatile toolkit for data scientists and enthusiasts alike. Its comprehensive functionality caters to various tasks, making it a go-to resource for both simple and complex machinelearning projects.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content