This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Exploratorydataanalysis (EDA) is a critical component of data science that allows analysts to delve into datasets to unearth the underlying patterns and relationships within. EDA serves as a bridge between raw data and actionable insights, making it essential in any data-driven project.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
Models like ChatGPT and LLama can generate text and code, perform exploratorydataanalysis, and automate documentation, which introduces countless opportunities for data science efficiencies. Generative AI (GenAI) has undoubtedly taken the spotlight as this years defining innovation.
For those doing exploratorydataanalysis on tabular data: there is Sketch, a code-writing assistant that seamlessly integrates bits of your dataframes into promptsI’ve made this map using Sketch, Jupyter, Geopandas, and Keplergl For us, data professionals, AI advancements bring new workflows and enhance our toolset.
Explore the role and importance of data normalization You might come across certain matches that have missing data on shot outcomes, or any other metric. Correcting these issues ensures your analysis is based on clean, reliable data.
There are many well-known libraries and platforms for dataanalysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. These tools will help make your initial data exploration process easy.
Summary: Python simplicity, extensive libraries like Pandas and Scikit-learn, and strong community support make it a powerhouse in DataAnalysis. It excels in data cleaning, visualisation, statistical analysis, and Machine Learning, making it a must-know tool for Data Analysts and scientists. Why Python?
This article will guide you through effective strategies to learn Python for Data Science, covering essential resources, libraries, and practical applications to kickstart your journey in this thriving field. Key Takeaways Python’s simplicity makes it ideal for DataAnalysis. in 2022, according to the PYPL Index.
The Use of LLMs: An Attractive Solution for DataAnalysis Not only can LLMs deliver dataanalysis in a user-friendly and conversational format “via the most universal interface: Natural Language,” as Satya Nadella, the CEO of Microsoft, puts it, but also they can adapt and tailor their responses to immediate context and user needs.
Google Releases a tool for Automated ExploratoryDataAnalysis Exploring data is one of the first activities a data scientist performs after getting access to the data. This command-line tool helps to determine the properties and quality of the data as well the predictive power.
Once you have downloaded the dataset, you can upload it to the Watson Studio instance by going to the Assets tab and then dropping the data files as shown below. Add Data You can access the data from the notebook once it has been added to the Watson Studio project. Dataframe head 2.
Overlooking Data Quality The quality of the data you are working on also plays a significant role. Data quality is critical for successful dataanalysis. Working with inaccurate or poor quality data may result in flawed outcomes. Hence, a data scientist needs to have a strong business acumen.
For access to the data used in this benchmark notebook, sign up for the competition here. KG 2 bfaiol.wav nonword_repetition chav KG 3 ktvyww.wav sentence_repetition ring the bell on the desk to get her attention 2 4 htfbnp.wav blending kite KG We'll join these datasets together to help with our exploratorydataanalysis.
With Text AI, we’ve made it easy for you to understand how our DataRobot platform has used your text data and the resulting insights. Watch a demo recording , access documentation , and contact our team to request a demo. It is part of our new 7.3 No additional licenses are needed to use Text AI. Do More with Text AI. Request a Demo.
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites). Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos).
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
Register the Data Wrangler application within the IdP Refer to the following documentation for the IdPs that Data Wrangler supports: Azure AD Okta Ping Federate Use the documentation provided by your IdP to register your Data Wrangler application.
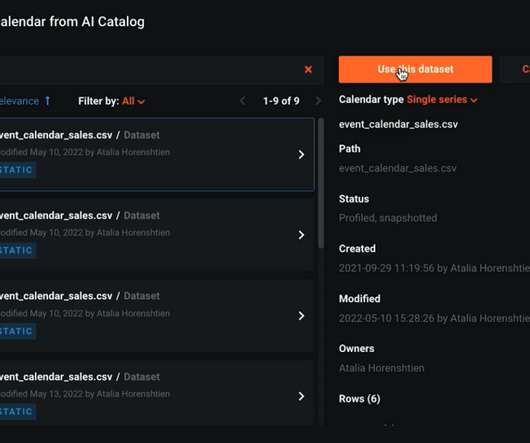
If your dataset is not in time order (time consistency is required for accurate Time Series projects), DataRobot can fix those gaps using the DataRobot Data Prep tool , a no-code tool that will get your data ready for Time Series forecasting. Prepare your data for Time Series Forecasting. Perform exploratorydataanalysis.
Data storage : Store the data in a Snowflake data warehouse by creating a data pipe between AWS and Snowflake. Data Extraction, Preprocessing & EDA : Extract & Pre-process the data using Python and perform basic ExploratoryDataAnalysis. Please refer to this documentation link.
Learn how Data Scientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, dataanalysis, data cleaning, and data visualization. It facilitates exploratoryDataAnalysis and provides quick insights.
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through ExploratoryDataAnalysis , imputation, and outlier handling, robust models are crafted. Text feature extraction Objective: Transforming textual data into numerical representations.
