This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This produced a RMSLE CrossValidation of 0.3530. Enabling spatial data in the modeling workflow resulted in a 7.14% RMSLE CrossValidation improvement from the baseline and a $12,000 increase in prediction price compared to the true price, roughly $9,000 lower than the baseline model. Download Now. White Paper.
2nd Place ($1500): Goblin This report is available for download via: [link] Prediction dataset: [link] Goblin’s report differentiated from others off the bat by immediately identifying missing values in the dataset provided for this challenge.
This example uses the Python client to identify and download imagery needed for the analysis. Model training After the data has been downloaded with the Planet Python client, the segmentation model can be trained. The classifier is then trained using the prepared datasets and the tuned number of neighbor parameters.
ETH/USDT prices data can be downloaded from several places , but in this tutorial we’ll use Binance API for a simple solution to getting hourly ETH/USDT prices. CrossValidation Testing One way to significantly improve our ML model’s accuracy is by using crossvalidation. How does crossvalidation work?
Inside the managed training job in the SageMaker environment, the training job first downloads the mouse genome using the S3 URI supplied by HealthOmics. In the sample Jupyter notebook we show how to download FASTA files from GenBank, convert them into FASTQ files, and then load them into a HealthOmics sequence store.
Additionally, I will use StratifiedKFold cross-validation to perform multiple train-test splits. For instance, if working with teams then one could download the different versions of the model from that central point. Model Extraction and Registration For the first version, I want to fit a KNeighborsClassifier to fit the data.
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 4 If you went through our previous blog post on Gradient Boosting, it should be fairly easy for you to grasp XGBoost, as XGBoost is heavily based on the original Gradient Boosting algorithm. kaggle/kaggle.json # download the required dataset from kaggle !kaggle
Data Set : Access to the dataset of historical METAR data points is available to download from the Ocean Market via the Mumbai Test Network (Polygon Testnet), and via Polygon Mainnet. You can download the dataset directly through Desights. It’s also a good practice to perform cross-validation to assess the robustness of your model.
Additionally, anyone with access to the workspace can download the models and begin utilizing them as it has already been uploaded to the registry. We can see our first and second models and their version names. On the far right, we have their source experiments that appear on the Project page.
In this article, we will cover the third & fourth sections i.e. Data Extraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. I have used this documentation for hyperparameter tuning.
Use a representative and diverse validation dataset to ensure that the model is not overfitting to the training data. The UI can include interactive visualizations or allow users to download the output in different formats. This can include user manuals, FAQs, and chatbots for real-time assistance.
This final estimator’s training process often uses cross-validation. We also implement a k-fold crossvalidation function. format(model_location)) In summary, you should notice that in this procedure we downloaded the data one time and trained two models using a single training job.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



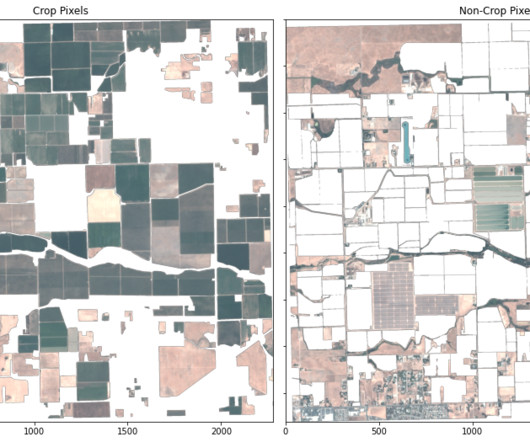















Let's personalize your content