This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post K-Fold CrossValidation Technique and its Essentials appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Image designed by the author Introduction Guys! Before getting started, just […].
Modern businesses are embracing machine learning (ML) models to gain a competitive edge. Deploying ML models in their day-to-day processes allows businesses to adopt and integrate AI-powered solutions into their businesses. This reiterates the increasing role of AI in modern businesses and consequently the need for ML models.
Data scientists use a technique called crossvalidation to help estimate the performance of a model as well as prevent the model from… Continue reading on MLearning.ai »
ML models have grown significantly in recent years, and businesses increasingly rely on them to automate and optimize their operations. However, managing ML models can be challenging, especially as models become more complex and require more resources to train and deploy. What is MLOps?
How we do this is the subject of the concept of cross-validation. With cross-validation methods, I will actually change this selection and division procedure dynamically and try to utilize all the data I have. Diagram of k-fold cross-validation. Cross-validation is not actually (just) a validation process.
With advanced analytics derived from machine learning (ML), the NFL is creating new ways to quantify football, and to provide fans with the tools needed to increase their knowledge of the games within the game of football. We then explain the details of the ML methodology and model training procedures.
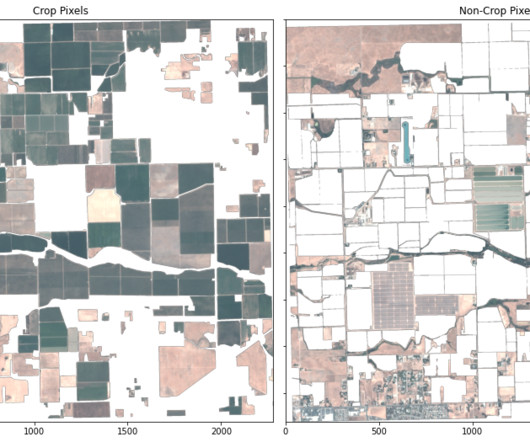
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
Amazon SageMaker Pipelines includes features that allow you to streamline and automate machine learning (ML) workflows. Ensemble models are becoming popular within the ML communities. Pipelines can quickly be used to create and end-to-end ML pipeline for ensemble models.
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. This method takes a parameter, which we set to 3.
Indeed, the most robust predictive trading algorithms use machine learning (ML) techniques. On the optimistic side, algorithmically trading assets with predictive ML models can yield enormous gains à la Renaissance Technologies… Yet algorithmic trading gone awry can yield enormous losses as in the latest FTX scandal. Pretty cool, no?
Introduction One of the most widely used and highly popular programming languages in the technological world is Python. Significantly, despite being user-friendly and easy to learn, one of Python’s many advantages is that it has large collection of libraries. What is a Python Library? What version of Python are you using?
Comet ML has an intricate web of tools that combine simplicity and safety and allows one to not only track changes in their model but also deploy them as desired or shared in teams. Workflow Overview The typical iterative ML workflow involves preprocessing a dataset and then developing the model further. Big teams rely on big ideas.
Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. The global Machine Learning market was valued at USD 35.80
For information about how you can manage and process your own unstructured data, see Unstructured data management and governance using AWS AI/ML and analytics services. Visier has written a full tutorial about how to use Visier Data in Amazon SageMaker and have also built a Python connector available on their GitHub repo.
Perceptron Implementation in Python: Understanding the Basics of Artificial Neural Networks Photo by Jeremy Perkins on Unsplash Perceptron is the most basic unit of an artificial neural network. Python Let’s code a perceptron in Python. It takes several inputs and outputs a single binary decision. A Perceptron.
Please refer to Part 1– to understand what is Sales Prediction/Forecasting, the Basic concepts of Time series modeling, and EDA I’m working on Part 3 where I will be implementing Deep Learning and Part 4 where I will be implementing a supervised ML model.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Data Extraction, Preprocessing & EDA : Extract & Pre-process the data using Python and perform basic Exploratory Data Analysis.
And we at deployr , worked alongside them to find the best possible answers for everyone involved and build their Data and ML Pipelines. Building data and ML pipelines: from the ground to the cloud It was the beginning of 2022, and things were looking bright after the lockdown’s end. With that out of the way, let’s dig in!
Figure 1: Brute Force Search It is a cross-validation technique. Figure 2: K-fold CrossValidation On the one hand, it is quite simple. Running a cross-validation model of k = 10 requires you to run 10 separate models. 2019) Data Science with Python. 2019) Applied Supervised Learning with Python.
Challenge Overview Objective : Building upon the insights gained from Exploratory Data Analysis (EDA), participants in this data science competition will venture into hands-on, real-world artificial intelligence (AI) & machine learning (ML). It’s also a good practice to perform cross-validation to assess the robustness of your model.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, data preparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. What is MLOps?
