This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
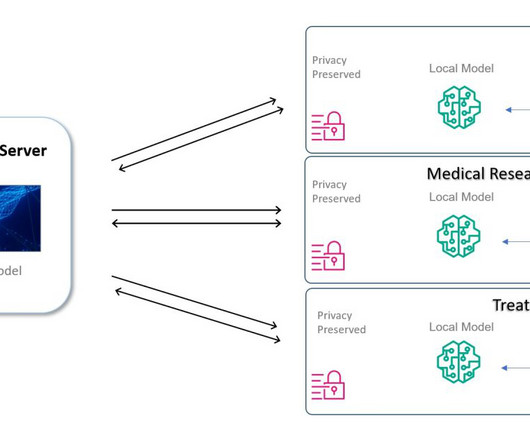
The data management services function is organized through the data lake accounts (producers) and data science team accounts (consumers). The data lake accounts are responsible for storing and managing the enterprise’s raw, curated, and aggregated datasets.
Dataengineering in healthcare is taking a giant leap forward with rapid industrial development. However, data collection and analysis have been commonplace in the healthcare sector for ages. DataEngineering in day-to-day hospital administration can help with better decision-making and patient diagnosis/prognosis.
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates datasilos and provides a unified storage system, simplifying data access and retrieval. This open format allows for seamless storage and retrieval of data across different databases.
The data universe is expected to grow exponentially with data rapidly propagating on-premises and across clouds, applications and locations with compromised quality. This situation will exacerbate datasilos, increase pressure to manage cloud costs efficiently and complicate governance of AI and data workloads.
This article was published as a part of the Data Science Blogathon. Introduction A data lake is a central data repository that allows us to store all of our structured and unstructured data on a large scale.
Duration of data informs on long-term variations and patterns in the dataset that would otherwise go undetected and lead to biased and ill-informed predictions. Breaking down these datasilos to unite the untapped potential of the scattered data can save and transform many lives. Much of this work comes down to the data.”
According to International Data Corporation (IDC), stored data is set to increase by 250% by 2025 , with data rapidly propagating on-premises and across clouds, applications and locations with compromised quality. This situation will exacerbate datasilos, increase costs and complicate the governance of AI and data workloads.
A data mesh is a decentralized approach to data architecture that’s been gaining traction as a solution to the challenges posed by large and complex data ecosystems. It’s all about breaking down datasilos, empowering domain teams to take ownership of their data, and fostering a culture of data collaboration.
The use of RStudio on SageMaker and Amazon Redshift can be helpful for efficiently performing analysis on large data sets in the cloud. However, working with data in the cloud can present challenges, such as the need to remove organizational datasilos, maintain security and compliance, and reduce complexity by standardizing tooling.
Additionally, adding more single-purpose or fit-for-purpose databases to expand functionality can create datasilos and amplify data management problems. Building in these characteristics at a later stage can be costly and resource-intensive.
This means that customers can easily create secure and scalable Hadoop-based data lakes that can quickly process large amounts of data with simplicity and data security in mind. Snowflake Snowflake is a cross-cloud platform that looks to break down datasilos. So, what are you waiting for?
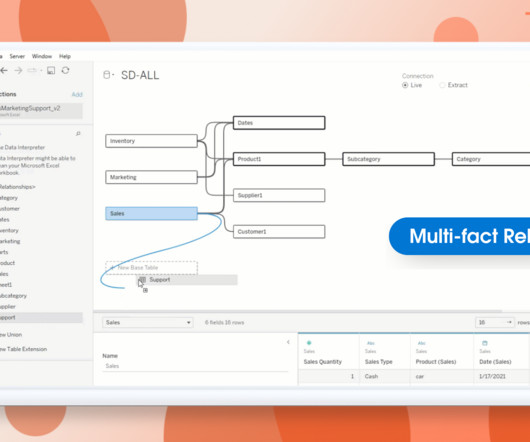
This data model enables you to explore correlations and answer more sophisticated analytical questions, such as how Marketing spend affects Sales, or how Spend actuals are tracking against Budget forecasts. The base tables are not directly related to each other and shown with a thin box outline.
By leveraging cloud-based data platforms such as Snowflake Data Cloud , these commercial banks can aggregate and curate their data to understand individual customer preferences and offer relevant and personalized products.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized dataengineers understood, resulting in an under-realized positive impact on the business.
Assess the current state of your data With your use cases in mind, you then need to assess your data’s completeness, quality, and governance. Ask yourself questions like: Does our data have proper governance and quality controls? Is it contextualized with necessary third-party data?
Insurance companies often face challenges with datasilos and inconsistencies among their legacy systems. To address these issues, they need a centralized and integrated data platform that serves as a single source of truth, preferably with strong data governance capabilities.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of datasilos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Mind the (Data Accessibility) Gap. Data is more accessible than ever. Although we don’t live in a perfect data world, data teams throughout nearly every industry have made progress breaking down datasilos and moving data to the cloud to take advantage of new capabilities.
One data catalog supports a broader organizational ability to collaborate (and innovate) across user types, use cases, and business units. Not only do such products create datasilos – they perpetuate a broken social system that excludes key stakeholders. This the value of one catalog for many use cases.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. Before delving into the technical details, let’s review some fundamental concepts.
Marketing Targeted Campaigns Increases campaign effectiveness and ROI Datasilos leading to inconsistent information. Implementing integrated data management systems. DataEngineer Builds and manages the infrastructure for collecting, storing, and analysing large volumes of data.
If a new, game-changing customer data technology comes along next year, you can easily incorporate it into your composable stack. Building a composable CDP requires some serious dataengineering chops. Implementing this approach requires some serious dataengineering chops.
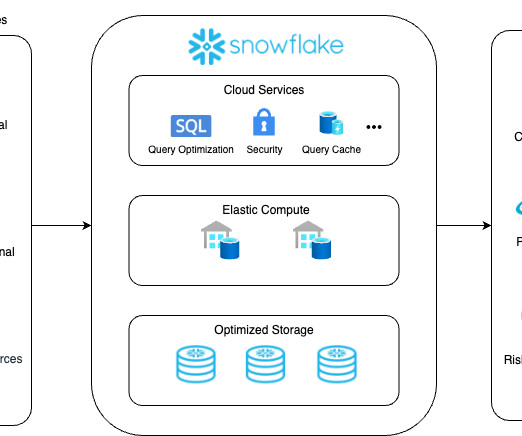
The primary objective of this idea is to democratize data and make it transparent by breaking down datasilos that cause friction when solving business problems. What Components Make up the Snowflake Data Cloud?
However, building data-driven applications can be challenging. It often requires multiple teams working together and integrating various data sources, tools, and services. For example, creating a targeted marketing app involves dataengineers, data scientists, and business analysts using different systems and tools.
I love how data can tell a story, challenge assumptions, and optimize decision-making. Over time, I saw the immense potential of data-driven insights, which led me into dataengineering and AI/ML. In 2021, I took the leap and founded Data Surge , a data and AI/ML services company.
One may define enterprise data analytics as the ability to find, understand, analyze, and trust data to drive strategy and decision-making. Enterprise data analytics integrates data, business, and analytics disciplines, including: Data management. Dataengineering. Business strategy. DataOps. …
To take advantage of a data cloud like Snowflake, you need a way to move your data into it. This is where a data integration platform like Fivetran comes into play.
With a centralized data lake, organizations can avoid the duplication of data across separate trial databases. This leads to savings in storage costs and computing resources, as well as a reduction in the environmental impact of maintaining multiple datasilos.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content