This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts.
Introduction Source Sentiment Analysis or opinion mining is the analysis of emotions behind the words by using NaturalLanguageProcessing and Machine Learning. The post Fine-Grained Sentiment Analysis of Smartphone Review appeared first on Analytics Vidhya.
Advantages of t-SNE t-SNE offers several key benefits that make it a preferred choice for certain dataanalysis tasks. Data intuition This technique enhances data understanding and visualization by revealing hidden patterns and relationships, which might not be immediately apparent in high-dimensional space.
The data sets are categorized according to varying difficulty levels to be suitable for everyone. Applications of NaturalLanguageProcessing One of the essential things in the life of a human being is communication. This blog will discuss the different naturallanguageprocessing applications.
The data sets are categorized according to varying difficulty levels to be suitable for everyone. Link to blog -> Fine-tune LLMs Applications of NaturalLanguageProcessing One of the essential things in the life of a human being is communication.
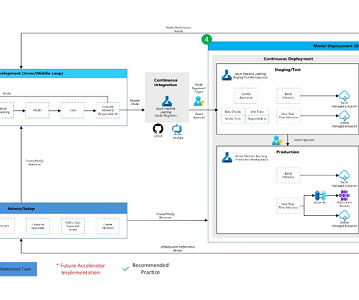
Development to production workflow LLMs Large Language Models (LLMs) represent a novel category of NaturalLanguageProcessing (NLP) models that have significantly surpassed previous benchmarks across a wide spectrum of tasks, including open question-answering, summarization, and the execution of nearly arbitrary instructions.
For academics and domain experts, R is the preferred language. it is overwhelming to learn data science concepts and a general-purpose language like python at the same time. R being a statistical language is an easier option. ExploratoryDataAnalysis. NaturalLanguageProcessing (NLP).
Learn NLP dataprocessing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk Many data we analyze as data scientists consist of a corpus of human-readable text.
However, these early systems were limited in their ability to handle complex language structures and nuances, and they quickly fell out of favor. In the 1980s and 1990s, the field of naturallanguageprocessing (NLP) began to emerge as a distinct area of research within AI.
Because most of the students were unfamiliar with machine learning (ML), they were given a brief tutorial illustrating how to set up an ML pipeline: how to conduct exploratorydataanalysis, feature engineering, model building, and model evaluation, and how to set up inference and monitoring.
Data description: This step includes the following tasks: describe the dataset, including the input features and target feature(s); include summary statistics of the data and counts of any discrete or categorical features, including the target feature.
Learn how Data Scientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of naturallanguageprocessing, modeling, dataanalysis, data cleaning, and data visualization. It also improves dataanalysis.
These packages enable developers to leverage state-of-the-art techniques in areas such as image recognition, naturallanguageprocessing, and reinforcement learning, opening up a wide range of possibilities for solving complex problems. It is commonly used in exploratorydataanalysis and for presenting insights and findings.
Data preprocessing is a fundamental and essential step in the field of sentiment analysis, a prominent branch of naturallanguageprocessing (NLP). It ensures that the data used in analysis or modeling is comprehensive and comprehensive.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences.
ML focuses on enabling computers to learn from data and improve performance over time without explicit programming. Key Components In Data Science, key components include data cleaning, ExploratoryDataAnalysis, and model building using statistical techniques. billion in 2022 to a remarkable USD 484.17
Blind 75 LeetCode Questions - LeetCode Discuss Data Manipulation and Analysis Proficiency in working with data is crucial. This includes skills in data cleaning, preprocessing, transformation, and exploratorydataanalysis (EDA).
Therefore, it mainly deals with unlabelled data. The ability of unsupervised learning to discover similarities and differences in data makes it ideal for conducting exploratorydataanalysis. Instead, it uses the available labeled data to make predictions based on the proximity of data points in the feature space.
Each type employs distinct methodologies for DataAnalysis and decision-making. Key Features No labelled data is required; the model identifies patterns or structures. Typically used for clustering (grouping data into categories) or dimensionality reduction (simplifying data without losing important information).
Dealing with large datasets: With the exponential growth of data in various industries, the ability to handle and extract insights from large datasets has become crucial. Data science equips you with the tools and techniques to manage big data, perform exploratorydataanalysis, and extract meaningful information from complex datasets.
