This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Table of Contents Introduction Working with dataset Creating loss dataframe Visualizations Analysis from Heatmap Overall Analysis Conclusion Introduction In this article, I am going to perform ExploratoryDataAnalysis on the Sample Superstore dataset.
This means that you can use natural language prompts to perform advanced dataanalysis tasks, generate visualizations, and train machine learning models without the need for complex coding knowledge. With Code Interpreter, you can perform tasks such as dataanalysis, visualization, coding, math, and more.
Performing exploratorydataanalysis to gain insights into the dataset’s structure. Whether you’re a data scientist aiming to deepen your expertise in NLP or a machine learning engineer interested in domain-specific model fine-tuning, this tutorial will equip you with the tools and insights you need to get started.
In the increasingly competitive world, understanding the data and taking quicker actions based on that help create differentiation for the organization to stay ahead! It is used to discover trends [2], patterns, relationships, and anomalies in data, and can help inform the development of more complex models [3].
Introduction to Modern Statistics by Mine Cetinkaya-Rundel and Johanna Hardin is a free-to-download book: Introduction to Modern Statistics is a re-imagining of a previous title, Introduction to Statistics with Randomization and Simulation book.
ExploratoryDataAnalysis on Stock Market Data Photo by Lukas Blazek on Unsplash ExploratoryDataAnalysis (EDA) is a crucial step in data science projects. It helps in understanding the underlying patterns and relationships in the data. The dataset can be downloaded from Kaggle.
Through each exercise, you’ll learn important data science skills as well as “best practices” for using pandas. Through each exercise, you’ll learn important data science skills as well as “best practices” for using pandas. Table of Contents: ExploratoryDataAnalysis is all about answering a specific question.
Figure 3: The required python libraries The problem presented to us is a predictive analysis problem which means that we will be heavily involved in finding patterns and predictions rather than seeking recommendations. One important stage of any dataanalysis/science project is EDA. ExploratoryDataAnalysis is a pre-study.
This article will guide you through effective strategies to learn Python for Data Science, covering essential resources, libraries, and practical applications to kickstart your journey in this thriving field. Key Takeaways Python’s simplicity makes it ideal for DataAnalysis. in 2022, according to the PYPL Index.
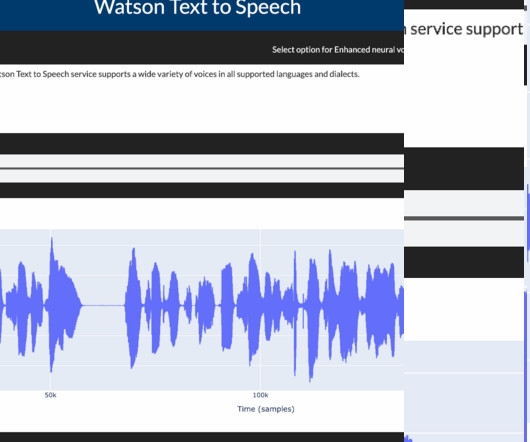
Data Processing and EDA (ExploratoryDataAnalysis) Speech synthesis services require that the data be in a JSON format. TTS app speech data output Conclusion This blog showed how you could easily use the Watson Speech Library to convert text to speech and control digital speech and pitch rates.
Once you have downloaded the dataset, you can upload it to the Watson Studio instance by going to the Assets tab and then dropping the data files as shown below. Add Data You can access the data from the notebook once it has been added to the Watson Studio project. Dataframe head 2.
For access to the data used in this benchmark notebook, sign up for the competition here. KG 2 bfaiol.wav nonword_repetition chav KG 3 ktvyww.wav sentence_repetition ring the bell on the desk to get her attention 2 4 htfbnp.wav blending kite KG We'll join these datasets together to help with our exploratorydataanalysis.
ExploratoryDataAnalysis Next, we will create visualizations to uncover some of the most important information in our data. At the same time, the number of rows decreased slightly to 160,454, a result of duplicate removal.
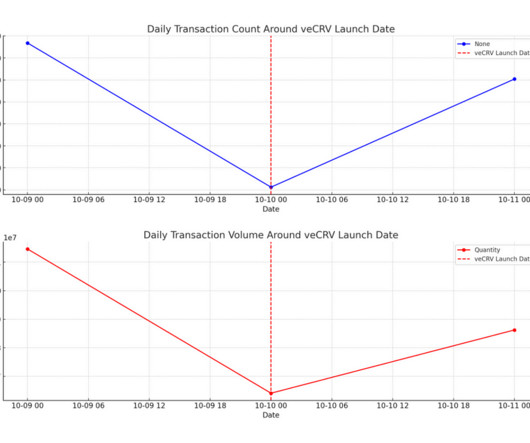
Abstract This research report encapsulates the findings from the Curve Finance Data Challenge , a competition that engaged 34 participants in a comprehensive analysis of the decentralized finance protocol. Part 1: ExploratoryDataAnalysis (EDA) MEV Over 25,000 MEV-related transactions have been executed through Curve.
