This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Top 7 Cross-Validation Techniques with Python Code appeared first on Analytics Vidhya. In the model-building phase of any supervised machine learning project, we train a model with the aim to learn the optimal values for all the weights and biases from labeled examples.
ArticleVideo Book This article was published as a part of the Data Science Blogathon I started learning machine learning recently and I think cross-validation is. The post “I GOT YOUR BACK” – Crossvalidation to Models. appeared first on Analytics Vidhya.
The post K-Fold CrossValidation Technique and its Essentials appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Image designed by the author Introduction Guys! Before getting started, just […].
Real-world applications of CatBoost in predicting student engagement By the end of this story, you’ll discover the power of CatBoost, both with and without cross-validation, and how it can empower educational platforms to optimize resources and deliver personalized experiences. Key Advantages of CatBoost How CatBoost Works?
The post 4 Ways to Evaluate your Machine Learning Model: Cross-Validation Techniques (with Python code) appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Whenever we build any machine learning model, we feed it.
The post Importance of CrossValidation: Are Evaluation Metrics enough? ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Model Building in Machine Learning is an important component of. appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon In this article, we will be learning about how to apply k-fold cross-validation to a deep learning image classification model. Like my other articles, this article is going to have hands-on experience with code.
Overview Evaluating a model is a core part of building an effective machine learning model There are several evaluation metrics, like confusion matrix, cross-validation, The post 11 Important Model Evaluation Metrics for Machine Learning Everyone should know appeared first on Analytics Vidhya.
Learn how to use a simple random search in Python to get good results in less time. Feature selection is one of the most important tasks in machine learning.
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Introduction In this article, we will explore the concept of cross-validation in Machine Learning, a crucial technique for assessing model performance and generalisation. billion by 2029.
Data scientists use a technique called crossvalidation to help estimate the performance of a model as well as prevent the model from… Continue reading on MLearning.ai »
Validating its performance on unseen data is crucial. Python offers various tools like train-test split and cross-validation to assess model generalizability. By validating models, data scientists can assess their effectiveness, identify areas for improvement, and make informed decisions about model deployment.
How we do this is the subject of the concept of cross-validation. With cross-validation methods, I will actually change this selection and division procedure dynamically and try to utilize all the data I have. Diagram of k-fold cross-validation. Cross-validation is not actually (just) a validation process.
The torchvision package includes datasets and transformations for testing and validating computer vision models. Scikit-learn Scikit-learn is a versatile Python library that offers various algorithms and model evaluation metrics, including cross-validation and grid search for hyperparameter tuning.
Cross-validation: This technique involves splitting the data into multiple folds and training the model on different folds to evaluate its performance on unseen data. Python Explain the steps involved in training a decision tree. This happens when the model is too simple to capture the underlying patterns in the data.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learning algorithms. Acquiring proficiency in Python has become essential for individuals aiming to excel in these domains. Why do you need Python machine learning packages?
Introduction One of the most widely used and highly popular programming languages in the technological world is Python. Significantly, despite being user-friendly and easy to learn, one of Python’s many advantages is that it has large collection of libraries. What is a Python Library? What version of Python are you using?
GluonTS is a Python package for probabilistic time series modeling, but the SBP distribution is not specific to time series, and we were able to repurpose it for regression. Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. We used the SBP distribution provided by GluonTS.
Prophet is implemented in Python, a widely used programming language for machine learning and artificial intelligence. We’ll install with pip here for ease of use with Python: $ python -m pip install prophet That’s it! In your terminal, start the Python console. Pretty cool, no? It’s also open-source!
Perceptron Implementation in Python: Understanding the Basics of Artificial Neural Networks Photo by Jeremy Perkins on Unsplash Perceptron is the most basic unit of an artificial neural network. Python Let’s code a perceptron in Python. It takes several inputs and outputs a single binary decision. A Perceptron.
The Amazon SageMaker Studio notebook with geospatial image comes pre-installed with commonly used geospatial libraries such as GDAL, Fiona, GeoPandas, Shapely, and Rasterio, which allow the visualization and processing of geospatial data directly within a Python notebook environment.
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. This method takes a parameter, which we set to 3.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Data Extraction, Preprocessing & EDA : Extract & Pre-process the data using Python and perform basic Exploratory Data Analysis.
Figure 1: Brute Force Search It is a cross-validation technique. Figure 2: K-fold CrossValidation On the one hand, it is quite simple. Running a cross-validation model of k = 10 requires you to run 10 separate models. 2019) Data Science with Python. 2019) Applied Supervised Learning with Python.
Use cross-validation and regularisation to prevent overfitting and pick an appropriate polynomial degree. You can detect and mitigate overfitting by using cross-validation, regularisation, or carefully limiting polynomial degrees. It offers flexibility for capturing complex trends while remaining interpretable.