Experimentation and cross-validation help determine the dataset’s optimal ‘K’ value. Following this step-by-step guide, you can effectively implement the KNN algorithm in Python or any other suitable language. Distance Metrics Distance metrics measure the similarity between data points in a dataset.
Python Implementation We can use DBSCAN class from sklearn. Image by the author. DBSCAN works sequentially, so it’s important to note that non-core points will be assigned to the first cluster that meets the requirement of closeness. Before implementing any model, Let’s get to know the DBSCAN class better.
MNIST examples Experiment on MNIST Figure 3 shows the 2D CNN architecture that was trained and validated using 10-fold cross-validation on the MNIST dataset. The answer is … almost , and I will show you this in an experiment on the well-known MNIST dataset (Figure 2 shows examples from the MNIST dataset).
Let us first understand the meaning of bias and variance in detail: Bias: It is a kind of error in a machine learning model when an ML Algorithm is oversimplified. It is introduced into an ML Model when an ML algorithm is made highly complex. In such types of questions, we first need to ask what ML model we have to train.
For example, if you are using regularization such as L2 regularization or dropout with your deep learning model that performs well on your hold-out-cross-validation set, then increasing the model size won’t hurt performance, it will stay the same or improve. The only drawback of using a bigger model is computational cost.
Integration of Comet: Unleashing the Power of Experiment Management and Performance Tracking We need to install and set Comet up to get started with the library in our Python environment. Each user has assigned a rating from 1 to 5 to different items based on their preferences. We pay our contributors, and we don't sell ads.
Enter PyCaret, an open-source, Python-based machine-learning library that embraces a low-code paradigm, ingeniously devised to streamline the intricate process of model development and deployment. Its unparalleled accessibility caters to a diverse user base ranging from novices to seasoned experts.
Data Science Project — Predictive Modeling on Biological Data Part III — A step-by-step guide on how to design a ML modeling pipeline with scikit-learn Functions. Many ML optimizing functions assume that data has variance in the same order that means it is centered around 0. This cross-validation results shows without regularization.
The platform accomplishes this by using a combination of no-code visual tools, for your code-averse analysts, and code-first options, for your seasoned ML practitioners. In this blog, we will cover what plugins are, why they are useful, and an example of how to develop one using the NeuralProphet Python package and Snowflake Data Cloud.
The platform accomplishes this by using a combination of no-code visual tools, for your code-averse analysts, and code-first options, for your seasoned ML practitioners. In this blog, we will cover what plugins are, why they are useful, and an example of how to develop one using the NeuralProphet Python package and Snowflake Data Cloud.
For our Python example, we’ll use the famous Iris dataset from scikit-learn, which includes measurements of iris flowers and their species. Solution : Implement pruning techniques to limit the depth of the tree, and use cross-validation to ensure the model generalizes well to unseen data.
In particular, my code is based on rospy, which, as you might guess, is a python package allowing you to write code to interact with ROS. The test runs a 5-fold cross-validation. More broadly, I think switching from python to C++ could make a huge difference. We are in the nearby of 0.9
This is often done using techniques such as cross-validation or grid search. Hyperbolic kernel: The hyperbolic kernel is used for non-linear regression problems and is similar to the Gaussian and Laplacian kernels. It is particularly useful for datasets with complex patterns.
The ML process is cyclical — find a workflow that matches. Check out our expert solutions for overcoming common ML team problems. Use a representative and diverse validation dataset to ensure that the model is not overfitting to the training data. We pay our contributors, and we don’t sell ads.
Complete ML model training pipeline workflow | Source But before we delve into the step-by-step model training pipeline, it’s essential to understand the basics, architecture, motivations, challenges associated with ML pipelines, and a few tools that you will need to work with. It makes the training iterations fast and trustable.
As AI has evolved, we have seen different types of machine learning (ML) models emerge. This final estimator’s training process often uses cross-validation. This way, you don’t need to manage your own Docker image repository and it provides more flexibility to running training scripts that need additional Python packages.
It allows us to search through different hyperparameter combinations using cross-validation. Hyperparameter Tuning with GridSearchCV: To optimize the Random Forest model, GridSearchCV can be utilized. The chosen configuration can yield higher accuracy and better generalization.
Decision Tree Model Pipeline In the decision tree model, grid search cross-validation was utilized to determine the optimal parameters. The front-end of the application is built using Streamlit , a Python library that allows developers to create attractive user interfaces with ease.
Normalized age distribution in training and test set [3] The model was implemented in Python and stored in a public GitHub repository (containing source code and the trained models). The use of Jupyter Notebooks was done in order to make it possible to train and validate the models on Google Colab in order to get access to free GPUs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content