This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A major advantage of the STAR […] The post How to Optimize DataWarehouse with STAR Schema? This star-like structure simplifies complex queries, enhances performance, and is ideal for large datasets requiring fast retrieval and simplified joins. appeared first on Analytics Vidhya.
This is where data warehousing is a critical component of any business, allowing companies to store and manage vast amounts of data. It provides the necessary foundation for businesses to […] The post Understanding the Basics of DataWarehouse and its Structure appeared first on Analytics Vidhya.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business? Let’s take a closer look.
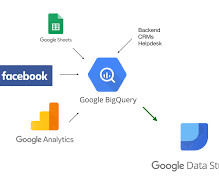
Introduction Google Big Query is a secure, accessible, fully-manage, pay-as-you-go, server-less, multi-cloud datawarehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to generate useful insights from big data that will help business stakeholders in effective decision-making.
Summary: Online Analytical Processing (OLAP) systems in DataWarehouse enable complex DataAnalysis by organizing information into multidimensional structures. Key characteristics include fast query performance, interactive analysis, hierarchical data organization, and support for multiple users.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Organisations must store data in a safe and secure place for which Databases and Datawarehouses are essential. You must be familiar with the terms, but Database and DataWarehouse have some significant differences while being equally crucial for businesses. What is DataWarehouse?
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Dataanalysis, dataset preparation, interactive visualizations, and more may all be accomplished in SQL Server with the help of Python or R. Different datawarehouses are designed differently, and data architects and engineers make different decisions about to lay out the data for the best performance.
Summary: A DataWarehouse consolidates enterprise-wide data for analytics, while a Data Mart focuses on department-specific needs. DataWarehouses offer comprehensive insights but require more resources, whereas Data Marts provide cost-effective, faster access to focused data.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
The data mining process The data mining process is structured into four primary stages: data gathering, data preparation, data mining, and dataanalysis and interpretation. Each stage is crucial for deriving meaningful insights from data.
It also helps in providing visibility to data and thus enables the users to make informed decisions. Data management software helps in the creation of reports and presentations by automating the process of data collection, data extraction, data cleansing, and dataanalysis.
Big data analytics advantages. Google BigQuery is a service (within the Google Cloud platform (GCP)) implemented to collect and analyze big data (also known as a datawarehouse). If you’re looking for a cost-effective, diverse and easily usable datawarehouse, Google BigQuery may be the way to go.
A point of data entry in a given pipeline. Examples of an origin include storage systems like data lakes, datawarehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
Five Best Practices for Data Analytics. Extracted data must be saved someplace. There are several choices to consider, each with its own set of advantages and disadvantages: Datawarehouses are used to store data that has been processed for a specific function from one or more sources. Select a Storage Platform.
Open source business intelligence software is a game-changer in the world of dataanalysis and decision-making. It has revolutionized the way businesses approach data analytics by providing cost-effective and customizable solutions that are tailored to specific business needs.
There are many well-known libraries and platforms for dataanalysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. These tools will help make your initial data exploration process easy.
We decided to cover some of the most important differences between Data Mining vs Data Science in order to finally understand which is which. What is Data Science? Data Science is an activity that focuses on dataanalysis and finding the best solutions based on it. It hosts a dataanalysis competition.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services.
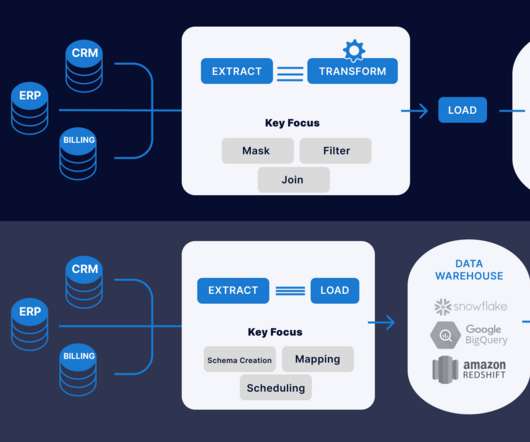
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
ETL is a three-step process that involves extracting data from various sources, transforming it into a consistent format, and loading it into a target database or datawarehouse. Extract The extraction phase involves retrieving data from diverse sources such as databases, spreadsheets, APIs, or other systems.
This article was published as a part of the Data Science Blogathon. Introduction A key aspect of big data is data frames. However, Spark is more suited to handling scaled distributed data, whereas Pandas is not. Pandas and Spark are two of the most popular types. What […].
By automating the integration of all Fabric workloads into OneLake, Microsoft eliminates the need for developers, analysts, and business users to create their own data silos. This approach not only improves performance by eliminating the need for separate datawarehouses but also results in substantial cost savings for customers.
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
From this application, below are some benefits of stream processing: Provides a path for more dataanalysis. Accelerates data delivery to give way to real-time analytics. It’s also a method of constant processing that takes place when big data is streaming into the system.
It is a crucial data integration process that involves moving data from multiple sources into a destination system, typically a datawarehouse. This process enables organisations to consolidate their data for analysis and reporting, facilitating better decision-making.
Introduction Publish and Subscribe is a messaging mechanism having one or a set of senders sending messages and one or a group of receivers receiving these messages.
Are you a data enthusiast looking to break into the world of analytics? The field of data science and analytics is booming, with exciting career opportunities for those with the right skills and expertise. So, let’s […] The post Data Scientist vs Data Analyst: Which is a Better Career Option to Pursue in 2023?
Online analytical processing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance dataanalysis and decision-making when used in tandem. Today, OLAP database systems have become comprehensive and integrated data analytics platforms, addressing the diverse needs of modern businesses.
Some solutions provide read and write access to any type of source and information, advanced integration, security capabilities and metadata management that help achieve virtual and high-performance Data Services in real-time, cache or batch mode. How does Data Virtualization complement Data Warehousing and SOA Architectures?
Introduction Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers.
To democratize data, organizations can identify data sources and create a centralized data repository This might involve creating user-friendly data visualization tools, offering training on dataanalysis and visualization, or creating data portals that allow users to easily access and download data.
Introduction In today’s data-driven world, the role of data scientists has become indispensable. in data science to unravel the mysteries hidden within vast data sets? But what if I told you that you don’t need a Ph.D.
This allows data that exists in cloud object storage to be easily combined with existing datawarehousedata without data movement. The advantage to NPS clients is that they can store infrequently used data in a cost-effective manner without having to move that data into a physical datawarehouse table.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. If it’s not done right away, then later.
She helps organizations convert data into value, developing data strategies and automating processes. A believer in sharing knowledge, Anya helps people develop their data skills by introducing dataanalysis and visualization tools into their everyday workflows, conducting training, writing manuals, and presenting at events.
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
They all agree that a Datamart is a subject-oriented subset of a datawarehouse focusing on a particular business unit, department, subject area, or business functionality. The Datamart’s data is usually stored in databases containing a moving frame required for dataanalysis, not the full history of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content