This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
So much of data science and machinelearning is founded on having clean and well-understood data sources that it is unsurprising that the data labeling market is growing faster than ever.
So much of data science and machinelearning is founded on having clean and well-understood data sources that it is unsurprising that the data labeling market is growing faster than ever.
Classification in machinelearning involves the intriguing process of assigning labels to new data based on patterns learned from training examples. Machinelearning models have already started to take up a lot of space in our lives, even if we are not consciously aware of it.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
Artificial intelligence (AI) can be used to automate and optimize the data archiving process. There are several ways to use AI for data archiving. Traditional data compression methods often rely on rules-based algorithms that identify and remove obvious duplicates or redundancies.
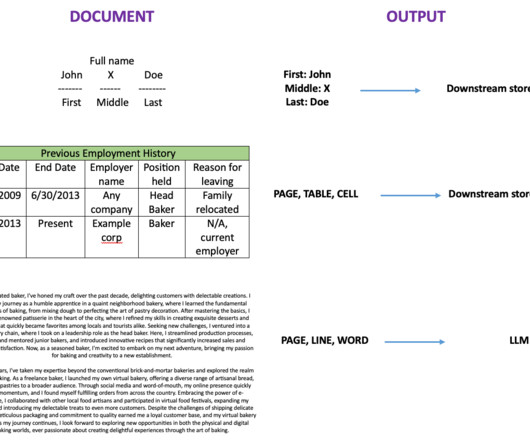
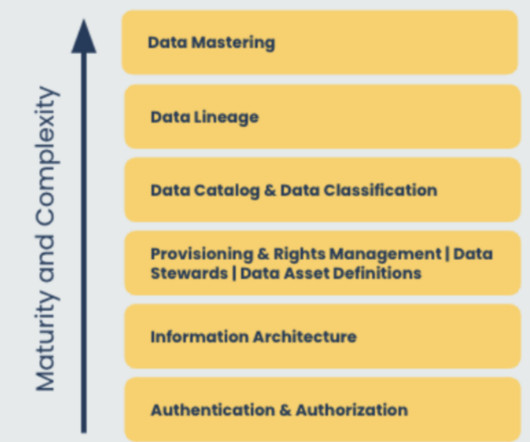
Dataclassification is necessary for leveraging data effectively and efficiently. Effective dataclassification helps mitigate risk, maintain governance and compliance, improve efficiencies, and help businesses understand and better use data. Manual DataClassification. Labeling the asset.
The business’s solution makes use of AI to continually monitor personnel and deliver event-driven security awareness training in order to prevent data theft. Employees are regularly monitored by the tool, which also alerts them to any possible data breaches.
Predictive modeling plays a crucial role in transforming vast amounts of data into actionable insights, paving the way for improved decision-making across industries. By leveraging statistical techniques and machinelearning, organizations can forecast future trends based on historical data.
How to Use MachineLearning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machinelearning were introduced.
These services use advanced machinelearning (ML) algorithms and computer vision techniques to perform functions like object detection and tracking, activity recognition, and text and audio recognition. He has helped multiple enterprises harness the power of AI and machinelearning on AWS.
Solving MachineLearning Tasks with MLCoPilot: Harnessing Human Expertise for Success Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machinelearning code. Vector databases can store them and are designed for search and data mining.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machinelearning (ML), metadata analysis, dataclassification software, optical character recognition (OCR), document fingerprinting, and encryption.
It’s the underlying engine that gives generative models the enhanced reasoning and deep learning capabilities that traditional machinelearning models lack. That’s where the foundation model enters the picture. The platform comprises three powerful products: The watsonx.ai
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machinelearning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI Learn more about Cleanlab, an open-source software library that can help with fixing and cleaning machinelearning datasets with ease. Register now for 40% off.
Enter the Era of Generative AI With Google Cloud Google Cloud has recently unveiled its latest generative AI capabilities. The latest tools will make it easier than ever for enterprises to develop and deploy advanced AI applications.
Advancements in AI and natural language processing (NLP) show promise to help lawyers with their work, but the legal industry also has valid questions around the accuracy and costs of these new techniques, as well as how customer data will be kept private and secure.
Customers can create the custom metadata using Amazon Comprehend , a natural-language processing (NLP) service managed by AWS to extract insights about the content of documents, and ingest it into Amazon Kendra along with their data into the index. In Amazon Kendra, facets are scoped views of a set of search results.
Introduction Artificial Neural Network (ANNs) have emerged as a cornerstone of Artificial Intelligence and MachineLearning , revolutionising how computers process information and learn from data. Similarly, in healthcare, ANNs can predict patient outcomes based on historical medical data.
Dataclassification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Features such as normalizing key fields and summarizing input data support faster cycles for managing document process workflows, while reducing the potential for errors.
The Five Pain Points of Moving Data to the Cloud. Dataclassification presents challenges when moving environments. Data governance is hard, especially when building trust and quality. Whether you’re DevOps or machine-learning oriented, Ibby recommends that a little of your own exploration can go a long way.
Summary: A perceptron is the simplest form of an artificial neural network, designed to classify input data into two categories. Perceptrons are foundational in MachineLearning, paving the way for more complex models. Key Takeaways A Perceptron mimics biological neurons for dataclassification. Colour Weight = 1.0
We can also use a box plot to demonstrate the data distribution of features such as ‘area_mean’ and ‘radius_mean’ from individuals whose nuclei mass was malignant or benign. This is a data normalization technique that is commonly used in machinelearning to scale the features of a dataset to a specified range. symmetry j.
Do we know the business outcomes tied to data risk management? These questions drive classification. Once you have dataclassification then you can talk about whether you need to tokenize and why, or anonymize and why, or encrypt and why, etc.” “What am I required to do? What do we know? They drive labeling.
Data Integration A data pipeline can be used to gather data from various disparate sources in one data store. This makes it easier to compare and contrast information and provides organizations with a unified view of their data.
By storing less volatile data on technologies designed for efficient long-term storage, you can optimize your storage footprint. For archiving data or storing data that changes slowly, Amazon S3 Glacier and Amazon S3 Glacier Deep Archive are available.
Masked data provides a cost-effective way to help test if a system or design will perform as expected in real-life scenarios. As the insurance industry continues to generate a wider range and volume of data, it becomes more challenging to manage dataclassification.
These techniques utilize various machinelearning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
These projects should include all functional areas within the data platform including analytics engineering, machinelearning , and data science. Data governance and dataclassification are potential reasons to separate projects in dbt Cloud.
A tall order, but Anthony and his team had a plan: build a data governance foundation. This entailed surveying the data ecosystem of the entire organization and creating dataclassification, retention, and quality standards, including data certification. Governance is embedded at every step.
Data Integration A data pipeline can be used to gather data from various disparate sources in one data store. This makes it easier to compare and contrast information and provides organizations with a unified view of their data.
So how does data intelligence support governance? Examples of governance features that leverage data intelligence include: A business glossary, with automated dataclassification, to align teams on key terms. Data lineage tracking and impact analysis reports to show transformation over time. Again, metadata is key.
Data as the foundation of what the business does is great – but how do you support that? What technology or platform can meet the needs of the business, from basic report creation to complex document analysis to machinelearning workflows? The Snowflake AI Data Cloud is the platform that will support that and much more!
Global policies such as data dictionaries ( business glossaries ), dataclassification tags, and additional information with metadata forms can be created by the governance team to ensure standardization and consistency within the organization. He loves spending time with his family and friends.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machinelearning (ML) models in a cost-sensitive environment. From a development background, he specializes in machinelearning and sustainability. Ramu Ponugumati is a Sr.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