They are: A Comet ML account A suitable IDE, e.g., VSCode or Jupyter Notebook which can also run in VSCode The latest versions of Scikit-learn, CometML, Pandas, NumPy, joblib, and XGboost libraries A python 3.9+ Additionally, I will use StratifiedKFold cross-validation to perform multiple train-test splits.
Using Accuracy Score in Python In Python, we can calculate accuracy using the accuracy_score function from the sklearn.metrics module. By employing techniques such as cross-validation, metrics like precision and recall, and visualizations like ROC curves, you can comprehensively evaluate your model’s performance.
Use the following methods- Validate/compare the predictions of your model against actual data Compare the results of your model with a simple moving average Use k-fold cross-validation to test the generalized accuracy of your model Use rolling windows to test how well the model performs on the data that is one step or several steps ahead of the current (..)
Visier has written a full tutorial about how to use Visier Data in Amazon SageMaker and have also built a Python connector available on their GitHub repo. The Python connector allows customers to pipe Visier data to their own AI/ML projects to better understand the impact of their people on financials, operations, customers and partners.
Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. Key Takeaways Strong programming skills in Python and R are vital for Machine Learning Engineers. According to Emergen Research, the global Python market is set to reach USD 100.6
MLOps practices include cross-validation, training pipeline management, and continuous integration to automatically test and validate model updates. Examples include: Cross-validation techniques for better model evaluation. Managing training pipelines and workflows for a more efficient and streamlined process.
Here are some key areas often assessed: Programming Proficiency Candidates are often tested on their proficiency in languages such as Python, R, and SQL, with a focus on data manipulation, analysis, and visualization. What is cross-validation, and why is it used in Machine Learning?
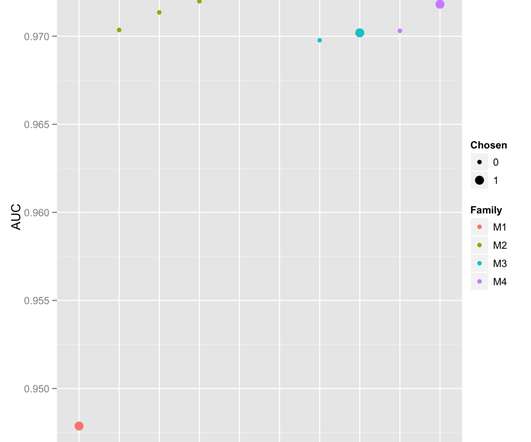
latex lambda$ controls the penalty from the regularizing function, and is chosen using crossvalidation. The number of latent factors, K, is chosen by crossvalidation. I develop the classification training programs for Model 2, 3, and 4 in Python. Model 1: Baseline. Model 1 is example_model_2.R
This allows scientists and model developers to focus on model development and rapid experimentation rather than infrastructure management Pipelines offers the ability to orchestrate complex ML workflows with a simple Python SDK with the ability to visualize those workflows through SageMaker Studio. tag = "latest" container_image_uri = "{0}.dkr.ecr.{1}.amazonaws.com/{2}:{3}".format(account_id,
Experimentation and cross-validation help determine the dataset’s optimal ‘K’ value. Following this step-by-step guide, you can effectively implement the KNN algorithm in Python or any other suitable language. Distance Metrics Distance metrics measure the similarity between data points in a dataset.
Data Scientists use a wide range of tools and programming languages such as Python and R to extract meaningful patterns and trends from data. Proficiency in programming languages like Python and R is essential for data manipulation, analysis, and visualization. Machine Learning Machine learning is at the heart of Data Science.
Python Implementation We can use DBSCAN class from sklearn. Image by the author. DBSCAN works sequentially, so it’s important to note that non-core points will be assigned to the first cluster that meets the requirement of closeness. Before implementing any model, Let’s get to know the DBSCAN class better.
Some ideas for Python native ML to include ARIMA/SARIMA using 'statsmodels',LSTM(Long Short-Term Memory) Networks using TensorFlow or Keras,Random Forest Regression using scikit-learn, or Gradient Boosting Machines using XGBoost. It’s also a good practice to perform cross-validation to assess the robustness of your model.
MNIST examples Experiment on MNIST Figure 3 shows the 2D CNN architecture that was trained and validated using 10-fold cross-validation on the MNIST dataset. The answer is … almost , and I will show you this in an experiment on the well-known MNIST dataset (Figure 2 shows examples from the MNIST dataset).
For example, if you are using regularization such as L2 regularization or dropout with your deep learning model that performs well on your hold-out-cross-validation set, then increasing the model size won’t hurt performance, it will stay the same or improve. The only drawback of using a bigger model is computational cost.
Implementing Boosting in Python is easy with Scikit-learn and XGBoost, ensuring efficient model optimisation. Here is the table showing the difference between Boosting and Stacking for your better understanding: Implementing Boosting in PythonPython makes it easy to implement Boosting using popular libraries like Scikit-learn and XGBoost.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content