This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
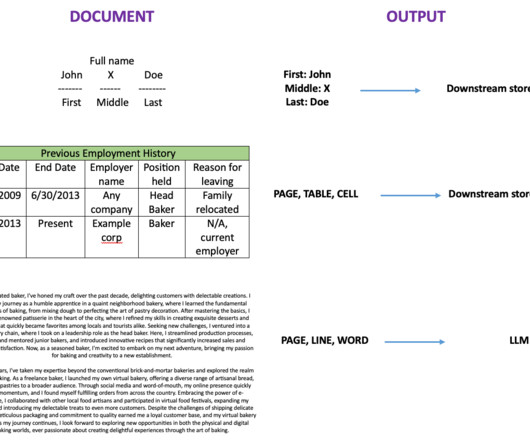
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, dataclassification software, optical character recognition (OCR), document fingerprinting, and encryption.
They investigate the most suitable algorithms, identify the best weights and hyperparameters, and might even collaborate with fellow data scientists in the community to develop an effective strategy. This is where ML CoPilot enters the scene. Vector databases can store them and are designed for search and data mining.
Dataclassification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. Generative AI is driven by large ML models called foundation models (FMs).
Dataclassification is necessary for leveraging data effectively and efficiently. Effective dataclassification helps mitigate risk, maintain governance and compliance, improve efficiencies, and help businesses understand and better use data. Manual DataClassification. Labeling the asset.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
Legal professionals often spend a significant portion of their work searching through and analyzing large documents to draw insights, prepare arguments, create drafts, and compare documents. AWS AI and machine learning (ML) services help address these concerns within the industry.
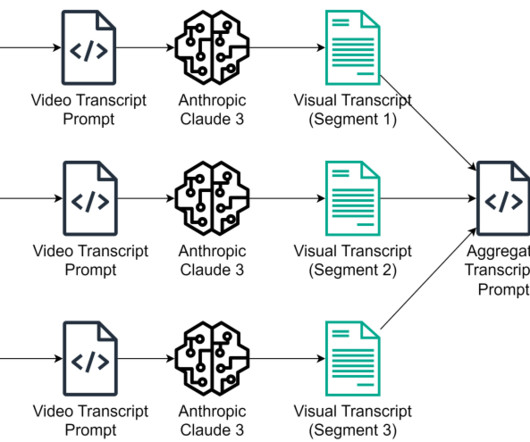
These services use advanced machine learning (ML) algorithms and computer vision techniques to perform functions like object detection and tracking, activity recognition, and text and audio recognition. For example, the use of shortcut keys like Ctrl + S to save a document cant be detected from an image of the console.
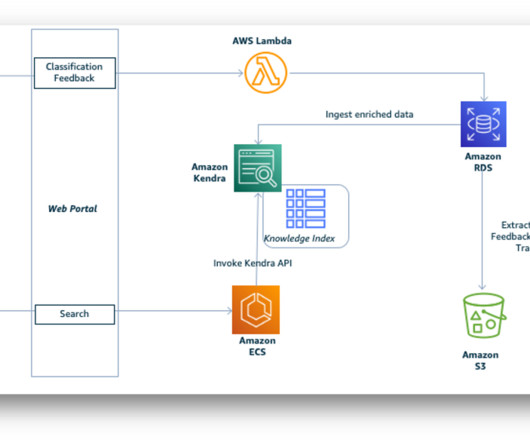
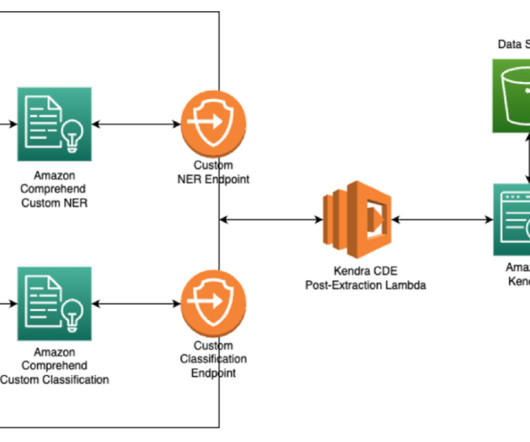
For instance, according to International Data Corporation (IDC), the world’s data volume is expected to increase tenfold by 2025, with unstructured data accounting for a significant portion. The metadata generated can be customized during the ingestion process with Amazon Kendra Custom Document Enrichment (CDE) custom logic.
An intelligent document processing (IDP) project typically combines optical character recognition (OCR) and natural language processing (NLP) to automatically read and understand documents. Use the right technology to store data For IDP workflows, most of the data is likely to be documents.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI Learn more about Cleanlab, an open-source software library that can help with fixing and cleaning machine learning datasets with ease. You can find the schedule here on our website, but be sure to read on for a breakdown of what you can expect from each day.
Cortex Search : This feature provides a search solution that Snowflake fully manages from data ingestion, embedding, retrieval, reranking, and generation. Use cases for this feature include needle-in-a-haystack lookups and multi-document synthesis and reasoning. FAQs How can I stay informed about the release of all upcoming features?
Align your data strategy to a go-forward architecture, with considerations for existing technology investments, governance and autonomous management built in. Look to AI to help automate tasks such as data onboarding, dataclassification, organization and tagging.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This use case, solvable through ML, can enable support teams to better understand customer needs and optimize response strategies.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content