This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
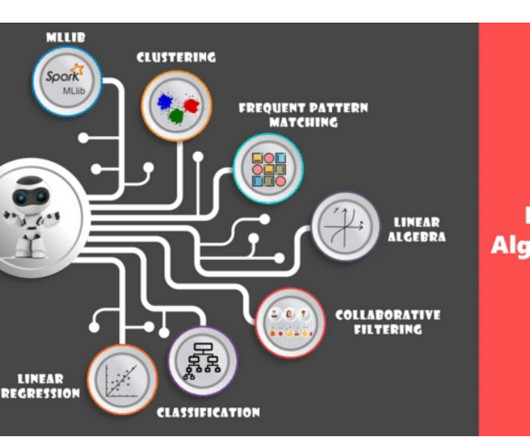
Pyspark MLlib | Classification using Pyspark ML In the previous sections, we discussed about RDD, Dataframes, and Pyspark concepts. In this article, we will discuss about Pyspark MLlib and Spark ML. Pyspark MLlib is a wrapper over PySpark Core to do dataanalysis using machine-learning algorithms.
The course covers topics such as linear regression, logistic regression, and decisiontrees. Gain expertise in dataanalysis, deep learning, neural networks, and more. Each course is carefully crafted and delivered by world-renowned experts, covering everything from the fundamentals to advanced techniques.
These tools enable dataanalysis, model building, and algorithm optimization, forming the backbone of ML applications. Introduction Machine Learning (ML) often seems like magic. Feed data into an algorithm, and out comes predictions, classifications, or insights that seem almost intuitive.
Exploratory DataAnalysis(EDA)on Biological Data: A Hands-On Guide Unraveling the Structural Data of Proteins, Part II — Exploratory DataAnalysis Photo from Pexels In a previous post, I covered the background of this protein structure resolution data set, including an explanation of key data terminology and details on how to acquire the data.
As we navigate this landscape, the interconnected world of Data Science, Machine Learning, and AI defines the era of 2024, emphasising the importance of these fields in shaping the future. ’ As we navigate the expansive tech landscape of 2024, understanding the nuances between Data Science vs Machine Learning vs ai.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Given the volume of SaaS apps on the market (more than 30,000 SaaS developers were operating in 2023) and the volume of data a single app can generate (with each enterprise businesses using roughly 470 SaaS apps), SaaS leaves businesses with loads of structured and unstructured data to parse. What are application analytics?
How to Scale Your Data Quality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
By scrutinizing data packets that constitute network traffic, NTA aims to establish baselines of normal behavior, detect deviations, and take appropriate actions. This is where the power of machine learning (ML) comes into play. One of the primary applications of ML in network traffic analysis is anomaly detection.
Machine learning (ML) has proven that it is here with us for the long haul, everyone who had their doubts by calling it a phase should by now realize how wrong they are, ML has being used in various sector’s of society such as medicine, geospatial data, finance, statistics and robotics.
Data Science Project — Predictive Modeling on Biological Data Part III — A step-by-step guide on how to design a ML modeling pipeline with scikit-learn Functions. Photo by Unsplash Earlier we saw how to collect the data and how to perform exploratory dataanalysis. Now comes the exciting part ….
Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification. Certainly, these predictions and classification help in uncovering valuable insights in data mining projects. Consequently, each brand of the decisiontree will yield a distinct result.
Here are some ways AI enhances IoT devices: Advanced dataanalysis AI algorithms can process and analyze vast volumes of IoT-generated data. By leveraging techniques like machine learning and deep learning, IoT devices can identify trends, anomalies, and patterns within the data.
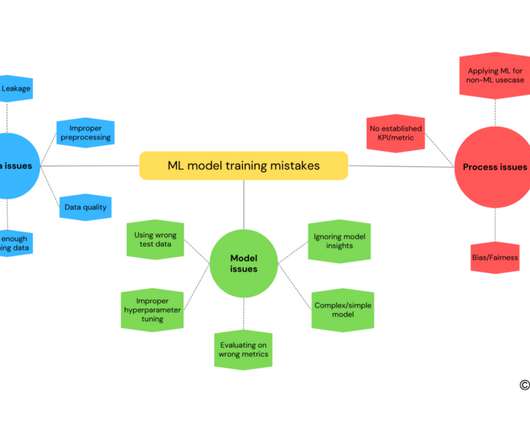
Mind Map: Mistakes in ML model training This blog highlights some important mistakes that one can make while training a machine learning model. Machine Learning model training is the process of teaching a model how to recognize patterns in data. What can go wrong in ML model training?
Businesses must understand how to implement AI in their analysis to reap the full benefits of this technology. In the following sections, we will explore how AI shapes the world of financial dataanalysis and address potential challenges and solutions.
Big DataAnalysis with PySpark Bharti Motwani | Associate Professor | University of Maryland, USA Ideal for business analysts, this session will provide practical examples of how to use PySpark to solve business problems. Finally, you’ll discuss a stack that offers an improved UX that frees up time for tasks that matter.
