This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dreaming of a Data Science career but started as an Analyst? This guide unlocks the path from DataAnalyst to Data Scientist Architect. DataAnalyst to Data Scientist: Level-up Your Data Science Career The ever-evolving field of Data Science is witnessing an explosion of data volume and complexity.
Where exactly within an organization does the primary responsibility lie for ensuring that a datapipeline project generates data of high quality, and who exactly holds that responsibility? Who is accountable for ensuring that the data is accurate? Is it the data engineers? The data scientists?
Automation Automating datapipelines and models ➡️ 6. Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , Data Engineers and DataAnalysts to include in your team? Big Ideas What to look out for in 2022 1.
Data Warehouse. Data Type: Historical which has been structured in order to suit the relational database diagram Purpose: Business decision analytics Users: Business analysts and dataanalysts Tasks: Read-only queries for summarizing and aggregating data Size: Just stores data pertinent to the analysis.
In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a data engineer, you could also build and maintain datapipelines that create an interconnected data ecosystem that makes information available to data scientists. DataAnalyst.
Data is the foundational layer for all generative AI and ML applications. Managing and retrieving the right information can be complex, especially for dataanalysts working with large data lakes and complex SQL queries. The following diagram illustrates the solution architecture.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, data scientist, or dataanalyst. You can watch it on demand here.
By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. The data science lifecycle Data science is iterative, meaning data scientists form hypotheses and experiment to see if a desired outcome can be achieved using available data.
Unfolding the difference between data engineer, data scientist, and dataanalyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Big Data Processing: Apache Hadoop, Apache Spark, etc. Read more to know.
It may conflict with your data governance policy (more on that below), but it may be valuable in establishing a broader view of the data and directing you toward better data sets for your main models. Datapipeline maintenance.
They use their knowledge of data warehousing, data lakes, and big data technologies to build and maintain datapipelines. Datapipelines are a series of steps that take raw data and transform it into a format that can be used by businesses for analysis and decision-making.
Data scientists and data engineers want full control over every aspect of their machine learning solutions and want coding interfaces so that they can use their favorite libraries and languages. At the same time, business and dataanalysts want to access intuitive, point-and-click tools that use automated best practices.
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with dataanalysts and data scientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
JuMa is a service of BMW Group’s AI platform for its dataanalysts, ML engineers, and data scientists that provides a user-friendly workspace with an integrated development environment (IDE). JuMa is now available to all data scientists, ML engineers, and dataanalysts at BMW Group.
It brings together business users, data scientists , dataanalysts, IT, and application developers to fulfill the business need for insights. DataOps then works to continuously improve and adjust data models, visualizations, reports, and dashboards to achieve business goals. Using DataOps to Empower Users.
What is Data Observability? It is the practice of monitoring, tracking, and ensuring data quality, reliability, and performance as it moves through an organization’s datapipelines and systems. Data quality tools help maintain high data quality standards. Tools Used in Data Observability?
In prior blog posts challenges beyond the 3V’s and understanding data , I discussed some issues which hindered the efficiency of dataanalysts besides drastically raising the bar on their motivation to begin working with new data. Here, I want to drill into a few more experiences around use and management of data.
DataAnalyst When people outside of data science think of those who work in data science, the title DataAnalyst is what often comes up. What makes this job title unique is the “Swiss army knife” approach to data. But this doesn’t mean they’re off the hook on other programs.
Automated testing to ensure data quality. There are many inefficiencies that riddle a datapipeline and DataOps aims to deal with that. DataOps encourages better collaboration between data professionals and other IT roles. DataOps makes processes more efficient by automating as much of the datapipeline as possible.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
Over time, we called the “thing” a data catalog , blending the Google-style, AI/ML-based relevancy with more Yahoo-style manual curation and wikis. Thus was born the data catalog. In our early days, “people” largely meant dataanalysts and business analysts. Data engineers want to catalog datapipelines.
Last week, the Alation team had the privilege of joining IT professionals, business leaders, and dataanalysts and scientists for the Modern Data Stack Conference in San Francisco. So, how can a data catalog support the critical project of building datapipelines? Another week, another incredible conference!
This track will focus on AI workflow orchestration, efficient datapipelines, and deploying robust AI solutions. Data Engineering TrackBuild the Data Foundation forAI Data engineering powers every AI system. This track offers practical guidance on building scalable datapipelines and ensuring dataquality.