As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. The programming language can handle Big Data and perform effective dataanalysis and statistical modelling. R’s workflow support enhances productivity and collaboration among data scientists.
R for Data Science Although not as broadly adopted as Python, R holds a strong position in Data Science, particularly for statistical analysis, advanced visualisation, and specialised techniques. This workflow is useful when you can utilise Python’s numerical computation capabilities within an R-based analysis pipeline.
Each type employs distinct methodologies for DataAnalysis and decision-making. Key Features No labelled data is required; the model identifies patterns or structures. Typically used for clustering (grouping data into categories) or dimensionality reduction (simplifying data without losing important information).
A typical SDLC has following stages: Stage1: Planning and requirement analysis, defining Requirements Gather requirement from end customer. Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. The data would be interesting to analyze.
Plotly allows developers to embed interactive features such as zooming, panning, and hover effects directly into the plots, making it ideal for ExploratoryDataAnalysis and dynamic reports. Heatmaps also find applications in fields like bioinformatics, where they can visualise gene expression data or signal processing.
At the same time such plant data have very complicated structures and hard to label. And also in my work, have to detect certain values in various formats in very specific documents, in German. Such data are far from general datasets, and even labeling is hard in that case. “Shut up and annotate!”
The Microsoft Certified: Azure Data Scientist Associate certification is highly recommended, as it focuses on the specific tools and techniques used within Azure. Additionally, enrolling in courses that cover Machine Learning, AI, and DataAnalysis on Azure will further strengthen your expertise.
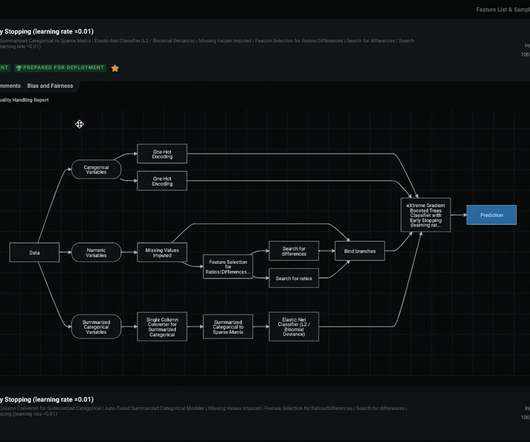
These capabilities take the form of: Exploratorydataanalysis to prepare basic features from raw data. Specialized automated feature engineering and reduction for time series data. DataRobot Feature Lineage allows users to audit the full data lineage in a simple and fully documented graphical representation.
The objective of clustering is to discover hidden relationships, similarities, or patterns in the data without any prior knowledge or guidance. It can be applied to a wide range of domains and has numerous practical applications , such as customer segmentation, image and document categorization, anomaly detection, and social network analysis.
I started my project with a simple data set with historical information of coupons sent to clients and a target variable that captured information about whether the coupon was redeemed or not in the past. The DataRobot model blueprints allow users to rapidly test many different modeling approaches and increase model diversity and accuracy.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline.
Documenting Objectives: Create a comprehensive document outlining the project scope, goals, and success criteria to ensure all parties are aligned. Making Data Stationary: Many forecasting models assume stationarity. accuracy, precision). Visualization tools can help in understanding these aspects better.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
Data Cleaning: Raw data often contains errors, inconsistencies, and missing values. Data cleaning identifies and addresses these issues to ensure data quality and integrity. Data Visualisation: Effective communication of insights is crucial in Data Science.
Here are some notable applications where KNN shines: Classification Tasks Image Recognition: KNN is adept at classifying images into different categories, making it invaluable in applications like facial recognition, object detection, and medical image analysis. Unlock Your Data Science Career with Pickl.AI
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. I’ll show you best practices for using Jupyter Notebooks for exploratorydataanalysis. When data science was sexy , notebooks weren’t a thing yet. documentation.
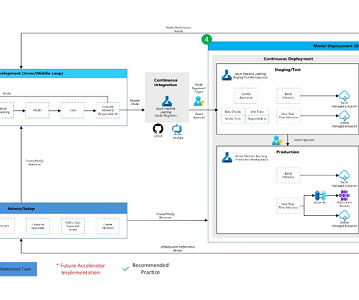
Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow. A typical workflow is illustrated here from data ingestion, EDA (ExploratoryDataAnalysis), experimentation, model development and evaluation, to the registration of a candidate model for production.
You can understand the data and model’s behavior at any time. Once you use a training dataset, and after the ExploratoryDataAnalysis, DataRobot flags any data quality issues and, if significant issues are spotlighted, will automatically handle them in the modeling stage. Rapid Modeling with DataRobot AutoML.
As an example for catalogue data, it’s important to check if the set of mandatory fields like product title, primary image, nutritional values, etc. are present in the data. So, we need to build a verification layer that runs based on a set of rules to verify and validate data before preparing it for model training.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content