Career Advancement: Professionals can enhance earning potential by acquiring in-demand skills like NaturalLanguageProcessing, Deep Learning, and relevant certifications aligned with industry needs. Geographic Variations: The average salary of a Machine Learning professional in India is ₹12,95,145 per annum.
Scikit-learn: A simple and efficient tool for data mining and dataanalysis, particularly for building and evaluating machine learning models. At the same time, Keras is a high-level neural network API that runs on top of TensorFlow and simplifies the process of building and training deep learning models.
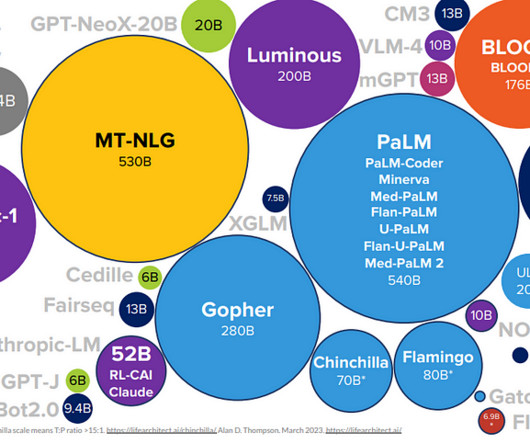
My point is, the more data you have, and the bigger computation resource you have, the better performance you get. In other words, machine learning has scalability with data and parameters. This characteristic is clearly observed in models in naturallanguageprocessing (NLP) and computer vision (CV) like in the graphs below.
Thus, this type of task is very important for exploratorydataanalysis. Local data caching can exist in clustering methodologies by reducing the need for continuous data transmission in order to improve network efficiency and reduce energy consumption (Zhao, et al.,
As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. The programming language can handle Big Data and perform effective dataanalysis and statistical modelling.
NaturalLanguageProcessing (NLP) allows machines to understand and generate human language, enhancing interactions between humans and machines. Focus on exploratoryDataAnalysis and feature engineering. Ideal starting point for aspiring Data Scientists.
The Microsoft Certified: Azure Data Scientist Associate certification is highly recommended, as it focuses on the specific tools and techniques used within Azure. Additionally, enrolling in courses that cover Machine Learning, AI, and DataAnalysis on Azure will further strengthen your expertise.
Prescriptive Analytics Projects: Prescriptive analytics takes predictive analysis a step further by recommending actions to optimize future outcomes. NLP techniques help extract insights, sentiment analysis, and topic modeling from text data. 6. Analyzing Large Datasets: Choose a large dataset from public sources (e.g.,
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use.
Source:datascientist.com Sentiment analysis, commonly referred to as “opinion mining,” is the method of drawing out irrational information from written or spoken words. The study of how people communicate their thoughts, beliefs, and feelings through language is a fast-expanding area of naturallanguageprocessing (NLP).
Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow. A typical workflow is illustrated here from data ingestion, EDA (ExploratoryDataAnalysis), experimentation, model development and evaluation, to the registration of a candidate model for production.
Long Short-Term Memory (LSTM) A type of recurrent neural network (RNN) designed to learn long-term dependencies in sequential data. Facebook Prophet A user-friendly tool that automatically detects seasonality and trends in time series data. Making Data Stationary: Many forecasting models assume stationarity.
Data Cleaning: Raw data often contains errors, inconsistencies, and missing values. Data cleaning identifies and addresses these issues to ensure data quality and integrity. Data Visualisation: Effective communication of insights is crucial in Data Science.
I came up with an idea of a NaturalLanguageProcessing (NLP) AI program that can generate exam questions and choices about Named Entity Recognition (who, what, where, when, why). See the attachment below. A Named Entity Recognition question example from OpExams — Free question generator. The approach was proposed by Yin et al.
His main research interests revolve around applications of Network Analysis and NaturalLanguageProcessing methods. Artem has versatile experience in working with real-life data from different domains and was involved in several data science projects at the World Bank and the University of Oxford.
By implementing a modern naturallanguageprocessing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. Scalable receives hundreds of email inquiries from our clients on a daily basis.
You can also tap into the power of automated machine learning (AutoML) and automatically build custom ML models for regression, classification, time series forecasting, naturallanguageprocessing, and computer vision, supported by Amazon SageMaker Autopilot.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content