

Predicting SONAR Rocks Against Mines with ML
Analytics Vidhya
APRIL 17, 2022
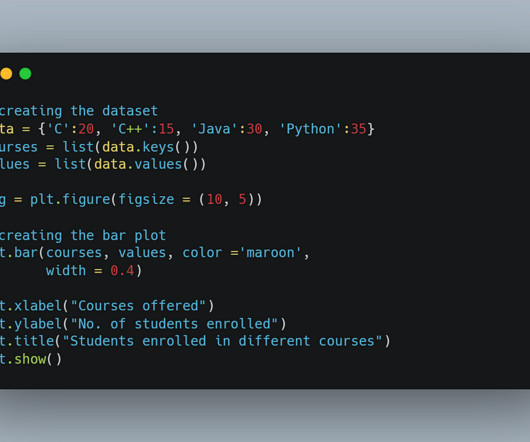
Introduction This article is about predicting SONAR rocks against Mines with the help of Machine Learning. Machine learning-based tactics, and deep learning-based approaches have applications in […]. SONAR is an abbreviated form of Sound Navigation and Ranging. It uses sound waves to detect objects underwater.









































Let's personalize your content