This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. What are KNearestNeighbors in Machine Learning? Definition of KNN Algorithm KNearestNeighbors (KNN) is a simple yet powerful machine learning algorithm for classification and regression tasks.
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. This method takes a parameter, which we set to 3.
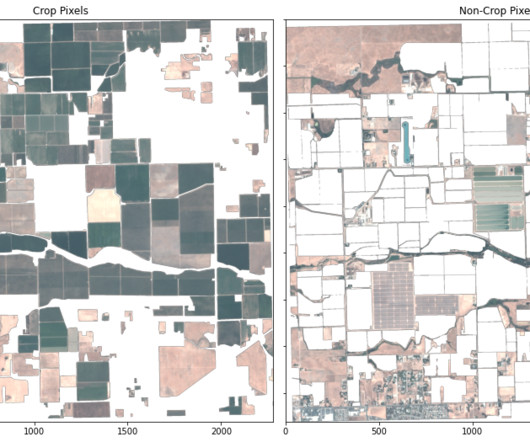
In this analysis, we use a K-nearestneighbors (KNN) model to conduct crop segmentation, and we compare these results with ground truth imagery on an agricultural region. Access Planet data To help users get accurate and actionable data faster, Planet has also developed the Planet Software Development Kit (SDK) for Python.
Cross-Validation: A model evaluation technique that assesses how well a model will generalise to an independent dataset. Joblib: A Python library used for lightweight pipelining in Python, handy for saving and loading large data structures.
K-NearestNeighbors), while others can handle large datasets efficiently (e.g., Cross-Validation: Instead of using a single train-test split, cross-validation involves dividing the data into multiple folds and training the model on each fold. Some algorithms work better with small datasets (e.g.,
The K-NearestNeighbor Algorithm is a good example of an algorithm with low bias and high variance. This trade-off can easily be reversed by increasing the k value which in turn results in increasing the number of neighbours. It provides C++ as well as Python APIs which makes it very easier to work on.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content