Assembling the Cross-Functional Team Data science combines specialized technical skills in statistics, coding, and algorithms with softer skills in interpreting noisy data and collaborating across functions. This model gives organizations direct development control but requires significant HR investment.
IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Key Features: Graphical Framework: Allows users to design datapipelines with ease using a graphical user interface. Read More: Advanced SQL Tips and Tricks for DataAnalysts.
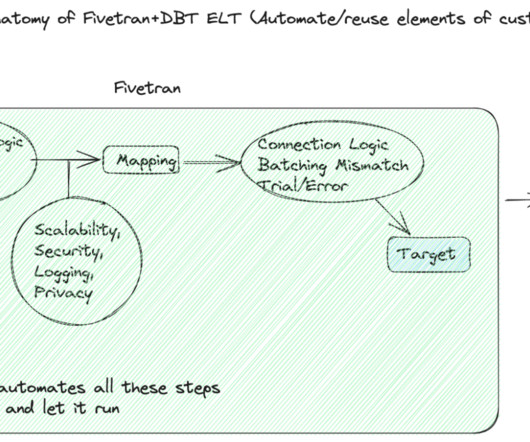
Fivetran also takes care of all the manual elements of building and maintaining a datapipeline that is not business-related so that data teams don’t have to. With dbt, transforming the data according to business logic becomes easy. This is where dbt comes in – powering the transformations.
Supporting the data ecosystem. To maximize the value of organizational data, companies need to reduce the time it takes for data scientists and dataanalysts to find the data they need and put it to use. This significantly limits the time to value of data science and analytics projects.
Access the resources your data applications need — no more, no less. DataPipeline Automation. Consolidate all data sources to automate pipelines for processing in a single repository. Data modernization helps you manage this process intelligently. Advanced Tooling.
Data quality monitoring Maintaining good data quality requires continuous data quality management. Data quality monitoring is the practice of revisiting previously scored datasets and reevaluating them based on the six dimensions of data quality.
While the concept of data mesh as a data architecture model has been around for a while, it was hard to define how to implement it easily and at scale. Two data catalogs went open-source this year, changing how companies manage their datapipeline. The departments closest to data should own it.
Programming Languages: Proficiency in programming languages like Python or R is advantageous for performing advanced data analytics, implementing statistical models, and building datapipelines. Is BI developer same as dataanalyst?
Enhanced Data Warehousing Experience – By automating schema-related tasks, Snowflake contributes to a more seamless and user-friendly data warehousing experience. DataAnalysts and Scientists can focus on analyzing and deriving insights from data rather than dealing with the complexities of schema modifications.
Powered by cloud computing, more data professionals have access to the data, too. Dataanalysts have access to the data warehouse using BI tools like Tableau; data scientists have access to data science tools, such as Dataiku. Better Data Culture. Business analysts. Data scientists.
It seamlessly integrates with IBM’s data integration, data observability, and data virtualization products as well as with other IBM technologies that analysts and data scientists use to create business intelligence reports, conduct analyses and build AI models.
Training and Awareness Educating staff and their implications can foster a culture of data quality and integrity within the organisation. By effectively identifying and addressing anomalies, organisations can enhance data quality, improve decision-making, and maintain operational integrity.
Data Scientists and DataAnalysts have been using ChatGPT for Data Science to generate codes and answers rapidly. Data Manipulation The process through which you can change the data according to your project requirement for further data analysis is known as Data Manipulation.
Data from an ERP or MDM system could come in as raw, with technical names that match the source, and have some limited data definitions but no data quality aspects. The data would also be tagged for data trust, with labels that permit data quality rules to be executed. If so, to what capacity?
To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in datapipelines. This approach eliminates any data duplication or data movement.
For business leaders to make informed decisions, they need high-quality data. Unfortunately, most organizations – across all industries – have Data Quality problems that are directly impacting their company’s performance.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
Other users Some other users you may encounter include: Data engineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and dataanalysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate.
Roles of data professionals Various professionals contribute to the data science ecosystem. Data scientists are the primary practitioners, employing methodologies to extract insights from complex datasets. Data science team composition A well-rounded data science team comprises various roles that contribute to its success.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content