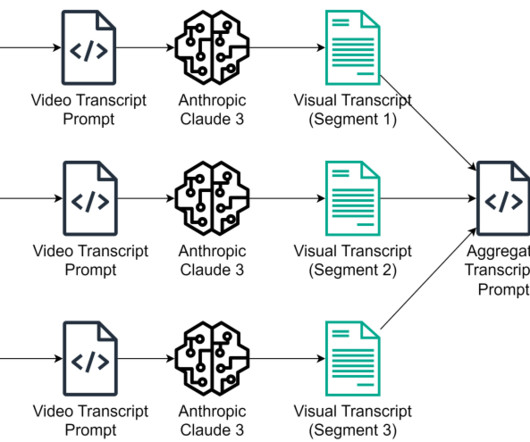



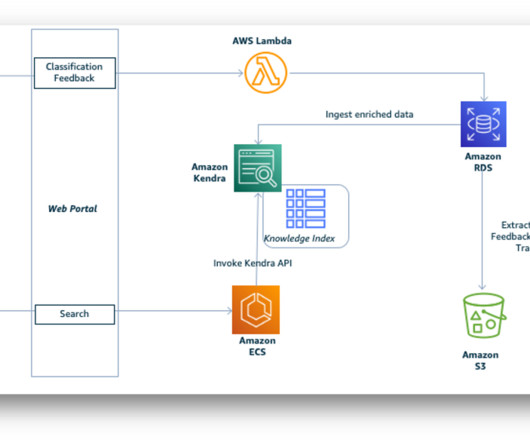


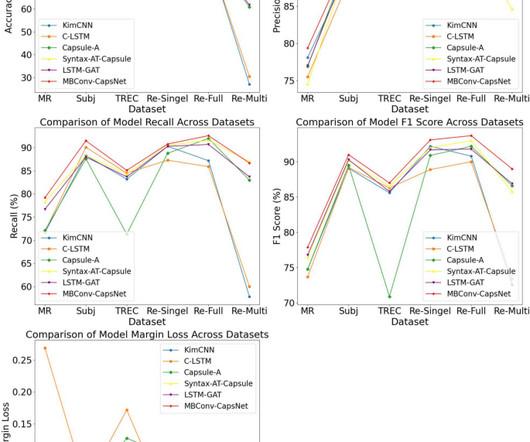

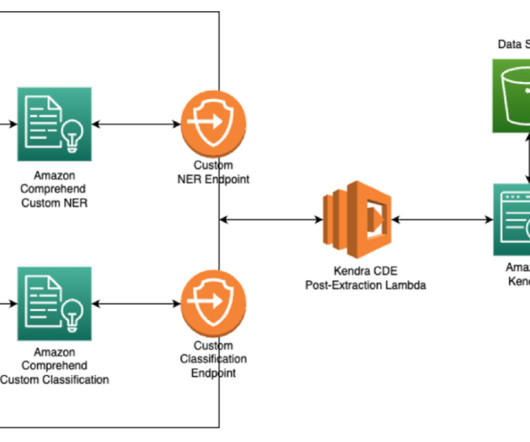




















Let's personalize your content