This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This means that you can use natural language prompts to perform advanced dataanalysis tasks, generate visualizations, and train machine learning models without the need for complex coding knowledge. With Code Interpreter, you can perform tasks such as dataanalysis, visualization, coding, math, and more.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
The development of a Machine Learning Model can be divided into three main stages: Building your ML datapipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. Cleaning data: Once the data has been gathered, it needs to be cleaned.
It involves data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and correlations that can drive decision-making. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on dataanalysis and interpretation to extract meaningful insights.
There are many well-known libraries and platforms for dataanalysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. These tools will help make your initial data exploration process easy. You can watch it on demand here.
Exploring the Ocean If Big Data is the ocean, Data Science is the multifaceted discipline of extracting knowledge and insights from data, whether it’s big or small. It’s an interdisciplinary field that blends statistics, computer science, and domain expertise to understand phenomena through dataanalysis.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
I have checked the AWS S3 bucket and Snowflake tables for a couple of days and the Datapipeline is working as expected. The scope of this article is quite big, we will exercise the core steps of data science, let's get started… Project Layout Here are the high-level steps for this project. The data is in good shape.
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Because of this, I’m always looking for ways to automate and improve our datapipelines. So why should we use datapipelines?
This includes important stages such as feature engineering, model development, datapipeline construction, and data deployment. For instance, feature engineering and exploratorydataanalysis (EDA) often require the use of visualization libraries like Matplotlib and Seaborn.
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Because of this, I’m always looking for ways to automate and improve our datapipelines. So why should we use datapipelines?
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Because of this, I’m always looking for ways to automate and improve our datapipelines. So why should we use datapipelines?
Cleaning and preparing the data Raw data typically shouldn’t be used in machine learning models as it’ll throw off the prediction. This can be achieved by, you guessed it, analyzing the data. What if you could know what drives them to buy your products and could use that to bring in more customers like them?
GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do dataanalysis BI report generation/dataanalysis In BI/dataanalysis world, people usually need to query data (small/large).
Ingest your data and DataRobot will use all these data points to train a model—and once it is deployed, your marketing team will be able to get a prediction to know if a customer is likely to redeem a coupon or not and why. All of this can be integrated with your marketing automation application of choice.
The Microsoft Certified: Azure Data Scientist Associate certification is highly recommended, as it focuses on the specific tools and techniques used within Azure. Additionally, enrolling in courses that cover Machine Learning, AI, and DataAnalysis on Azure will further strengthen your expertise.
This is achieved by using the pipeline to transfer data from a Splunk index into an S3 bucket, where it will be cataloged. The approach is shown in the following diagram. This gives you full visibility into how the results are being returned.
Making Data Stationary: Many forecasting models assume stationarity. If the data is non-stationary, apply transformations like differencing or logarithmic scaling to stabilize its statistical properties. ExploratoryDataAnalysis (EDA): Conduct EDA to identify trends, seasonal patterns, and correlations within the dataset.
The reason is that most teams do not have access to a robust data ecosystem for ML development. billion is lost by Fortune 500 companies because of broken datapipelines and communications. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
The reason is that most teams do not have access to a robust data ecosystem for ML development. billion is lost by Fortune 500 companies because of broken datapipelines and communications. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
Simply put, focusing solely on dataanalysis, coding or modeling will no longer cuts it for most corporate jobs. My personal opinion: its more important than ever to be an end-to-end data scientist. You have to understand data, how to extract value from them and how to monitor model performances. What to do then?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















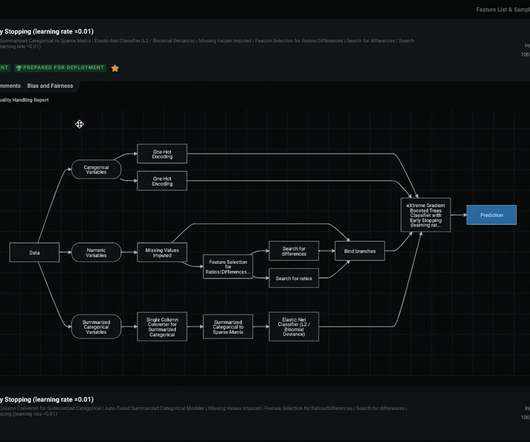












Let's personalize your content