This report took the data set provided in the challenge, as well as external data feeds and alternative sources. In the link above, you will find great detail in data visualization, script explanation, use of neural networks, and several different iterations of predictive analytics for each category of NFL player.
Objectives The challenge embraced several dataanalysis dimensions: from data cleaning and exploratorydataanalysis (EDA) to insightful data visualization and predictive modeling.
We use this extracted dataset for exploratorydataanalysis and feature engineering. You can choose to sample the data from Snowflake in the SageMaker Data Wrangler UI. Another option is to download complete data for your ML model training use cases using SageMaker Data Wrangler processing jobs.
Those researches are often conducted on easily available benchmark datasets which you can easily download, often with corresponding ground truth data (label data) necessary for training. 7, Dealing with lack of labels in a single domain In many cases, data themselves are easily available, and only annotations costs matter.
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 4 If you went through our previous blog post on Gradient Boosting, it should be fairly easy for you to grasp XGBoost, as XGBoost is heavily based on the original Gradient Boosting algorithm. kaggle/kaggle.json # download the required dataset from kaggle !kaggle
Data Extraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. Data storage : Store the data in a Snowflake data warehouse by creating a data pipe between AWS and Snowflake.
Data Wrangler makes it easy to ingest data and perform data preparation tasks such as exploratorydataanalysis, feature selection, and feature engineering. You can either download the report or view it online. Add transformations to the dataData Wrangler has over 300 built-in transformations.
This is a unique opportunity for data people to dive into real-world data and uncover insights that could shape the future of aviation safety, understanding, airline efficiency, and pilots driving planes. These AI/ML models become invaluable tools for aviation operations and safety by harnessing the extensive historical METAR data.
Reporting Data In this section, we have to download, connect and analyze the data on PowerBI. Therefore, for the sake of brevity, we have to download the file brand_cars_dashboard.pbix from the project’s GitHub repository. Figure 11: Project’s GitHub Now, we have to click on the icon of “download”.
hours of on-demand video 5 coding exercises 40 articles and 9 downloadable resources Full access on mobile and TV Data Science Job Guarantee Program by Pickl.AI This year-long program guarantees a job in Data Science , providing both conceptual knowledge and technical proficiency. Course Content: 42.5
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 2 In the previous blog post of this series, we briefly covered concepts like decision trees and gradient boosting, before touching up on the concept of XGBoost. . Download the code! Looking for the source code to this post?
ExploratoryDataAnalysis This is one of the fun parts because we get to look into and analyze what’s inside the data that we have collected and cleaned. We patch this issue by naming the file by the IP address of the user instead of naming it the same for everyone.)
In this article, let’s dive deep into the Natural Language Toolkit (NLTK) data processing concepts for NLP data. Before building our model, we will also see how we can visualize this data with Kangas as part of exploratorydataanalysis (EDA). A lemma is a word that represents a whole group of words.
Moreover, You can download the chart or list of values of any metric you need from Neptune dashboard. Now, you can visualize the model metrics on the Naptune.ai Source: Author The Neptune dashboard helps you monitor the accuracy, loss, and other hyperparameters.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratorydataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
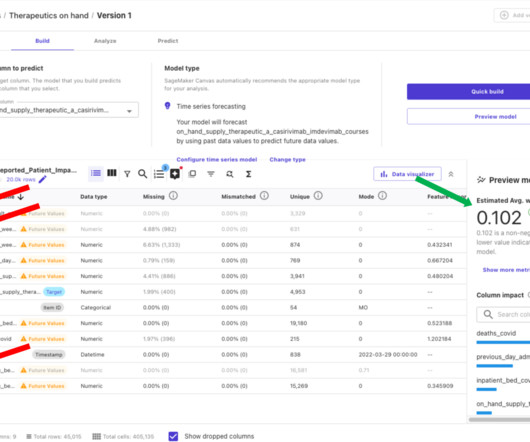
Exploratorydataanalysis After you import your data, Canvas allows you to explore and analyze it, before building predictive models. You can preview your imported data and visualize the distribution of different features. This information can be used to refine your input data and drive more accurate models.
The dataset ( COVID-19 Reported Patient Impact and Hospital Capacity by State Timeseries (RAW) ) is downloadable from healthdata.gov, and has 135 columns and over 60,000 rows. The dataset is updated periodically.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content