ML works with structured data, while DL processes complex, unstructured data. ML requires less computing power, whereas DL excels with large datasets. Introduction In todays world of AI, both Machine Learning (ML) and Deep Learning (DL) are transforming industries, yet many confuse the two.
Accordingly, Machine Learning allows computers to learn and act like humans by providing data. Apparently, ML algorithms ensure to train of the data enabling the new data input to make compelling predictions and deliver accurate results. Significantly, Supervised Learning uses offline analysis.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
Scikit-learn: A simple and efficient tool for data mining and dataanalysis, particularly for building and evaluating machine learning models. Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, data preparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. What is MLOps?
Without this library, dataanalysis wouldn’t be the same without pandas, which reign supreme with its powerful data structures and manipulation tools. Pandas provides a fast and efficient way to work with tabular data. It is widely used in data science, finance, and other fields where dataanalysis is essential.
This explosive growth is driven by the increasing volume of data generated daily, with estimates suggesting that by 2025, there will be around 181 zettabytes of data created globally. Understand data structures and explore data warehousing concepts to efficiently manage and retrieve large datasets.
Data science solves a business problem by understanding the problem, knowing the data that’s required, and analyzing the data to help solve the real-world problem. Machine learning (ML) is a subset of artificial intelligence (AI) that focuses on learning from what the data science comes up with.
To address this challenge, data scientists harness the power of machine learning to predict customer churn and develop strategies for customer retention. Continuous Experiment Tracking with Comet ML Comet ML is a versatile tool that helps data scientists optimize machine learning experiments.
METAR, Miami International Airport (KMIA) on March 9, 2024, at 15:00 UTC In the recently concluded data challenge hosted on Desights.ai , participants used exploratory dataanalysis (EDA) and advanced artificial intelligence (AI) techniques to enhance aviation weather forecasting accuracy.
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through Exploratory DataAnalysis , imputation, and outlier handling, robust models are crafted. Hence, it is important to discuss the impact of feature engineering in Machine Learning.
The following Venn diagram depicts the difference between data science and data analytics clearly: 3. Dataanalysis can not be done on a whole volume of data at a time especially when it involves larger datasets. Overfitting: The model performs well only for the sample training data.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and Data Science, highlighting their complementary roles in DataAnalysis and intelligent decision-making. These components solve complex problems and drive decision-making in various industries.
AI encompasses various subfields, including Machine Learning (ML), Natural Language Processing (NLP), robotics, and computer vision. Together, Data Science and AI enable organisations to analyse vast amounts of data efficiently and make informed decisions based on predictive analytics.
Here is the tabular representation of the same: Technical Skills Non-technical Skills Programming Languages: Python, SQL, R Good written and oral communication DataAnalysis: Pandas, Matplotlib, Numpy, Seaborn Ability to work in a team ML Algorithms: Regression Classification, DecisionTrees, Regression Analysis Problem-solving capability Big Data: (..)
Some important things that were considered during these selections were: Random Forest : The ultimate feature importance in a Random forest is the average of all decisiontree feature importance. A random forest is an ensemble classifier that makes predictions using a variety of decisiontrees.
In this blog, we’ll look at how to apply Generative AI on top of predictive ML models to enhance explainability. Using Large Language Models (LLMs) on Snowflake AI Data Cloud , we’ll extract detailed natural-language descriptions to help business associates understand complex quantitative predictions.
On the other hand, 48% use ML and AI for gaining insights into the prospects and customers. An ensemble of decisiontrees is trained on both normal and anomalous data. In 2023, the expected reach of the AI market is supposed to reach the $500 billion mark and in 2030 it is supposed to reach $1,597.1
R is frequently used for statistical software development, dataanalysis, and data visualisation because it can handle large data sets with ease. This programming language offers a variety of methods for model training and evaluation, making it perfect for machine learning projects that need a lot of data processing.
It is also essential to evaluate the quality of the dataset by conducting exploratory dataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text. The ML process is cyclical — find a workflow that matches. Check out our expert solutions for overcoming common ML team problems.
Data Science Project — Build a DecisionTree Model with Healthcare Data Using DecisionTrees to Categorize Adverse Drug Reactions from Mild to Severe Photo by Maksim Goncharenok Decisiontrees are a powerful and popular machine learning technique for classification tasks.
Model Visualization provides insights into the decision-making process of a model, especially for complex models like neural networks. By visually interpreting the performance metrics, it helps in the efficient evaluation of the ML models. For using Comet, you will need the API Key which you need to create on the Comel ML platform.
Heart disease stands as one of the foremost global causes of mortality today, presenting a critical challenge in clinical dataanalysis. Leveraging hybrid machine learning techniques, a field highly effective at processing vast healthcare data volumes is increasingly promising in effective heart disease prediction.
Tabular data is a foundational element in the realm of dataanalysis, serving as the backbone for a variety of machine learning applications. Debate on necessity of deep learning Some experts argue that the local or hierarchical structures leveraged by deep learning may not suit tabular data effectively.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content