This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, dataclassification software, optical character recognition (OCR), document fingerprinting, and encryption.
Summary: Feeling overwhelmed by your data? Dataclassification is the key to organization and security. This blog explores what dataclassification is, its benefits, and different approaches to categorize your information. Discover how to protect sensitive data, ensure compliance, and streamline data management.
Dataclassification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. FMs are transforming the way you can solve traditionally complex document processing workloads.
Data archiving is the systematic process of securely storing and preserving electronic data, including documents, images, videos, and other digital content, for long-term retention and easy retrieval. Lastly, data archiving allows organizations to preserve historical records and documents for future reference.
The type of security analysis performed against the transcripts will vary depending on factors like the dataclassification or criticality of the server the recording was taken from. For example, the use of shortcut keys like Ctrl + S to save a document cant be detected from an image of the console. Here are the two documents.
For instance, according to International Data Corporation (IDC), the world’s data volume is expected to increase tenfold by 2025, with unstructured data accounting for a significant portion. The metadata generated can be customized during the ingestion process with Amazon Kendra Custom Document Enrichment (CDE) custom logic.
Legal professionals often spend a significant portion of their work searching through and analyzing large documents to draw insights, prepare arguments, create drafts, and compare documents. There are other components involved, such as knowledge bases, data stores, and document repositories.
Even though evaluations are guided by the UNDP Evaluation Guideline, there is no standard written format for these evaluations, and the aforementioned sections may occur at different locations in the document, or not all of them may exist. Amazon Textract is used to extract data from PDF documents.
An intelligent document processing (IDP) project typically combines optical character recognition (OCR) and natural language processing (NLP) to automatically read and understand documents. Use the right technology to store data For IDP workflows, most of the data is likely to be documents.
Organizations must address security issues in cloud computing to safeguard their assets Vulnerable gateways Cloud Service Providers (CSPs) typically offer a range of application programming interfaces (APIs) and customer interfaces, which are extensively documented to enhance their usability.
When given a query like “classify brain tumor,” the vector database can search for documents or phrases that have similar meanings to the query. It achieves this by comparing the vector representation of the query with the vectors of the stored documents, which encompass past experiences and accumulated knowledge.
The goal of unsupervised learning is to identify structures in the data, such as clusters, dimensions, or anomalies, without prior knowledge of the expected output. This can be useful for discovering hidden patterns, identifying outliers, and reducing the complexity of high-dimensional data.
Data protection policies and procedures Data protection policies help organizations outline their approach to data security and data privacy. Additionally, some data protection laws and regulations require them.
Foundation models can be trained to perform tasks such as dataclassification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy.
Classification algorithms —predict categorical output variables (e.g., “junk” or “not junk”) by labeling pieces of input data. Classification algorithms include logistic regression, k-nearest neighbors and support vector machines (SVMs), among others.
This is caused by: Multiple first-mile reviews to ensure no adverse business impacts, including privacy concerns, dataclassification, business continuity and regulatory compliance (and most of these are manual).
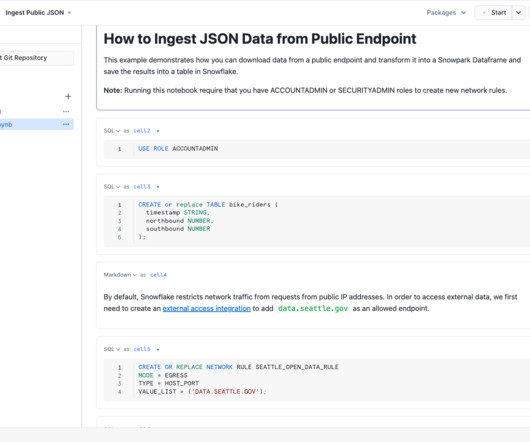
Cortex Search : This feature provides a search solution that Snowflake fully manages from data ingestion, embedding, retrieval, reranking, and generation. Use cases for this feature include needle-in-a-haystack lookups and multi-document synthesis and reasoning. FAQs How can I stay informed about the release of all upcoming features?
“Time is money,” said Leonard Kwok, Senior Data Analyst, ARC. “The quicker we can fix data, the sooner we can deliver to customers on time. Manual lineage gives us a quick and easy way to documentdata relationships and trace where it came from. Dataclassification via tags is a simple yet powerful capability.
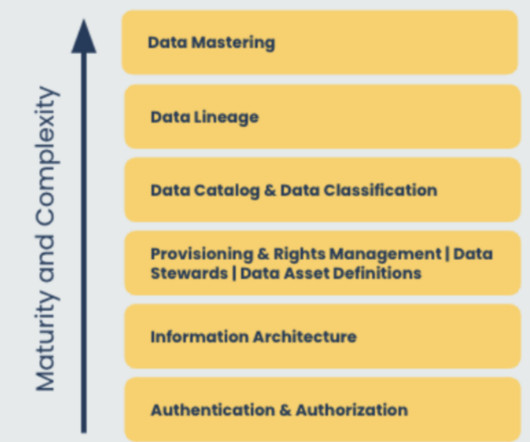
What is the language that users throughout your organization use to describe the data they work with every day? Dataclassification and retention policies: Data may be classified in many ways based on both internal and external policies. These can further drive usage rights, disclosure, and disclaimers.
The benefit of having a smaller number of larger projects is you’ll unlock a complete view of model lineage and have richer documentation across functional areas. These projects should include all functional areas within the data platform including analytics engineering, machine learning , and data science.
Align your data strategy to a go-forward architecture, with considerations for existing technology investments, governance and autonomous management built in. Look to AI to help automate tasks such as data onboarding, dataclassification, organization and tagging.
Best practices for proactive data security Best cybersecurity practices mean ensuring your information security in many and varied ways and from many angles. Here are some data security measures that every organization should strongly consider implementing. Define sensitive data. Establish a cybersecurity policy.
Dataclassification is necessary for leveraging data effectively and efficiently. Effective dataclassification helps mitigate risk, maintain governance and compliance, improve efficiencies, and help businesses understand and better use data. Manual DataClassification. Labeling the asset.
Dataclassification is a critical aspect of data management that not only enhances efficiency but also strengthens security protocols. As businesses increasingly depend on data, having a structured approach to handling this information becomes essential. What is dataclassification?
Video of the Week: Automated DataClassification In this video, Alex Gorelik will be discussing automated dataclassification. You can find the schedule here on our website, but be sure to read on for a breakdown of what you can expect from each day.
Data as the foundation of what the business does is great – but how do you support that? What technology or platform can meet the needs of the business, from basic report creation to complex document analysis to machine learning workflows? The Snowflake AI Data Cloud is the platform that will support that and much more!
For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold. Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content